
*notes is for notebooks in Zeppelin lingo
This post is a re-blog of my @JavaAdventCalendar post from https://www.javaadvent.com/2018/12/apache-zeppelin-stairway-to-notes-haven.html.
Introduction
Continuing from the previous post, Two years in the life of AI, ML, DL and Java, where I had expressed my motivation. I mentioned our discussions, one of the discussions was, that you can write in languages like Python, R, Julia in JuPyteR notebooks. Most were not aware you can also write Java and Scala in addition to Python, SQL etc… with the help of Apache Zeppelin notebooks. And so I did commit to sharing something in those lines to broaden everyone’s awareness. Although it’s been some time since then I have managed to put together my thoughts into this post, showing how we can do similar operations using Apache Zeppelin which supports both Java, and Scala. The project itself is written in Java and it’s open architecture means Zeppelin can support anything as long as an interpreter for that thing has been provided.
First things, first…
In case, I have lost some of you, here’s what I meant by JuPyteR notebooks and writing notebooks in different languages, see https://www.youtube.com/watch?v=Rc4JQWowG5I and also have a look at the list of kernels supported by JuPyteR notebook. But in this post, we are covering Apache Zeppelin, how to get it to work and how to use a couple of notes in the Zeppelin environment.
The fun part…
So let’s have a look at how we do it, by first downloading and installing Apache Zeppelin.
Download & Installation
Download
Go to the Download page, a number of options are available, two of the recommended options:
- Download entire binary containing the interpreters
- Download a net installer which then downloads the interpreters (you can choose the ones you need or use
--allflag for all the interpreters)
In our case, I downloaded the net-install interpreter package from the download binary package section.
Installation
I unpacked the .tgz archive and placed it in the /opt/ folder and ran:
$ cd /opt/zeppelin-0.8.0-bin-netinst
$ ./bin/install-interpreter.sh --all
For another type of archive or installation option, see the instructions on the Quick Start page.
Running
Depending on the type of binary downloaded, follow the instructions on the Quick Start page.
Although in our case, I had to just run:
$ cd /opt/zeppelin-0.8.0-bin-netinst
$ ./bin/zeppelin.sh
Optional setting
As I was curious what it was running Zeppelin under another JDK than the usual Oracle or OpenJDK JDK or JRE, I decided to try GraalVM JRE and so I switched JAVA_HOME to point to /path/to/GraalVM/jre on my machine. The GraalVM JDK comes bundled with the JRE which can be independently used just like any Java vendor’s JRE.
When Zeppelin is run, these messages are shown (you can see the JAVA_HOMEsettings have been picked up):
Pid dir doesn't exist, create /opt/zeppelin-0.8.0-bin-netinst/run
GraalVM 1.0.0-rc7 warning: ignoring option MaxPermSize=512m; support was removed in 8.0
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/zeppelin-0.8.0-bin-netinst/lib/interpreter/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/zeppelin-0.8.0-bin-netinst/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Dec 25, 2018 1:34:23 AM org.glassfish.jersey.internal.inject.Providers checkProviderRuntime
WARNING: A provider org.apache.zeppelin.rest.NotebookRepoRestApi registered in SERVER runtime does not implement any provider interfaces applicable in the SERVER runtime. Due to constraint configuration problems the provider org.apache.zeppelin.rest.NotebookRepoRestApi will be ignored.
Dec 25, 2018 1:34:23 AM org.glassfish.jersey.internal.inject.Providers checkProviderRuntime
Dec 25, 2018 1:34:23 AM org.glassfish.jersey.internal.inject.Providers checkProviderRuntime
[---- snipped ----]
WARNING: The (sub)resource method getNoteList in org.apache.zeppelin.rest.NotebookRestApi contains empty path annotation.
Running (continued)
Once all the above steps are completed and Zeppelin has successfully started, do the below:
- Open http://localhost:8080/#/
- And then look at the docs under Exploring Zeppelin UI
- And then the tutorial notebook at http://localhost:8080/#/notebook/2A94M5J1Z
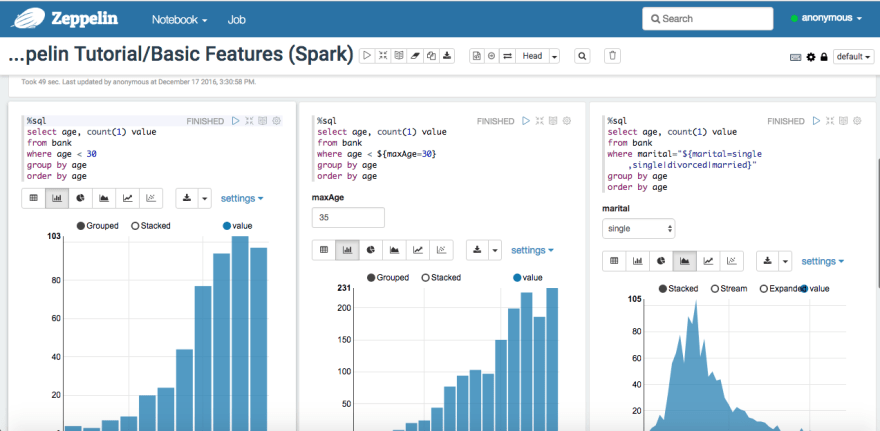
Small experiment
Just to look at some numbers, I decided to use the Zeppelin Tutorial/Basic Features (Spark) notebook to check the difference in performance when run using GraalVM JDK/JRE and another JDK/JRE and here are the results:
GraalVM JDK
-
./bin/zeppelin.sh48.26s user 25.63s system 28% cpu 4:20.15 total (started and stopped the script manually) - First paragraph
- Took 47 sec. Last updated by anonymous at December 25 2018, 2:18:36 AM.
- Each paragraph thereafter (columns from left to right):
- Took 44 sec. Last updated by anonymous at December 25 2018, 2:18:44 AM. (outdated)
- Took 10 sec. Last updated by anonymous at December 25 2018, 2:18:47 AM. (outdated)
- Took 6 sec. Last updated by anonymous at December 25 2018, 2:18:50 AM. (outdated)
Oracle JDK8
-
./bin/zeppelin.sh37.64s user 25.73s system 29% cpu 3:38.49 total (started and stopped the script manually) - First paragraph
- Took 54 sec. Last updated by anonymous at December 25 2018, 2:12:16 AM.
- Each paragraph thereafter (columns from left to right):
- Took 43 sec. Last updated by anonymous at December 25 2018, 2:12:24 AM. (outdated)
- Took 13 sec. Last updated by anonymous at December 25 2018, 2:12:29 AM. (outdated)
- Took 6 sec. Last updated by anonymous at December 25 2018, 2:12:31 AM. (outdated)
My observations are that the performance differences were marginal, although for different kinds of operation the results would vary between the two, hence more observations are needed. Best to stay put on GraalVM JRE unless otherwise indicated to see more such variations as we go along.
Note: paragraphs are code blocks in Zeppelin lingo, note is what a notebook is referred to as in the Zeppelin world. Hence the idea, a note has one or more paragraphs.
There are many other tutorials (sample) notes to play with, see on the home page under Zeppelin Tutorial (see screenshot):
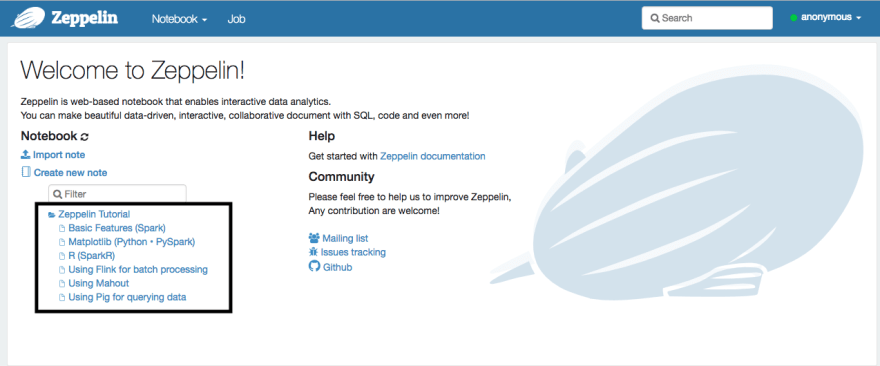
Importing a note
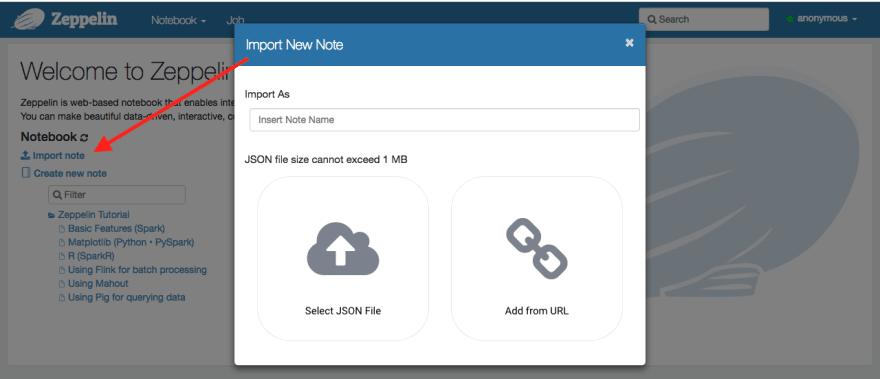
From the home page (http://localhost:8080/#/, see below), we can select the hyperlinked text Import Note, which allows us to import a note (Notebook in Zeppelin lingo) from disk or from a URL.
In our case, I added the note from https://github.com/mmatloka/machine-learning-by-example-workshop (ensure the link to the raw contents of the json file is used i.e. https://raw.githubusercontent.com/mmatloka/machine-learning-by-example-workshop/master/Workshop.json) into Zeppelin, and tried running but got various errors when trying to run the first couple of paragraphs.
Looking for answers as to why I was getting those errors, I came across a forum and then took upon the suggestion from someone on the forum where similar errors messages were reported. It was a workaround to fix issue https://issues.apache.org/jira/browse/ZEPPELIN-3586.
We failed the previous time, so let’s try again…
One of the solutions was to make SPARK_HOME point to a separate instance of Spark and not rely on the embedded spark interpreter inside the Apache Zeppelin installation. As a workaround, a link to a Dockerfile gist was provided at https://gist.github.com/conker84/4ffc9a2f0125c808b4dfcf3b7d70b043#file-zeppelin-dockerfile. I extended the script to incorporate GraalVM JRE and added the necessary configuration for it to be visible to Zeppelin and Spark:
Zeppelin-Dockerfile
FROM apache/zeppelin:0.8.0
# Workaround to "fix" https://issues.apache.org/jira/browse/ZEPPELIN-3586
RUN echo "$LOG_TAG Download Spark binary" && \
wget -O /tmp/spark-2.3.1-bin-hadoop2.7.tgz http://apache.panu.it/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz && \
tar -zxvf /tmp/spark-2.3.1-bin-hadoop2.7.tgz && \
rm -rf /tmp/spark-2.3.1-bin-hadoop2.7.tgz && \
mv spark-2.3.1-bin-hadoop2.7 /spark-2.3.1-bin-hadoop2.7
ENV SPARK_HOME=/spark-2.3.1-bin-hadoop2.7
### My modified steps here on:
RUN rm -fr /usr/lib/jvm/java-1.8.0-openjdk-amd64 /usr/lib/jvm/java-8-openjdk-amd64
RUN wget https://github.com/oracle/graal/releases/download/vm-1.0.0-rc10/graalvm-ce-1.0.0-rc10-linux-amd64.tar.gz
RUN tar xvzf graalvm-ce-1.0.0-rc10-linux-amd64.tar.gz
RUN mv graalvm-ce-1.0.0-rc10/jre /usr/lib/jvm/graalvm-ce-1.0.0-rc10
ENV JAVA_HOME=/usr/lib/jvm/graalvm-ce-1.0.0-rc10
ENV PATH=$JAVA_HOME/bin:$PATH
RUN java -version
RUN rm graalvm-ce-1.0.0-rc10-linux-amd64.tar.gz
RUN rm -fr graalvm-ce-1.0.0-rc10
CMD ["bin/zeppelin.sh"]
And created two small bash scripts to help build the docker image and run the container from the image.
Build docker image
docker build -t zeppelin -f Zeppelin-Dockerfile .
Run docker container
docker run --rm \
-it \
-p 8080:8080 zeppelin
Note: the docker image is called zeppelin:latest, and is about 4.45GB in size.
The above scripts can be found at https://github.com/neomatrix369/awesome-ai-ml-dl/tree/master/examples/apache-zeppelin, please feel free to improve them and create pull requests back into the repo.
In case, you don’t wish to do the above, you could try using https://github.com/dylanmei/docker-zeppelin. I’m Apache Zeppelin works out of the box using this container as well.
I wasn’t too keen with the above as the whole process took more than 45 mins, 35 mins of which went into downloading several MBs of Spark. Downloading the GraalVM JDK was a breeze, less than 5 minutes on my high-speed DSL connection.
Applied the same steps above to load Michal Matloka’s Workshop notebook (workshop.json) and ran the paragraphs in the notebook and it worked like a charm, without any errors, of course. Thanks, Michal Matloka, for providing with such an example to play with and learn multiple things in one go.
From loading the dataset from a .csv file:
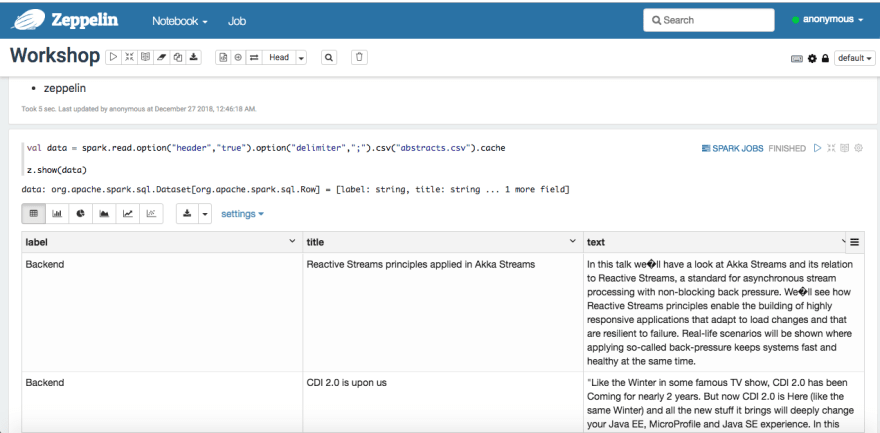
to produce the final outcome, via the parameter avgMetrics – average cross-validation metrics for each paramMap in CrossValidator.estimatorParamMaps, in the respective order.
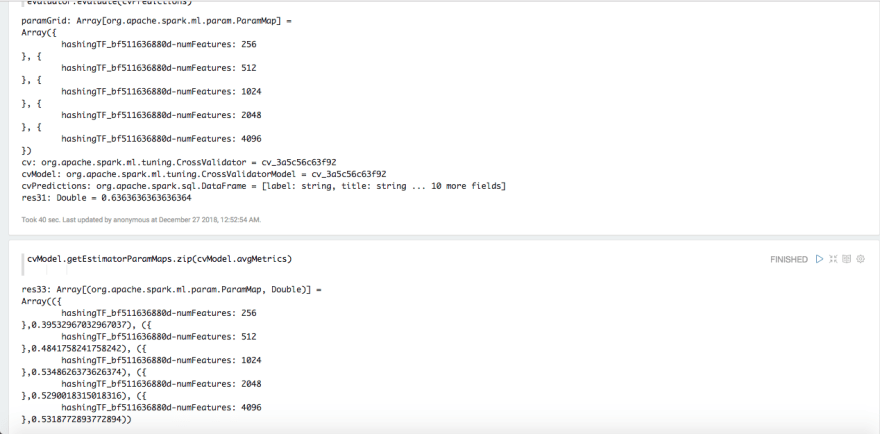
A score of 53.18% — might still need a bit of tweaking and fine-tuning to achieve a higher score but that is a different discussion and tangents from our current topic on Zeppelin notes.
Caveat
Somehow Zeppelin does not like code layouts with such indentations:
val indexToString = new IndexToString()
.setInputCol("prediction").setOutputCol("predictionLabel")
.setLabels(stringIndexer.labels)
so when I removed the indentation to join the chain of function calls together:
val indexToString = new IndexToString().setInputCol("prediction").setOutputCol("predictionLabel").setLabels(stringIndexer.labels)
I was able to run the paragraphs fine. I had to do this to all the paragraphs to prevent any errors from Zeppelin. Or else you get messages of such nature across all the paragraphs:
:1: error: illegal start of definition
.setInputCol("prediction").setOutputCol("predictionLabel")
^
Summary
Things I like about Zeppelin are:
- you have a clean and intuitive interface (must be Angular at work)
- you can write custom interpreters and expand the accepted list of languages
- write your own visualisers
- execution progress of every paragraph is displayed in real-time
- the execution time of every paragraph is computed and displayed in real-time
- wherever applicable a table of data can be visualised into a number of visuals and back to table of data — and all of this is done lazily (only executed when selected and keeps the results static)
Although, execution can appear to be slower than JuPyteR notebooks. A number of bells-and-whistles available in IPython notebooks are absent which also means being an open-source project it leaves a lot of room for improvements via contributions — pick your favourite feature of choice for a pull request.
All-in-all a great place for Java/JVM developers to feel at home and use Zeppelin to do their prototype, ML training and experimentation work for developers familiar with not just Python and R but also Java and Scala.
Please keep an eye on this space, and share your comments, feedback or any contributions which will help us all learn and grow to @theNeomatrix369, you can find more about me via the About me page.
About me
Mani Sarkar is a passionate developer mainly in the Java/JVM space, currently strengthening teams and helping them accelerate when working with small teams and startups, as a freelance software engineer/data/ml engineer, more….
Twitter: @theNeomatrix369 | GitHub: @neomatrix369

Top comments (0)