
When it comes to technical interviews, you're going to want to know Arrays and Hash Tables as they're common to show up in your interview.
Different languages has different implementations of Hash Tables or they have data structures which are similar to Hash Tables. In Python, they're dictionaries. In JavaScript, you have Objects, within Java you have Maps, and in C# you can simply create a new Hash Table using new HashTable().
Hash Tables are an extremely useful data structure which allow you to store information using key-value pairs. Very similar to a dictionary or an object that you find in JavaScript.
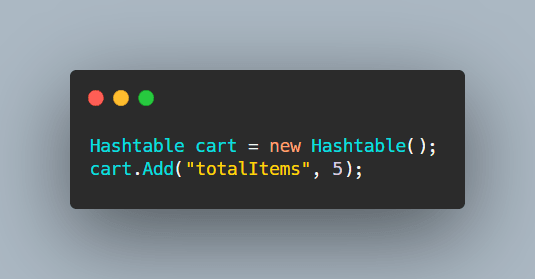
In this example, using C#... I created a new Hash Table and added a key, "totalItems", which has a value of 5. Right away, we see some benefits here. Extremely fast lookup, O(1). To find how many total items my cart has, all I would need to do is a look up using the key to get my value.

This is convenient because if I used an Array, I'd need to do some sort of O(n) lookup. But even then, I'm not sure how I would describe that the value at index n, relates to the total items in my cart. So a Hash Table provides us the ability to quickly look up a value using a key and we're able to understand the relationship between the key and value based on the naming of the key. In this example, "totalItems", the key, is used as an index to find the value in memory.
In a Hash Table, memory isn't zero-indexed based like an Array. The key-value pair is stored in random memory addresses. Now you might be asking, "How does a Hash Table determine where in memory key:totalItems and it's value live?". That's a great question and to answer that we have to talk about a Hash Function.

This is a black-box example of what a Hash Function does. It takes in the key value, in this example, "totalItems" and within a bucket, allocates at a random memory location the value of the key.
A Hash Function isn't something that's only specific to Hash Tables. Hash Functions are used in message digest, password verification, cryptography, and more. All a Hash Function is, is something that generates a value of fixed length for each input that it gets. We give it an input and the function generates a random pattern.
Let's take an md5 hash generator for example. I'm using https://www.md5hashgenerator.com/ for instance. And I enter in the string input, totalItems. The Hash Function then uses an MD5 hash to generate a random pattern and gives me the following hash: 3568acf60dc232a1e15412f1add7ed66
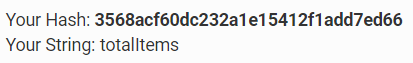
Some things to consider is that a Hash is typically one way. Given a Hash you usually don't find out the input. And no matter how many times I run "totalItems" into the MD5 hash function, I'm always going to get 3568acf60dc232a1e15412f1add7ed66. One hash per input. It I edit the key in any way, let's say my new key name is "totalItem" then the hash changes completely. This is the new hash:

Even if I make a tiny change to the input such as capitalizing a letter or removing a letter, once run through the Hash Function would input an entirely new Hash for the input.
A hash function is idempotent which is a fancy term for meaning a function, given an input, always outputs the same output. This is important because we want to make sure that we're retrieving a key's correct value whenever we use the key in a Hash Table.
Remember earlier that I said the value for the key "totalItems" was 5. I should expect to receive the value, 5, every time I use the key, "totalItems" in the Hash Table. This is why a Hash Function being idempotent is important. Since ultimately, we use the hash to find where in memory the correct value for the key is.
Depending on the hashing function, it may be faster or slower. But typically a Hash Function is O(1).
One problem that occurs when using Hash Tables is Hash Collisions. Which is when the Hash Function assigns multiple one or more keys to the same bucket. There's nothing telling the Hash Function to evenly distribute or check that something exists in a bucket before giving a key a space in memory. With enough data and limited memory, Hash tables are always going to run into hash collisions eventually.
One way to deal with Hash Collisions is by using Linked Lists (Separate Chaining) and other methods but I won't be going into those. Consider checking out https://en.wikipedia.org/wiki/Hash_table#Collision_resolution to learn more about the various ways to resolve Hash Collisions. Due to Hash Collisions, occasionally, lookup may become O(n) instead of O(1).
I'm unable to upload my gif, but if you visit: https://i.imgur.com/C7uEpIU.gifv notice what happens to 24 at index 11, when 232 was added? A collision occurred. And using separate chaining, 232 took 24's original spot but there's a Linked List connection to 24. So 24 is never actually gone.
You can play around with: https://www.cs.usfca.edu/~galles/visualization/OpenHash.html to see Hash Collisions yourself.
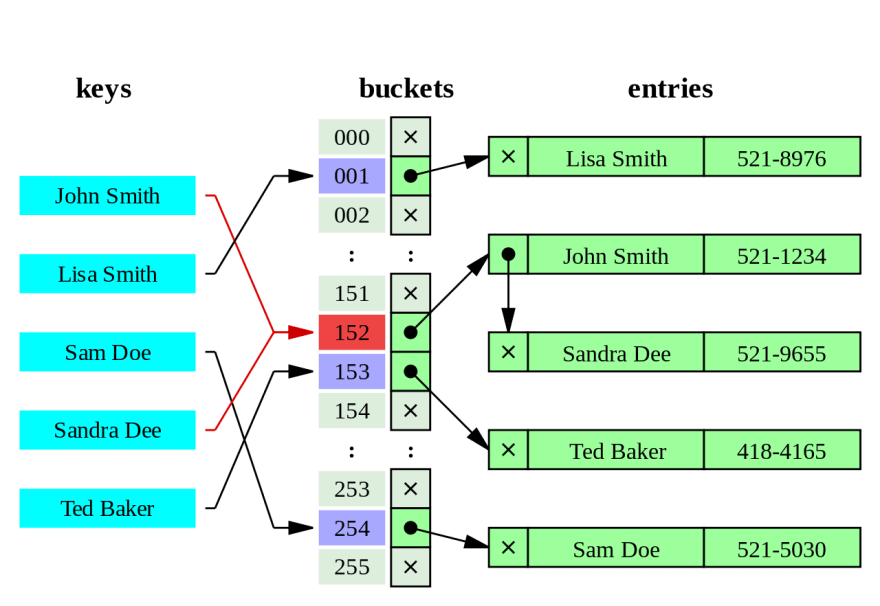
By Jorge Stolfi - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=6471915
As you can see in this image, there's a hash collision that occurs at bucket # 1. Sandra Dee and John Smith share the same bucket. This is resolved using separate chaining.
Ending this article, Hash Tables have a fast lookup, fast inserts, fast deletions, and flexible keys. But they're unordered, have slow key iteration, and you need to be careful about Hash Map collisions. They're an important and useful data structures which are commonly used in technical interviews.
I hope this article has helped out out a little bit. I don't want this article to be an end-all to your studying and highly recommend checking out other resources to aid you in your data structures and algorithms studying.
This article was made for a group that I organized, "Data Structures and Algorithms". If you're interested in study/practicing data structures and algorithms... consider joining us at https://www.meetup.com/Study-Data-Structures-and-Algorithms/ we're in the Greater Seattle Area and have met up once every single week, usually Tuesdays or Thursdays. We're almost at 100 members, if you're interested, come join us and have a great time meeting others and studying together.
We're always looking for people to help volunteer their time and lead events. If you're interested, messages are always welcome.
Thank you.
Other resources that you may find helpful:
᛫ https://bit.ly/2ZHWDmi [ELI5: Hash Tables and their importance]
᛫ https://bit.ly/3f6bYnb [The Codeless Guide to Hashing and Hash Tables]
᛫ https://bit.ly/31SgXnE [Data Structures: Hash Tables Youtube Video]
᛫ https://bit.ly/3iFYn8q [(This link opens a PDF in your browser) A lecture from University of Washington, relevant information about Hash Table starts at slide 12 and up.]

Top comments (0)