
When you hear "ding" you almost fall over running to your phone in the hopes of seeing the long-awaited SMS and then sadly discover it's a promotional message from an XYZ brand. This can really be annoying, many of these promotional and spam SMS continue to clog up our inboxes and get worse with time, stealing our precious time and attention.
What can we learn from Gmail?
The problem is not very new, It also exists on the side of the email and one thing that email providers like GMAIL adopted and worked so well is grouping emails into categories depending on the intentions of the emails which can either be promotional, social, primary and also being able to filter out fraudulent emails (spam).
Can we replicate the Gmail Approach to SMS? If yes How?
The meat of this article is centered around answering that question, we are going to learn how can we classify SMS messages into categories according to the intention of the messages, then now you might be asking yourself how one gets to know and classify the intention of SMS? We are going to train a machine learning model that will learn the similarities of each category and then use its generalized learned model to group new SMS into categories.
Data Collection and Annotations
The first step was sourcing, collecting, and annotating SMS data that will then be used to train our machine learning model, the data collection was done using the SMS backup application from multiple individual contributors, and the app data output was a well-organized JSON data of SMS and their details as shown in the below snippet example.
[
{
"_id": "7126",
"address": "TIGO",
"body": "Tigo inakutakia maadhimisho mema ya siku ya Muungano.",
"date": "1619430394016",
"errorCode": "-1",
"locked": "0",
"messageDirection": "INCOMING",
"messageType": "SMS",
"protocol": "0",
"read": "1",
"replyPathPresent": "0",
"seen": "1",
"serviceCenter": "+2557********",
"status": "-1",
"text": "Tigo inakutakia maadhimisho mema ya siku ya Muungano.",
"threadId": "492",
"type": "1"
},
...
]
We then annotated our data into distinct categories based on the context and intention of the text messages, these were the category that we came with;
- Promotional
- Notification
- Transaction
- Sports Bettings
- Michezo ya Bahati Nasibu (General gambling SMS)
- Survey
- Verification
- Informational
- Personal
- SPAM
We then exported our data into CSV format ready for crunching, *Where is the Data? Well we won't be able to share for now because some of the SMS contain identifiable personal information t*herefore we are currently working on cleaning and ensuring the data is of good quality and then will share through our Github repository.
Here we go
Now that you have a bit of background about the data that we are going to use to train our model, let's now get our hands dirty, let's break down our task into three steps: data preprocessing, training machine learning model, and model evaluation.
Data Preprocessing
Data preprocessing is a way of converting raw data into a format that can be easily parsed by a machine learning model. We need to preprocess our datasets to easily train our model. But first, let's read and view the structure of our datasets with the help of Pandas library
import pandas as pd
data = pd.read_csv('./raw sms data/data.csv')
data.head()

As we can see we have got a couple of columns in our dataset, let's start by exploring messageDirection our data has;
data["messageDirection"].value_counts()
# Output: INCOMING 3384 "There are 3384 incoming messages"
# OUTGOING 62
Now that we know the data collected consists of both OUTGOING and INCOMING SMS but from the very nature of our task, our primal interest lies in the incoming messages only, therefore we need to filter only data whose messageDirection is INCOMING.
incoming_sms = data[data["messageDirection"] == "INCOMING"]
interested_data = incoming_sms[['address', 'text', 'label']]
Examining Label distribution
Examining the distribution of labels is crucial because it can reveal information about how well your model will work with a particular label.
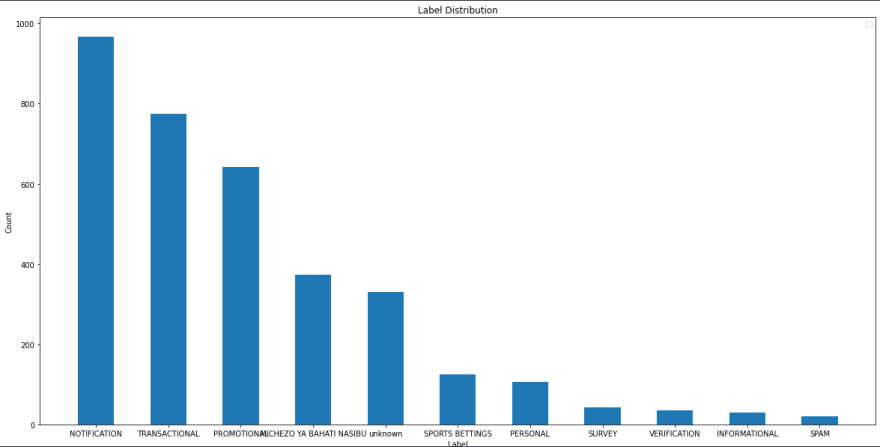
As you can see, most of our messages are "NOTIFICATION" labeled. "SPAM" messages are the least which means our dataset is not balanced.
Let's also remove duplicates in our datasets
texts = interested_data['text'].tolist()
ids = interested_data.index.tolist()
dirty_dict = dict(zip(ids, texts))
cleaned_dict = {}
used_texts = []
for id, text in dirty_dict.items():
if text in used_texts:
continue
cleaned_dict[id] = text
used_texts.append(text)
ids = list(cleaned_dict.keys())
print(len(ids))
# Only Filter out interested_data whose id is in ids
cleaned_incoming_sms = interested_data[interested_data.index.isin(ids)]
len(cleaned_incoming_sms)
# Output: 1920
Our data has been reduced from 3384 to 1920 which means almost 43% of our datasets were duplicates but this is an 'okay' amount of data to train our model.
Now let's get a good look at our data by visualizing it in wordcloud. But before that, we need to remove a few stopwords. Then, we can see how often some words are used in the texts according to their categories.
# Removing stop words
stopwords = ["na", "ya", "wa", "kwa", "pia", "kisha", "au"]
cleaned_incoming_sms['text'] = cleaned_incoming_sms['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in stopwords]))

cleaned_incoming_sms.loc[4:9]

The above result of our cleaned-incoming-sms is not particularly clean. We need to put in some extra effort.
- Make all of them lowercase.
- Remove all of the non-alphanumeric characters like ",", "+", "%", "!", ":"
- Remove all numbers in the text messages.
import re
# Clean the texts
def clean_text(text):
# remove all non-alphanumeric characters
text = text.lower() #convert text to lower-case
text = re.sub('[‘’“”…,]', '', text)
text = re.sub('[()]', '', text)
text = re.sub('[^a-zA-Z]', ' ', text)
text = re.sub(' +', ' ', text)
return text
cleaned_incoming_sms['text'] = cleaned_incoming_sms['text'].apply(clean_text)
All of our texts are clean now, so we can start training our model.
Training Machine Learning Model
We are going to use the Scikit-learn library to provide us all useful tools to train our model. Let's import our required tools and train our model.
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(cleaned_incoming_sms['text'], cleaned_incoming_sms['label'], test_size=0.2, random_state=42)
pipeline = make_pipeline(
TfidfVectorizer(lowercase=True, max_features=1000, stop_words=stopwords),
RandomForestClassifier(n_estimators=100, random_state=42)
)
pipeline.fit(x_train, y_train)
Since our dataset is not too large, the model will finish training in a very short time. After it finishes training, then we can check its score.
pipeline.score(x_test, y_test)
# Output: 0.9380530973451328
As you can see our model has a score of 94% when evaluated with test data which is quite good.
Testing our model
Let's save our model for later use and then we will import it again into another file to test it with some other messages.
import joblib
joblib.dump(pipeline, './pipeline.pkl')
NOTE: Before we test our model with some messages, we have to remember to pass them into the clean_text function to preprocess our text(remove non-alphanumeric characters, remove numbers, etc. in the text we are going to input to our model).
pipeline = joblib.load('./pipeline.pkl')
with open('test_data.txt', "r") as f:
test_data = f.readlines()
for text in test_data:
print(f"Text: {text} Prediction: {pipeline.predict([clean_text(text)])[0]}")

Results
We tested our model with 14 messages that it has never seen before. As you can see from the result above, most of the messages in the test data were "SPAM" messages. But the model couldn't pick up most of them since there were few spam messages to train our model.
Also, the model didn't quite perform well in the "PROMOTIONAL" label, because after removing duplicated messages in our datasets, label distribution has changed a lot.

Label distribution after removing duplicates
Conclusion
Any model's performance is strongly influenced by the quantity and size of the datasets. We couldn't access large datasets, but by spending more time thoroughly cleaning our training data, we can attempt to improve the accuracy of our model. Furthermore, we can tweak some parameters before training our model or we can experiment with alternative Machine Learning Classifiers like Decision Tree, SVM, etc. to achieve the best results and improve the performance of our model.
Thank you.

Top comments (0)