
I am a big proponent of always thinking about scale and optimization when you are writing code, no matter how big or small of a product you are working on. A lot of people like to argue that there is no reason to optimize when you don't have to and that is wastes time. Yes, sometimes it does take a little bit of extra time, but down the road that little bit of time can save you a huge headache.
I'm not talking about rearchitecting a whole feature, I'm talking about the little things you can do while you are coding that I guarantee will make a difference in the future. In this post, I will walk through an example of a small optimization I made recently at DEV with this pull request and how we could of avoided creating that pull request altogether.
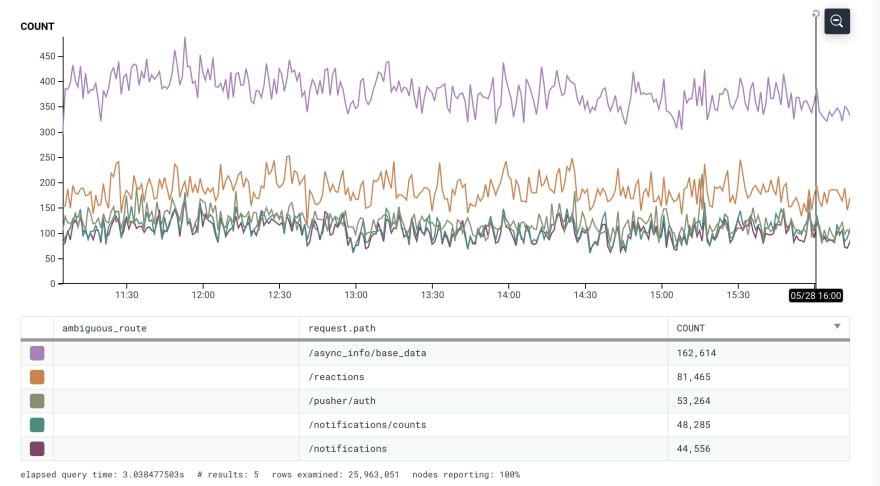
The Most Popular DEV endpoint
Every time a DEV page is loaded we make an asynchronous call to get some user data to help us populate variables in the view. This user data comes from the endpoint async_info/base_data. Because this call is made for every page load it is above and beyond our most hit endpoint. The top purple line shows the number of calls made to our async_info/base_data endpoint.
Given we call this endpoint a lot I decided to take a closer look at it to ensure it was as lean and mean as it could be. The first thing I did was checkout how we were building the hash we were returning. Here is what the hash looked like before my change:
{
id: @user.id,
name: @user.name,
username: @user.username,
profile_image_90: ProfileImage.new(@user).get(width: 90),
followed_tag_names: @user.cached_followed_tag_names,
followed_tags: @user.cached_followed_tags.to_json(only: %i[id name bg_color_hex text_color_hex hotness_score], methods: [:points]),
followed_user_ids: @user.cached_following_users_ids,
followed_organization_ids: @user.cached_following_organizations_ids,
...
}
Notice we have two different tag fields returning the same data. I do not know which one field was added first, but for the sake of this example lets say that followed_tag_names was their first.
Let's pretend...
Let's pretend you are the past developer adding the followed_tags value to the hash. You need all of the tag information in the view and not just the names, so you add the new field followed_tags to the hash. Here, is where many developers stop. They have the information they need so their work is done.

This is when I say, don't stop! Take a moment and look at your hash. You are now making TWO calls to get the same Tag information. While this may be fine when the hash is not created often, it is far from ideal when your site starts to take off and this hash is created millions of times a day. That extra call will add up. If instead of stopping, you take a few extra minutes to address this unoptimal code, you can easily solve this issue and save your future self a lot of headache.
Optimization Options
Here are the two options I considered when I was optimizing this code.
1) We could memoize the tags in a variable and then reference that variable in our hash like below. This will save us that extra database hit and ensure we don't waste resources on redundant calls.
tags = @user.cached_followed_tags
{
id: @user.id,
name: @user.name,
username: @user.username,
profile_image_90: ProfileImage.new(@user).get(width: 90),
followed_tag_names: tags.map(&:name),
followed_tags: tags.to_json(only: %i[id name bg_color_hex text_color_hex hotness_score], methods: [:points]),
followed_user_ids: @user.cached_following_users_ids,
followed_organization_ids: @user.cached_following_organizations_ids,
...
}
2) If we don't want to make the extra database call AND we want to eliminate sending duplicate information, we can solve it the way I did in the pull request. In the pull request I removed the followed_tag_names field and updated our view code to parse the JSON from the followed_tags field. I choose this because it saves us a database hit AND decreases the amount of information we are sending to and from the server.
const followedTagNames = JSON.parse(currentUser.followed_tags).map(t => t.name);
...
<ReadingList
availableTags={followedTagNames}
statusView={root.dataset.view}
/>,
TL;DR
By spending an extra couple of minutes looking at your code and thinking about scale, at the very least, you can save your future self some extra work. At the most, you could save your app from a big slow down if/when it gets hit with a large amount of growth.
HAPPY SCALING!





Top comments (2)
Plus you've pushed the processing to the client. You've distributed this little bit of "computation" as much as possible.
Do the work in the right place.
Awesome find and awesome fix.
👀 mfw I spotted that Honeycomb screenshot