
I like beer. Chances are, you like beer, too. The reason there's a good chance that you like beer is that you're likely a developer, and a lot of developers, well, like beer. It's science, really.
Developers also like building things and tracking things, and a lot of us like going to conferences and learning things.
But something developers sometimes don't really like, is meeting people. That's why I'm building a little project to combine the things we like to help fix some of the things we don't like.
I call it Beer Snaps. And it works like this, you find me at a conference (or I find you... sneaky), we get a picture together, and I add you to my hopefully growing list of Beer Snaps in my beer catalog. Cheers!
Any time you get to spend a good portion of your day thinking about and writing about beer it is a good day.
— Jesse Martin (@motleydev ) October 31, 2019
So what's the real reason I'm building Beer Snaps? Well, as you may know, I work for a company that's building the greatest content management system on earth. And a lot of developers have been asking for the best way to connect the greatest content management system on earth with their favourite framework. I am an advocate for the developers, so I'm here to help.
This will be a multi-part series, likely, maybe. We'll see. I'm building my content repository (Beer Snaps) and will recreate the same simple site in the top frameworks available (and accept requests - in exchange for beer, of course).
But this is Part 1, and that means we need to talk about the data model, and to do that, we need to talk about beer. So let's begin.
Defining our Domain
Domain logic is a term that refers to the nuances of a particular business's or industry's needs and the ensuing business structures, logic gates and more that it entails.
In computer software, business logic or domain logic is the part of the program that encodes the real-world business rules that determine how data can be created, stored, and changed. - Wikipedia
For the sake of my domain, I want to track individual beers, some basic data about the beer itself (flavor, style, etc), my personal "cold take" review, the event where I had it (if there was one), pictures of people I met and some basics about those people like Twitter handle or website. I'm also going to track the glass I had the beer in, because this is a high-class catalog, after all. Felt cute, used a flute?
Here's a high level diagram of how that looks, we'll break it down in the next steps. I promise, this is about as dry as this series will be. There will be less puns going forward. Maybe. Probably not.
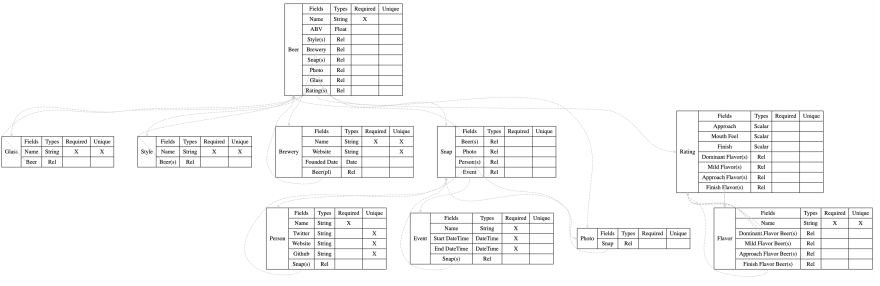
The (s|pl) plural annotation indicates one-to-many, many-to-one and many-to-many relationships. When no plural is defined it is a one-to-one relationship.
In the next few sections, I'll break down the architectural decisions behind this schema. I'll use "schema" and "content model" rather interchangeably throughout. A schema is a more technical document that maps a content model to some type of interface. As this project deals specifically with GraphQL, the word "schema" is going to get dropped, a lot. You could just as easily plan your content model as a theoretical exercise in a simple mind-mapping tool or even on paper, but since I'm implementing in a CMS, I'll be referencing that as well. But first, some general guidelines.
A.R.I.M.U
ARIMU stands for "Arbitrary Rules I Made Up" - but kidding aside, these are born from the last decade spent helping companies design and implement new CMS projects. With the flexibility of a headless CMS, we can let the domain be our guide.
Smallest Usable Component Principle

I've preached this concept far and wide by this point. While budgetary and time constraints often restrict someone from being able to practically pull this off, the general rule of thumb is to try and break your content down into the smallest usable component. A simple rule of thumb is whether or not the data model could be described as discrete, or self-contained. In this case, we abstracted the review into a standalone data model since its potentially relevant content by itself, and that lets us keep our beer data pristine. Think of the deciding factor here being objective vs subjective. We keep the beer data objective while reviews are naturally going to be subjective in nature.
Don't Repeat Yourself

Why extract "glass" or "brewery" into their own content model? Well, you could argue it from the "Smallest Usable Component" angle, but even more than that is this data is guaranteed to be shared by multiple beer entries. If you need to update a website address, you aren't going to want to update each entry where it exists.
Though you could easily do that if you're using the greatest CMS on earth. I promise I'll stop doing that. Maybe. Probably not.
Joiner Tables are Ok
If you're not familiar with a joiner table, let me explain. When you have a piece of wood with a strong arch in it and you need to make it smooth, you can run it through a tool that shaves down the ends until the "arch" disappears. That's called a joiner table. That's not what I'm talking about though. A joiner table (or Join, Joins, Joining and just plain Join) in tech terms is a database table that exists purely for the purpose of connecting two different tables together. In the case of our schema above, the "Snap" model only holds references to other models, it is, in effect, a joiner table. Database purists don't often like to create them because they can multiply quickly as a workaround to lazy table architecture. In schema design and graph thinking, if it's a mentally coherent and semantic model, it's completely ok!
Decorating for Success
When your schema design tool allows you to decorate your fields with checks and balances like required or unique - USE IT. This is particularly salient for content modeling where our resolvers can take advantage of this data and let us filter our content based on this built-in predictability. If we say a field is required, we know that we can expect that field and won't get a possible 'null' response in our data. Or if we say it's unique we know we'll get exactly 'one' record in response.
The CMS I work for, as well as some of the newer entrants to the GraphQL CMS space support variations of the same. It's powerful and not something to be overlooked.
Let's look at a few of the content models as an example.
Beer

With the beer model, I decided to track only two "own properties" - name and alcohol percentage (ABV).
Name
While there are no benefits in our tooling to define the name as required - it does give us predictability about our response, knowing that we don't need to check against null values. If we get a response object, it will have a name.
ABV
I chose to store ABV in decimal format for one primary reason, maths. It's a common best practice to store something in the smallest reasonable unit (monetary value in cents, time in seconds or even milliseconds) - it allows for easier conversions and formulations later. Also, it most often removes obfuscation as to what the value is when not tightly documented. Chances are a pair of Nike shoes cost $100 and not $10,000. Likewise, it's likely a beer is 5% alcohol and not 0.05% alcohol. No one is asking that person to buy beer for the party again.
I could have stored nutritional composition, charge date, etc - those would be unique to the beer as well. Well, perhaps charge would be stored in its own type. A charge is the batch production number for more than one unit - but it would not be likely that a charge number would have multiple entries for a personal tasting log. The domain specifies that a beer is getting reviewed and entered. Storing charge separate would be similar to expecting to buy a six-pack and logging each one as a separate entry.
At the end of the day, I'm not tracking those additional details because a) it's not really relevant for what I'm trying to accomplish and b)it would explode the scope for the project.
...rest
The remaining values are relationships in the graph such as Style, the recommended Glass and any attached Assets. We'll talk about relationship styles in the following model.
Snap

We've touched on Snap already when we covered joiner tables. In many ways, a Snap is the second most important or even equally important node to be queried from our database! And yet, it doesn't have any "own properties" outside of the standards like "datestamps for creating, reading and updating" as well as an ID. And that's ok.
What I want to point out here is the type of relationship it shares with its connected nodes.
Snaps to Beers
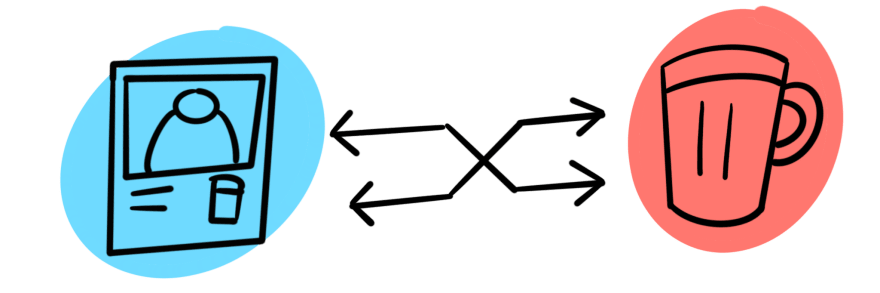
In this case, a Snap may have multiple Beer(s). I am undecided on this, to be honest. I haven't decided if the project will include the beers that other people in the photo are drinking and if that implies they can write their own reviews (meaning the need to track Person as an Author on Review) or where I want that to go. Generally I'm opposed to leaving a problem like this open, but as I am designing and implementing, I'll simply keep that in mind. The nice thing about the greatest CMS on earth, and primarily with GraphQL, is that you can modify a live schema with little effort.
Whatever the above case, it is completely likely that one Beer may end up in multiple Snaps. This relationship is many-to-many.
Snap to Photo
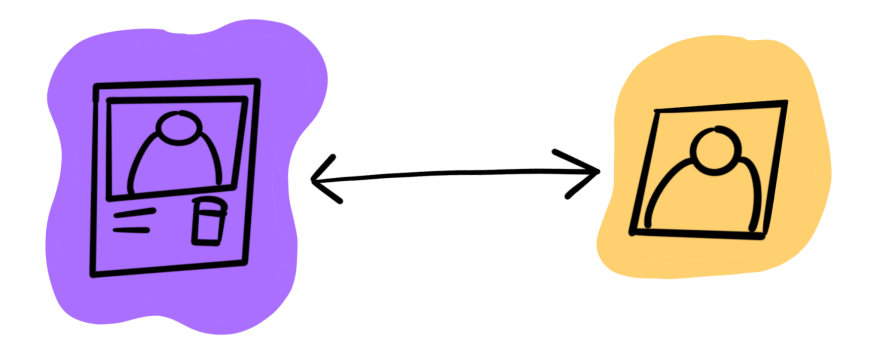
One Photo equals one Snap - this is the mental model behind this type to begin with as we often equate a "snap" with a picture. This is a one-to-one relationship.
Snaps to Persons
Multiple Person(s) could be in one Snap and one Person could be in multiple Snap(s). Again this will be a many-to-many relationship.
Many-to-Many is by far the most flexible type of relationship you can define, but it's important to fit your schema to the domain as closely as possible to prevent abuse from well-meaning content editors and to provide predictability for your developers.
Snaps to Event
In this case, a Snap will only ever belong to one Event. However, one Event will hopefully have multiple Snap(s). In this case, it is a many-to-one relationship.
Flavor

In this case, apart from the "own property" of Name, we are tracking Beer four different ways! Flavors present themselves at different time and in different ways in beer. To account for this, we are tracking them according to intensity of presence overall (character) and time (approach and finish).
What's important to note in this case is that you can completely do this in content architecture as long as you name the relationship accordingly. An example is Dominant Flavor Beers on Flavor (a many-to-many relationship because it will possibly be a dominant flavor in multiple beers) and Dominant Flavors on Beer (also a many-to-many relationship because it's possible a beer has multiple dominant flavors.)
Additional & Closing
Some final thoughts in closing.
Be careful with mixing presentational logic with your business domain
When dealing with content design, it's difficult to remove ourselves entirely from the current client we intend to consume that data. As such, it's easy to want to add presentational data such as "primary color" or "layout" to our data model. Avoid that at all costs. Better would be to maintain a separate taxonomy that maps your unique values to a set of primary colors, that taxonomy could well exist as a separate data model in your schema, but it is not data that belongs to your domain model. It's not an inherent "truth" about the data you are storing. Exceptions to that rule would be like in our beer example where one could store the color of the beer, which is a descriptor of the product itself.
Start narrow and expand
I am breaking this rule above with the Beer in Snaps example because I'll be controlling all parts of the project. But in general, prefer strict controls on the schema (required, unique, etc) than to cover all possible scenarios. It's more difficult to move in the opposite direction.
Like I said, this is a kick-off project. In the coming weeks I'll be posting various takes on the modern frameworks bouncing around Github to show how they integrate with the greatest content management system on earth.
If you have a particular framework you'd like to see featured, post it in the comments! Do you have any rules you like to apply to content modeling?
If you see me at an after-party for a conference you're at, let's grab a Beer Snap!
Cheers!

Latest comments (3)
The illustrations are boss 👍🏻. Gonna have to come back to this next time I work on a project.
Thanks! Putting illustrations out there, even if they're intentionally crude, is always a bit nerve-wracking. :)
haha true true