
Hi there,
I am currently studying machine learning with fast.ai. This is the second lesson!
I organized my notes in 4 categories: RMSE & R², decision tree, bag of little boostraps, hyperparameters tuning. The best way to learn is to be able to reexplain all of this and to apply this new knowledge to Kaggle competitions.
1. RMSE & R²
RMSE = standard deviation of residuals.
A residual is the difference between the actual data and the data predicted. It is in yellow in the figure below. Each residual is squared, it makes the impact of outliers stronger and it prevents negative and positive residuals to cancel themselves.
R² measures how much the model can explain data compared to the simple mean.


SSres is the sum of squares of residuals, they are represented in yellow in the figure above. SStot is the total sum of square proportional to the variance of the data, they are represented as the sum of the yellow and purple part in the figure above.
When SSres are as big as SStot ( R² close to 0), it means that the model is not better than the simple mean for predictions.
R² is the ratio between how good your model is versus how good is the naïve mean model.
2. A simple decision tree

A tree consists of a sequence of binary decisions.
The algorithm calculates for each variable (Coupler_System, Enclosure, etc), for each possible value of this variable (<0.1, <0.2, etc) the weighted average of two new nodes (here for the first split 16815 x 0.414 + 3185 x 0.109). It keeps the variable and value of the best score.
3. Bag of little bootstraps
To improve a simple decision tree, we can create a forest, that uses a statistical technique called bagging. The key is to construct multiple models which are better than nothing on different subsets of data and where the errors are, as much as possible, not correlate with each other.
When the average of these models is taken, the accuracy is better than the accuracy of a simple decision tree.
A bootstrap is a random subset of the original data, sometimes drawn with replacement. Some samples may occur several times in each splits. The idea is that a bootstrap contains only a part of the whole set of observations. Bootstrap is used to train a different classifier each time on a different set of observations.
The part not used forms the out-of-bag and can be used to assess the error rate of the classifier. Set oob_score=True will create an attribute called oob_score_ to the model. It is very useful for hyperparameters tuning. In this case, a validation set is not needed.

In scikit-learn, there is another class called ExtraTreeClassifier which is an extremely randomized tree model. Rather than trying every split of every variable, it randomly tries a few splits of a few variables which makes training much faster and it can build more trees — better generalization.
👉 Tips: start with 20 or 30 trees and later try with 1000 trees.
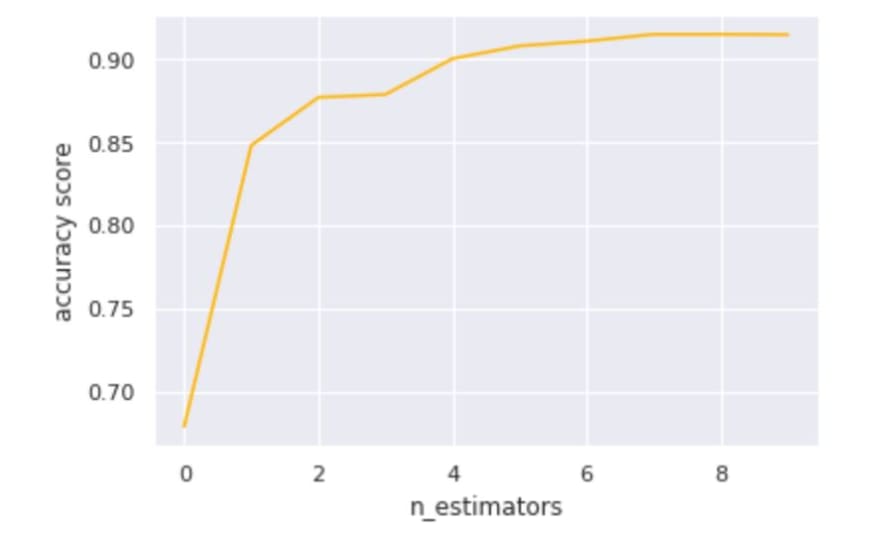
In the following image, we can see that the prediction accuracy is improving with the number of trees in the random forest.
4. Hyperparameters tuning
n_estimators=40 represents the number of trees averaged.
max_depth=3 means that the decision trees will only use 3 levels of decision.
min_sample_leaf=3 It stop training the tree further when a leaf node has 3 or less samples (before we were going all the way down to 1). Each tree will generalize better, but will be slightly less powerful on its own.
👉 Tips: the numbers that work well are 1, 3, 5, 10, 25, but it is relative to the overall dataset size.
max_features=0.5 The idea is that the less correlated the trees are with each other, the better. For row sampling, each new tree is based on a random set of rows. For column sampling, for every individual binary split, we choose from a different subset of columns. In this case, only half of the columns will be used.
👉 Tips: good values to use are 1, 0.5, log2 or sqrt.
Scikit-learn has a function called grid-search that takes a list of all the hyperparameters you want to tune and all of the values of these hyperparameters you want to try. It will run the model on every possible combination of all these hyper parameters and tell which one is the best.
training set/validation set/test set : the training set is used to train the model, the validation set is used to tune hyperparameters and the test set helps to check at the very end, if the model tuned is good on unseen data
There are different ways to create a training set and a validation set:
- bagging
- k-fold cross-validation

When working on a new data project, we want to iterate quickly, if running the model takes more than 10 seconds, it is a good practice to create a subset of data.
X_train, _ = split_vals(df_trn, 20000)
y_train, _ = split_vals(y_trn, 20000)
You can follow me on Instagram @oyane806 !





Top comments (0)