
Introduction

This post is going to be a composition of the practical parts of two posts, one written late last year and the other a couple of months ago respectively. The posts being Apache Zeppelin: stairway to notes* haven! (late Dec 2018) and Running your JuPyTer notebooks on Oracle Cloud Infrastructure (early September 2019). Although this time we are going to make Apache Zeppelin run on the Oracle Cloud Infrastructure.
We will follow a similar structure like in the previous posts for ease of reading and understanding.
Also for brevity, we will use the term OCI when referring to Oracle Cloud Infrastructure throughout the rest of the post. In some cases, I have hyperlinked and redirected the reader (with a bit of narration) with repeated steps in the post, and in some cases, I have expressed those steps literally in the post adapted to the current theme i.e. Apache Zeppelin on OCI.
Please do not literally use information like DNS or IP addresses or any other details directly from the screenshots or text areas in this post and from the linked ones. These details may differ in your case so please try to follow the ideas and principles behind the process. You should use the details that show up on your console or browser interface when you are setting up at your end, as instructed in the post.
OCI: get started quickly
So to get started we need to have an account on OCI, which is super simple to set up. I suggest reading the below sections from the post Running your JuPyTer notebooks on Oracle Cloud Infrastructure (provided screenshots to help navigate through the steps):
- Introduction
- Signing up
-
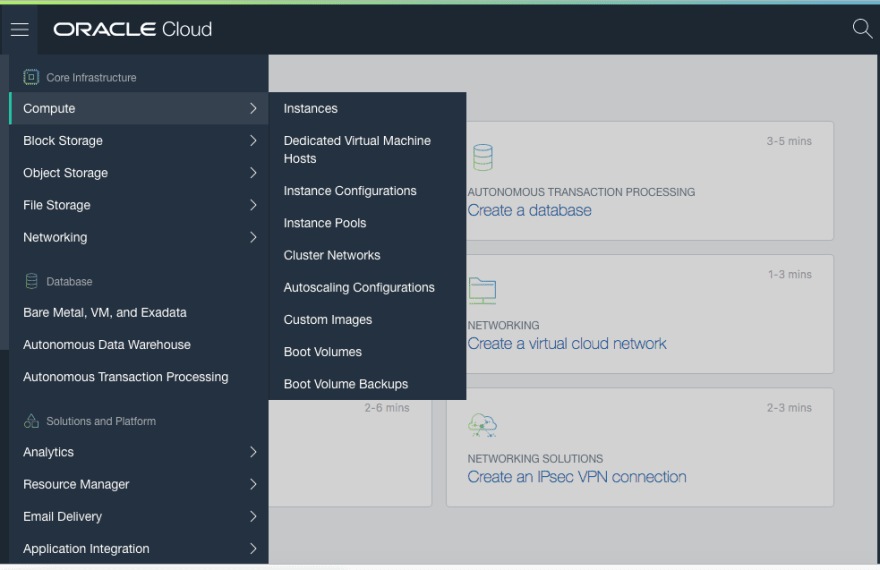
Setup


****
****
- Actions to get on the cloud
And we stop the moment we reach the end of the Actions to get on the cloud section. But please ensure you install everything along the way to have to hand the tools you need for the rest of the post. Skip anything that appears Jupyter notebooks related as we will be setting up Apache Zeppelin next.
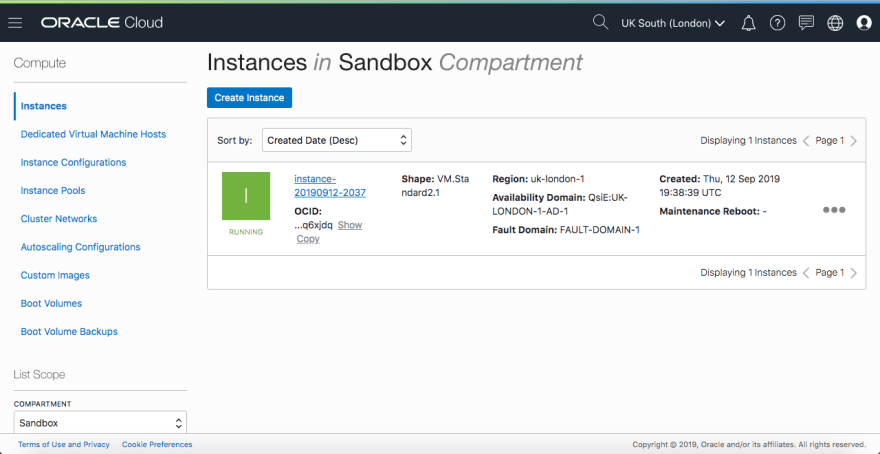
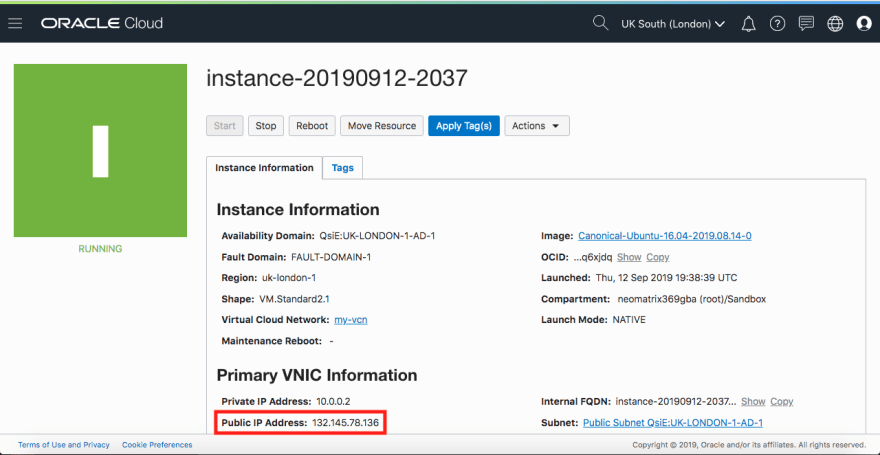
When we have finished the above we are at a good point, as we will have a VM instance accessible from both the browser as well as from the CLI. And we can then do further steps to install Apache Zeppelin and kick-off. Make a note of the Public IP Address of the VM instance created above before proceeding, in my case it is 132.145.60.249.
Zeppelin: get started quickly
If you already know Zeppelin and feel at home with it, and are confident after skimming through the post: Apache Zeppelin: stairway to notes* haven! you can directly go to the next section in the post i.e Running Apache Zeppelin.
But to gain familiarity with Apache Zeppelin if you haven’t used it in the past, I suggest to slowly go through the post: Apache Zeppelin: stairway to notes* haven! and get it to work on your local machine. We will be doing further steps to make it work on the cloud i.e. OCI. Just for your information, when the post was written we used Apache Zeppelin 0.8.0, Spark 2.4.3 and ran it on top of GraalVM 1.0.0-rc10, as was bundled in the docker image neomatrix369/zeppelin:0.1 since then things have moved on. For this post, we have decided to use more recent versions i.e. Apache Zeppelin 0.8.1, Spark 2.4.4 and GraalVM 19.2.0.1 and you can access this via the docker image neomatrix369/zeppelin:0.2.
Note: I have steered away from Apache Zeppelin 0.8.0 and 0.8.2 for this post as it has introduced new things that cause regression in our workflow, for all intent and purpose of this post we can use Apache Zeppelin 0.8.1. Version 0.8.0 produces this error (resolved in version 0.8.1) when we try to run a paragraph with Scala code.
Also, if you have already noticed, the Zeppelin world call notebooks as notes, cells as paragraphs and so on.
Running Apache Zeppelin
We will be running Apache Zeppelin on the cloud directly now since we have had the experience of running it on the local machine already. For some of you, this might now be a no-brainer, as the steps are not many and its pretty simple to go about as we have already laid the ground for it. Just to be clear, the same instructions are applicable on a bare-metal or VM instance.
Logging into the VM instance
You can then ssh into the box (see docs on connecting via ssh) and proceed with rest of the actions below:
### Oracle Linux and CentOS images, user name: opc
### the Ubuntu image, user name: ubuntu
$ ssh -i ~/.ssh/id_rsa ubuntu@132.145.60.249
or
$ ssh ubuntu@132.145.60.249
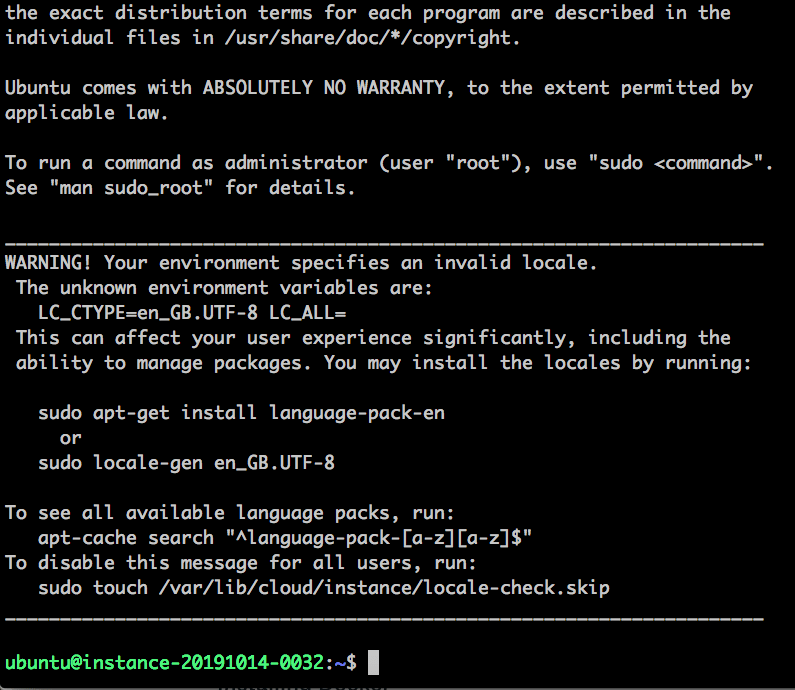
and we get the next prompt, to which we answer ‘yes’:
The authenticity of host '132.145.60.249 (132.145.60.249)' can't be established.
ECDSA key fingerprint is SHA256:USafjsySmPItXTdBOsQyiYbEdiFSa7Cs1so+9EnKC4M.
Are you sure you want to continue connecting (yes/no)? yes
which is followed by this console — a sign that you are now logged into the VM:
Cloning the git repo
Now that we are logged in and that we have all the scripts we need at https://github.com/neomatrix369/awesome-ai-ml-dl/tree/master/examples/apache-zeppelin, we can clone it and run them.
If you haven’t this yet, then please run the below commands:
$ git clone https://github.com/neomatrix369/awesome-ai-ml-dl/
$ cd examples/apache-zeppelin
Installing Docker
The Docker docs for installing Docker on Ubuntu can be found on the Docker site. A bash-script has also been provided to quicken the process, although the target OS here is Ubuntu 16.04 or higher:
$ ./installDocker.sh
Note: in case you choose another OS image during VM creation, you will have to install Docker manually with the docs from Docker or modify the above script to make it work for the target OS.
Building Apache Zeppelin Docker image (optional)
Achtung! really sorry, this process can take longer, so please go away and make yourself and others coffee, read xkcd, watch a comedy and then come back in 15–20 mins or so (depending on your network bandwidth)!
Hence we can choose to continue or skip to the next step and use an older version of the docker image.
We can start by running the build script to build our latest Zeppelin Docker container:
$ DOCKER_USER_NAME= IMAGE_VERSION=0.2 ./buildZeppelinDockerImage.sh
and we see these messages flying by:
Sending build context to Docker daemon 34.82kB
Step 1/21 : ARG ZEPPELIN_VERSION
Step 2/21 : FROM apache/zeppelin:${ZEPPELIN_VERSION}
---> 353d7641c769
Step 3/21 : ARG SPARK_VERSION
---> Using cache
---> 2ca1b6703dd7
Step 4/21 : ENV SPARK_VERSION=${SPARK_VERSION:-2.4.3}
---> Using cache
---> f507d31d0aca
Step 5/21 : RUN echo "$LOG_TAG Download Spark binary" && wget -O /tmp/spark-${SPARK_VERSION}-bin-hadoop2.7.tgz http://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop2.7.tgz
---> Running in c94542e7eb00
[ZEPPELIN_0.8.1]: Download Spark binary
--2019-10-13 19:55:16-- http://archive.apache.org/dist/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
Saving to: ‘/tmp/spark-2.4.4-bin-hadoop2.7.tgz’
[--snipped--]
213350K .......... .......... .......... .......... .......... 94% 51.4K 3m0s
213400K .......... .......... .......... .......... .......... 94% 88.1K 2m59s
213450K .......... .......... .......... .......... .......... 95% 58.7K 2m59s
213500K .......... .......... .......... .......... .......... 95% 45.5K 2m58s
213550K .......... .......... .......... .......... .......... 95% 4.40M 2m57s
213600K .......... .......... .......... .......... .......... 95% 83.8K 2m56s
213650K .......... .......... .......... .......... .......... 95% 91.9K 2m55s
213700K .......... .......... .......... .......... .......... 95% 67.2K 2m55s
213750K .......... .......... .......... .......... .......... 95% 166K 2m54s
213800K .......... .......... .......... .......... .......... 95% 79.8K 2m53s
[--snipped--]
Step 21/21 : CMD ["bin/zeppelin.sh"]
---> Running in 843684f60302
Removing intermediate container 843684f60302
---> 5833f13ff7c7
Successfully built 5833f13ff7c7
Successfully tagged neomatrix369/zeppelin:0.2
You have noticed, we have a few changes:
- amendments made to Zeppelin-Dockerfile)
- the build and run scripts also looks different (buildZeppelinDockerImage.sh and runZeppelinDockerImage.sh)
- and we are also using to 0.2 see CLI usages in the post
Hope all of this starts to make sense (I gave hints when we said things have moved on…).
Pushing the Docker Image to Docker Hub (optional)
Once we have a successfully built the docker image containing Apache Zeppelin from the above step we can easily upload the image from our local repository to the remote one via:
$ DOCKER_USER_NAME= IMAGE_VERSION=0.2 ./push-apache-zeppelin-docker-image-to-hub.sh
Although take note that it expects a couple of things:
- an account on Docker Hub (i.e. neomatrix369) — of course, your own account
- you are logged into your Docker Hub account locally
- you have set up the DOCKER_USER_NAME with your Docker hub account
Otherwise you will get error messages, hopefully, they will guide you through till you upload it.
Note: in our case, we have access to the docker image on Docker hub, see neomatrix369/zeppelin on Docker Hub.
Running Apache Zeppelin from the Docker Image
We will download the already created images hosted on Docker Hub:
Version 0.1 (Apache Zeppelin 0.8.0, Spark 2.4.3, GraalVM 1.0.0-rc10) — older image
$ docker pull neomatrix369/zeppelin:0.1
$ ./runZeppelinDockerContainer.sh
or
Version 0.2 (Apache Zeppelin 0.8.1, Spark 2.4.4, GraalVM 19.2.0.1) — new image
$ docker pull neomatrix369/zeppelin:0.2
$ IMAGE_VERSION=0.2 ./runZeppelinDockerContainer.sh
the above commands should result in the output:
ubuntu@instance-20191014-0101:~/awesome-ai-ml-dl/examples/apache-zeppelin$ IMAGE_VERSION=0.2 ./runZeppelinDockerContainer.sh
Please wait till the log messages stop moving, it will be a sign that the service is ready! (about a minute or so)
Once the service is ready, go to http://localhost:8080 to open the Apache Zeppelin homepage
Pid dir doesn't exist, create /zeppelin/run
OpenJDK GraalVM CE 19.0.0 warning: ignoring option MaxPermSize=512m; support was removed in 8.0
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/zeppelin/lib/interpreter/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/zeppelin/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[---snipped---]
WARNING: A HTTP GET method, public javax.ws.rs.core.Response org.apache.zeppelin.rest.CredentialRestApi.getCredentials(java.lang.String) throws java.io.IOException,java.lang.IllegalArgumentException, should not consume any entity.
WARNING: The (sub)resource method createNote in org.apache.zeppelin.rest.NotebookRestApi contains empty path annotation.
WARNING: The (sub)resource method getNoteList in org.apache.zeppelin.rest.NotebookRestApi contains empty path annotation.
Opening the Apache Zeppelin notes in your browser
Go to the browser and try to open this:
But this won’t work because we haven’t opened up the port 8080 from within our cloud network (via Ingress Rules, read more about it here) to the outside world (public):
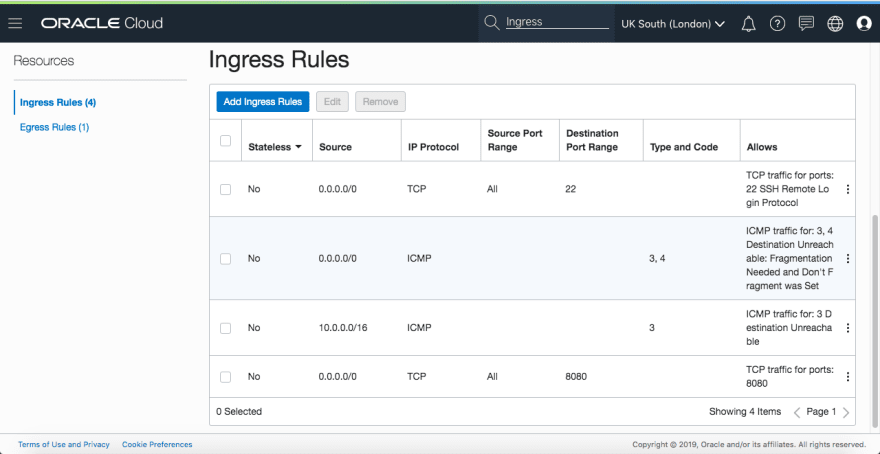
We would need to add the above entry to the Ingress Rules section, you can get to Ingress Rules page via the navigation menu: Networking > Virtual Cloud Networks > Virtual Cloud Network Details (by clicking on a VCN entry) > Security Lists, which brings you to the page with the Default Security Lists. **On clicking the Security List that corresponds to your **Virtual Cloud Network (VCN) you will land on the above Ingress Rules page.
In case, you are still not able to find it, search for the term security using the search facility on any page in the Cloud Console (see the magnifying glass 🔍at the top of the page). This will show you all the **Default Security Lists and clicking on it will bring you to the Ingress Rules page above (you might have just one Security List entry). Note: Ingress means traffic coming into the network/VM instance.
Why port 8080, that’s because we set it up like that in the docker scripts, have a look at the sources to find out why and how.
Having done all of the above: voila! We see the Apache Zeppelin startup page in the browser:
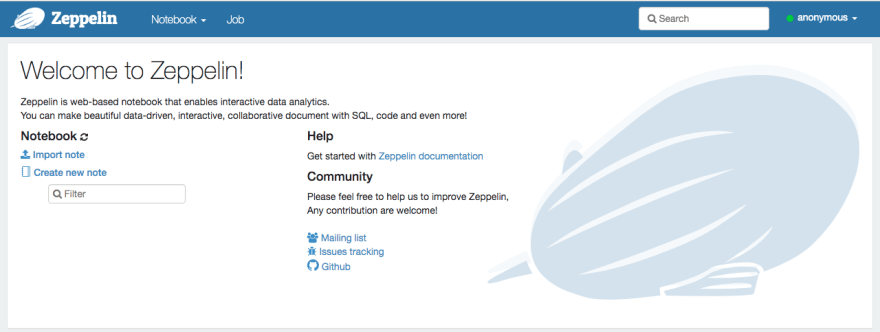
Using Apache Zeppelin notes
Take a look at the section Importing a note in Apache Zeppelin: stairway to notes* haven! this section onwards you can see how to import existing notes and execute them. Once we import and open a note, and run it, it would look like this:
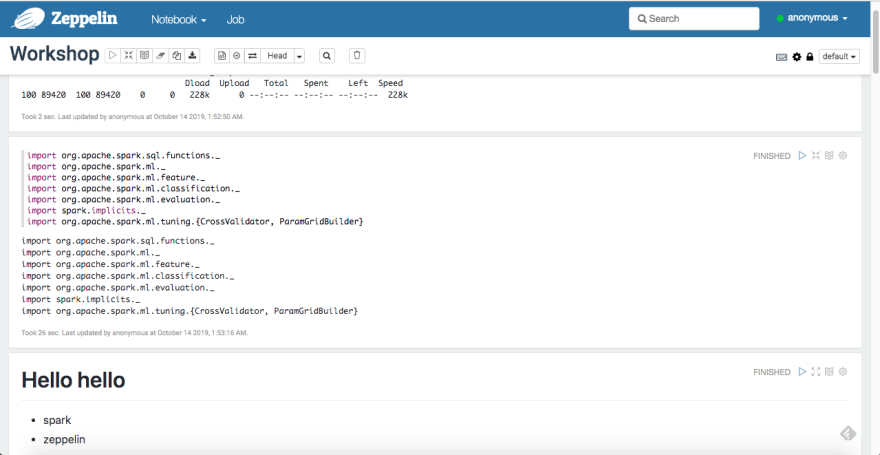
Importing this note also creates a “notes.json” file in the ~/awesome-ai-ml-dl/examples/apache-zeppelin/notebook folder of the VM instance.
Further examples can be found on https://github.com/dylanmei/docker-zeppelin, although these would need additional installation and configuration to the Apache Zeppelin build.
Create a custom image for reuse
As we have been able to successfully run Apache Zeppelin from inside a VM instance, we can save this image for future re-use or share with others. Before doing that, I would delete the logs and notebook folders from the ~/awesome-ai-ml-dl/examples/apache-zeppelin of the VM instance.
Creating an image of the VM instance can be done via Compute> Instances > Instance Details the navigation menu, and Create Custom Image from the Actions drop-down menu:

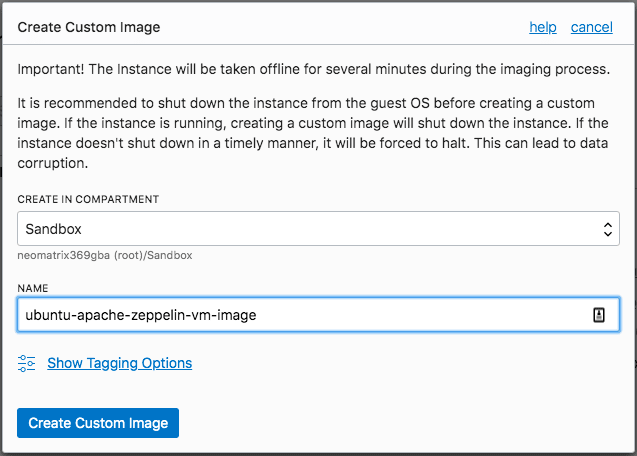
Note: whilst in the process of creating a custom image, your original VM instance is shut-down. This can take under a couple of minutes to complete depending on the size of the original VM instance.
When successfully created, it becomes available among the list of Custom Images to choose from, the next time we go to create a new VM instance:
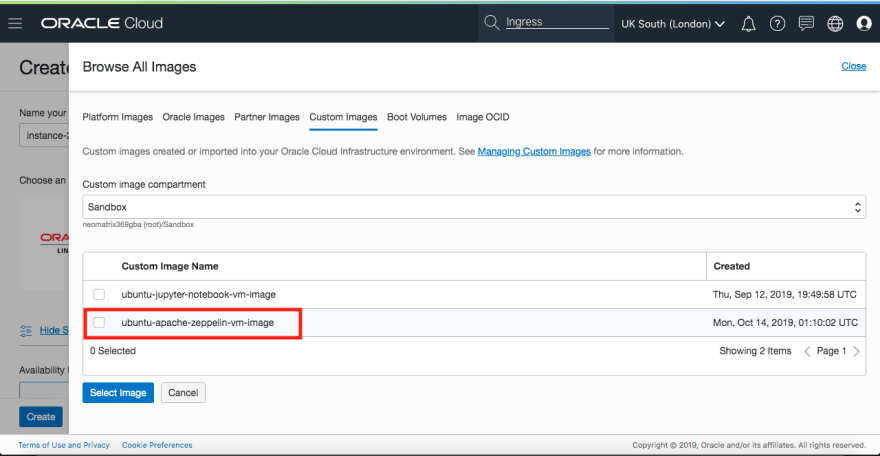
Power-user
If all of this was piece of cake for you or you have survived without much hassle, then try out all the deep-dive stuff mentioned in the README page here.
To be able to code in other JVM languages in the Apache Zeppelin environment all you need is additional extensions — it’s only a matter of installing and configuring. You can learn all about them here, you can see you can also code in Python on Apache Zeppelin. Find out how you can write your own interpreters for Apache Zeppelin. Both the notebook and interpreters can be accessed via Notebook API and Interpreter API respectively.
Signing off
[--snipped--]
Oct 14, 2019 1:02:40 AM org.glassfish.jersey.internal.Errors logErrors
WARNING: The following warnings have been detected: WARNING: A HTTP GET method, public javax.ws.rs.core.Response org.apache.zeppelin.rest.InterpreterRestApi.listInterpreter(java.lang.String), should not consume any entity.
WARNING: A HTTP GET method, public javax.ws.rs.core.Response org.apache.zeppelin.rest.CredentialRestApi.getCredentials(java.lang.String) throws java.io.IOException,java.lang.IllegalArgumentException, should not consume any entity.
WARNING: The (sub)resource method createNote in org.apache.zeppelin.rest.NotebookRestApi contains empty path annotation.
WARNING: The (sub)resource method getNoteList in org.apache.zeppelin.rest.NotebookRestApi contains empty path annotation.
C
In case, you have created a note, it gets saved in the sub-directory called (apache zeppelin directory), you can retrieve this using scp from your local machine (see here on how to do that).
Make sure you have signed out of both the oracle.com and cloud.oracle.com login sessions, it’s easy to forget one or the other. But before doing that please also have a look at the Cleaning up of resources page in the docs — you don’t want your instance running forever while you are not looking at it!
Conclusion

In effect, if we summarise the conclusions of the two posts, Apache Zeppelin: stairway to notes* haven! and Running your JuPyTer notebooks on Oracle Cloud Infrastructure we will more or less say:
Apache Zeppelin gives us:
- similar flexibility as Jupyter notebooks, and allows extending functionality via configurations and extensions
- execution progress per paragraph (per cell) is always displayed (in real-time) unlike Jupyter notebooks
- lazy execution to help efficiency
- round-trip navigability between table data and visualisation in the cell (paragraph)
- execution may appear a bit slower than Jupyter notebooks at times
- but there are solutions to speed this up (for future posts to cover)
- all-in-all a great place for Java/JVM developers to feel at home and do ML experiments on the JVM
OCI gives us:
- an easy-to-use cloud environment
- quickly set up our environment to get to market with our apps and solutions we want to bring to market quick
- enables us to run Apache Zeppelin (natively or via Docker image)
- instances that can be shared publicly or privately depending on your network security settings
- provides ways to secure your infrastructure on the cloud (we didn’t cover it with much depth here), but please check out the docs on Security on the OCI docs page to learn more.
Please keep an eye on this space, and share your comments, feedback or any contributions which will help us all learn and grow to @theNeomatrix369, you can find more about me via the *[About me page*](http://neomatrix369.worpress.com/aboutme).**
Resources
Apache Zeppelin
- Apache Zeppelin
- an interpreter for that thing has been provided
- Download page
- Apache Zeppelin: Quick Start page
- Exploring Zeppelin UI
- https://issues.apache.org/jira/browse/ZEPPELIN-3586
- https://gist.github.com/conker84/4ffc9a2f0125c808b4dfcf3b7d70b043#file-zeppelin-dockerfile
- https://github.com/neomatrix369/awesome-ai-ml-dl/tree/master/examples/apache-zeppelin
- Write your own interpreters for Apache Zeppelin
- Notebook API
- Interpreter API
- Examples to try
- https://github.com/dylanmei/docker-zeppelin
- https://github.com/mmatloka/machine-learning-by-example-workshop
- https://raw.githubusercontent.com/mmatloka/machine-learning-by-example-workshop/master/Workshop.json
Docker
- Docker Hub signup
- Install Docker on Ubuntu 16.04 or higher
- Bash Script to build Docker container
- https://github.com/dylanmei/docker-zeppelin.
OCI/Cloud
- Getting Started
- Tutorial to setup a VM instance
- Install CLI
- CLI docs
- Cleaning up of resources
- Docs on connecting via ssh to OCI
- New Sign-in: https://cloud.oracle.com/en_US/sign-in
- Traditional Sign-in: https://myaccount.cloud.oracle.com/
- Contact Support
- Developer Tools
- Documentation
- Oracle Cloud Community Forum
- Oracle Cloud Compliance
- Oracle Cloud Infrastructure Blog
Security
About me
Mani Sarkar is a passionate developer mainly in the Java/JVM space, currently strengthening teams and helping them accelerate when working with small teams and startups, as a freelance software engineer/data/ml engineer, more….
Twitter: @theNeomatrix369 | GitHub: @neomatrix369

Top comments (0)