
NebulaGraph Operator is a plug-in to deploy, operate and maintain NebulaGraph automatically on K8s. Building upon the excellent scalability mechanism of K8s, we introduced the operation and maintenance knowledge of NebulaGraph into the K8s system in the CRD + Controller format, which makes NebulaGraph a real cloud-native graph database.
NebulaGraph is a high-performance distributed open source graph database. From the architecture chart below, we can see that a complete NebulaGraph cluster is composed of three types of services, namely the Meta Service, Query Service (Computation Layer) and Storage Service (Storage Layer).
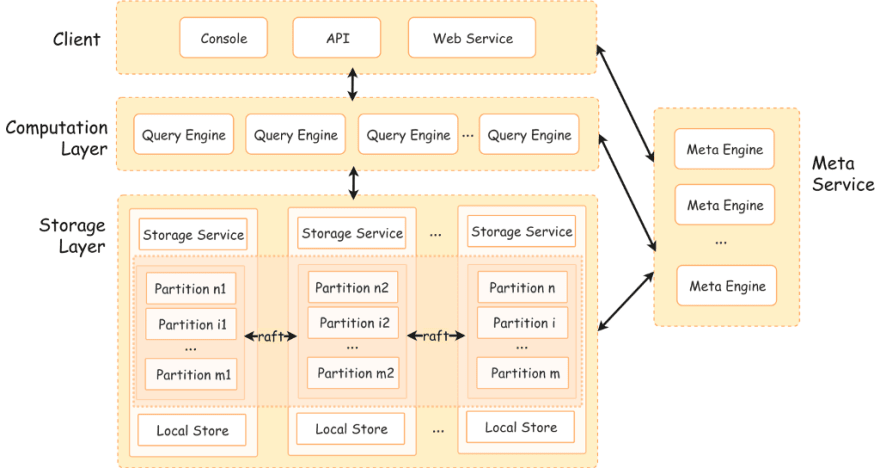
Each type of the service is a cluster composed of multiple replica components. In NebulaGraph Operator, we name these three types of components as Metad, Graphd and Storaged.
- Metad: Responsible for providing and storing the metadata of the graph database. It also acts as the scheduler for the cluster, directing operation and maintenance such as storage expansion, data migration and leader change.
- Graphd: Responsible for processing the query language (nGQL) statements for NebulaGraph. There is a stateless query calculation engine running in each Graphd. And these engines don’t communicate with each other. Instead, they only read meta data form the Metad cluster and communicate with the Storaged cluster. At the same time, they are also responsible for the access and interaction of different clients.
- Storaged: Responsible for the graph data storage. The graph data is divided into many partitions. Partitions with the same ID form a Raft Group to achieve multi-replica consistency. The default storage engine of NebulaGraph is the Key-Value storage of RocksDB.
Now we have a brief understanding to the core components of Nebula Graph, we can draw the following conclusions:
- NebulaGraph adopts the disaggregated storage and compute architecture. With a clear components stratification and responsibility, you can do the scale in or out operation on any of the components independently according to your business needs. Thanks to this feature, deploying NebulaGraph on container orchestration systems like K8s is more friendly. You can take full advantage of the flexibility of NebulaGraph.
- NebulaGraph is a complex distributed system. Deploying, operating and maintaining NebulaGraph all require specified expertise, which steepens the learning curve and increases the workload. Even if you deploy NebulaGraph on the K8s system, the native K8s controller is not good enough for state management and exception handling. As a result, NebulaGraph cluster can’t play its full role.
Based on the above considerations, we developed the Nebula Operator to give full play to NebulaGraph’s native scalability and failover capacity. The Nebula Operator also lowers the threshold for operation and maintenance of Nebula Graph clusters.
In order to better understand the working principle of Nebula Operator, let us first review what an Operator is.
What is Nebula Operator
Operator is not a new concept. As early as 2017, CoreOS launched their Etcd Operator. The aim of Operator is to strengthen K8s in the stateful applications management. Etcd Operator benefits from the two core concepts of K8s: declarative API and Control Loop.
Let’s describe this process by the following pseudocode snippet.
Declare the desired state of object X in the cluster and create X for {
current_state := Get the current state of object X in the cluster
desired_state := Get the desired state of object X in the cluster
if current_state == desired_state {
nothing is done
} else {
Do the pre - defined choreography actions and move the current state to the desired state
}
}
In the K8s system, there is a specific control loop running in each built-in resource object. The control loop gradually moves the current state to the desired state through the pre-defined orchestration actions.
For resource types that do not exist in K8s, you can register them by adding customized API objects. The common way is to use the CustomResourceDefinition (CRD) and the Aggregation ApiServer (AA). For example, Nebula Operator uses the CRD to register a “Nebula Cluster” resource and an “Advanced Statefulset” resource.
When you’re done with the above-mentioned customized resource, you can write the customized controller to watch the state change of the your customized resource. Also, you can operate and maintain Nebula Graph automatically according to your own strategy. Actually, Nebula Operator simplifies the operations and maintenance in this way.
apiVersion: nebula.com/v1alpha1
kind: NebulaCluster
metadata:
name: nebulaclusters
namespace: default
spec:
graphd:
replicas: 1
baseImage: vesoft/nebula-graphd
imageVersion: v2-preview-nightly
service:
type: NodePort
externalTrafficPolicy: Cluster
storageClaim:
storageClassName: fast-disks
metad:
replicas: 3
baseImage: vesoft/nebula-metad
imageVersion: v2-preview-nightly
storageClaim:
storageClassName: fast-disks
storaged:
replicas: 3
baseImage: vesoft/nebula-storaged
imageVersion: v2-preview-nightly
storageClaim:
storageClassName: fast-disks
schedulerName: nebula-scheduler
imagePullPolicy: Always
Here we displayed a simple Nebula Cluster instance for you. You need only to modify the size in the spec, and Nebula Operator will take care of deploying, destroying with the control loop. For example, if you want to expand the number of the Storaged replica to 10, you only need to modify the .spec.storaged.replicas parameter to 10.
Now that you have gained the initial concept of Nebula Graph and Nebula Operator, let’s see what features Nebula Operator provides.
- Deploy/Uninstall: We describe the whole Nebula Graph cluster with a CRD and register it in the ApiServer. Users only need to provide the corresponding CR file, and the Operator can quickly deploy or uninstall a Nebula Graph cluster. In this way, the cluster creating and uninstalling is simplified.
- Scalability: By calling the native scaling interface provided by Nebula Graph, we implemented scalability for the Nebula Operator encapsulation and ensured the data stability. Users need only to modify the size in the yaml spec to scale in or out.
- Upgrade: Based on the natively provided StatefulSet by K8s, we extended its ability to replace the image in place. Upgrading your cluster with Nebula Operator not only cuts the Pod scheduling time but also improves the cluster stability and certainty because there is no Pod place or resource change during the upgrading.
- Failover: Nebula Operator observes the services dynamically by calling the cluster interface provided by Nebula Graph. Once exception is detected, Nebula Operator automatically fixes the failure and activates the corresponding fault tolerance mechanism according to the exception type.
- WebHook: A standard Nebula Graph cluster needs at least three metad replicas. Incorrect modification of the metad parameter will lead to cluster failure. We check the correctness of some required parameters by using the access control of the WebHook. To run the cluster stably, we change some wrong declarations compulsively by changing control.
Hope you find Nebula Operator interesting. If you have any question, feel free to leave comments below!
You might also like:
- Automating Your Project Processes with Github Actions
- Practice Jepsen Test Framework in Nebula Graph
- Integrating Codecov Test Coverage With Nebula Graph
Like what we do ? Star us on GitHub. https://github.com/vesoft-inc/nebula
Originally published at https://nebula-graph.io on November 25, 2020.

Top comments (0)