This version brings a lot of new features and improvements to Pezzo. We're excited to share them with you!

What's Pezzo?
Pezzo is a fully open-source (Apache 2.0) LLMOps platform built for developers and teams. It was designed to streamline Generative AI adoption, delivery, monitoring, observability and more.
Wanna know more? Check Pezzo out on GitHub.
What's New
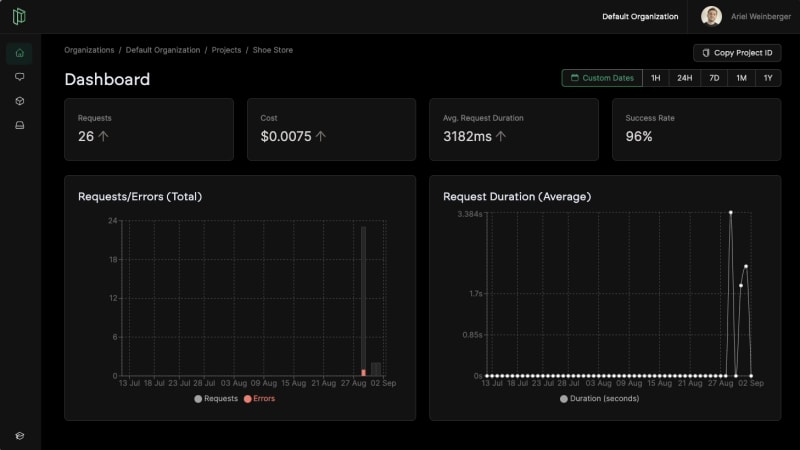
📈 Project Dashboard
We've added a new screen to the Pezzo Console. The Project Dashboard gives you a quick overview of your project's performance. It features several useful features:
Timeframe Selector: Select from hourly, daily, weekly, monthly, yearly and even custom timeframes for analytics.
Vital Metrics: You can now see the number of requests, cost, average request duration, and success rate. You can even see how they change over time.
Useful Charts: We've implemened two charts -one for total requests (as well as errors) and average request duration over time. We'll add more charts in the future.
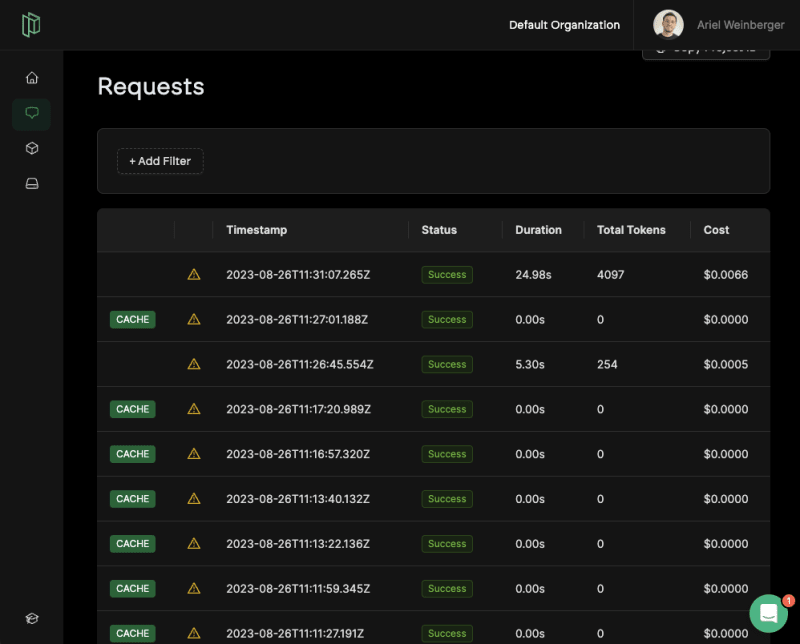
🏎️ Request Caching
We've implementing a caching mechanism. This feature can help you save up to 90% of your LLM API costs and time!
Some practical use cases:
Development: During development developers tend to go through flows very frequently. This usually involves the same set of LLM API calls with the same input date. With Pezzo, your entire organization can share the same cache, and focus on value!
Production: If you're building a support chabot, for example, there are many queries that are highly repetitive. For example, "What is your return policy?" or "What are your opening hours?"
You can read more in the Request Caching documentation.
We're planning to add more caching features in the future, such as semantic caching.
🐍 Python Client
We're excited to share that Pezzo now features a Pezzo client! Here are some useful links to help you get started:
We've also made sure to add a Python copy-pastable code snippet in he console, to make it even easier for you to get started.
Thank you!
We hope you enjoy this version. We're working hard on the next one, which will feature a lot of exciting features and improvements.
- ⭐️ Consider giving us a star on GitHub to support our mission
- 👾 Consider joining our Discord server
- 🎓 Read the documentation
- 🌎 Check out our website

Top comments (0)