
The Story
As more and more COVID-19 cases are reported each day and South Africa's lock down restrictions have been loosen, we will be seeing an increase on the number of cases due to the lack of social distancing and the usage of facial masks.
In this post, I will walk you through the processes of creating a Face Mask Detector application using pre-trained models and Intel OpenVINO toolkit with OpenCV.
This application can be improved and then integrated with CCTV or other types of cameras to detect and identify people without masks in public areas such as shopping centres and etc. The application could be useful in controlling the spread of the ever-increasing COVID-19 virus.

TL;DR
This project uses pre-trained models with OpenVINO toolkit and code can be found here
 mmphego
/
face_mask_detection_openvino
mmphego
/
face_mask_detection_openvino
Detect faces and determine whether people are wearing mask.
Face Mask Detection using OpenVINO
Face Mask Detection application uses Deep Learning/Machine Learning to recognize if a user is not wearing a mask and issues an alert.
By utilizing pre-trained models and Intel OpenVINO toolkit with OpenCV. This enables us to use the async API which can improve overall frame-rate of the application, rather than wait for inference to complete, the application can continue operating on the host while accelerator is busy.
This application executes 2 parallel infer requests for the Face Mask Detection and Face Detection networks that run simultaneously.
Using a set of the following pre-trained models:
- face-detection-adas-0001, which is a primary detection network for finding faces.
- face-mask-detection, which is a pretrained model for detecting a mask.
This application can be improved and then integrated with CCTV or other types cameras to detect and identify people without masks in public areas such as shopping centers and etc. This…
The How
Using the OpenVINO async API we can improve the overall frame-rate of the application, because rather than to wait for inference to complete, the application can continue operating on the host while the CPU is busy.
This walk-through executes 2 parallel inference requests for the Face Mask Detection and Face Detection networks that run simultaneously.
Using a set of the following pre-trained models:
-
face-detection-adas-0001, which is a primary detection network for finding faces. - face-mask-detection, which is a pre-trained model for detecting a mask.
The Walk-through
Face Mask Detection application uses Deep Learning/Machine Learning to recognize if a user is not wearing a mask and issues an alert as shown in the image below.
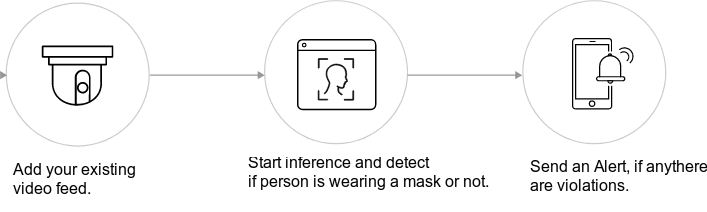
Code walk-through
Watch the complete tutorial and code walk-through. Positive and building comments will be appreciated
The code which contains voice alert.
#!/usr/bin/env python3
import time
import os
from argparse import ArgumentParser
import cv2
import numpy as np
from responsive_voice.voices import UKEnglishMale
from inference import Network
engine = UKEnglishMale()
mp3_file = engine.get_mp3("Please wear your MASK!!")
def arg_parser():
"""Parse command line arguments.
:return: command line arguments
"""
parser = ArgumentParser()
parser.add_argument(
"-f",
"--face-model",
required=True,
type=str,
help="Path to an xml file with a trained model.",
)
parser.add_argument(
"-m",
"--mask-model",
required=True,
type=str,
help="Path to an xml file with a trained model.",
)
parser.add_argument(
"-i",
"--input",
required=True,
type=str,
help="Path to image or video file or 'cam' for Webcam.",
)
parser.add_argument(
"-d",
"--device",
type=str,
default="CPU",
help="Specify the target device to infer on: "
"CPU, GPU, FPGA or MYRIAD is acceptable. Sample "
"will look for a suitable plugin for device "
"specified (CPU by default)",
)
parser.add_argument(
"-pt",
"--prob_threshold",
type=float,
default=0.8,
help="Probability threshold for detections filtering" "(0.8 by default)",
)
parser.add_argument(
"--out", action="store_true", help="Write video to file.",
)
parser.add_argument(
"--ffmpeg", action="store_true", help="Flush video to FFMPEG.",
)
parser.add_argument(
"--debug", action="store_true", help="Show output on screen [debugging].",
)
return parser.parse_args()
def draw_boxes(frame, f_result, m_result, count, prob_threshold, width, height):
"""Draw bounding boxes onto the frame."""
loc = 20
for box in f_result[0][0]: # Output shape is 1x1x100x7
conf = box[2]
if conf >= prob_threshold:
xmin = int(box[3] * width)
ymin = int(box[4] * height)
xmax = int(box[5] * width)
ymax = int(box[6] * height)
_y = ymax + loc if ymax + loc > loc else ymax - loc
detected_threshold = round(float(m_result.flatten()), 3)
if detected_threshold > 0.3:
label = ("Mask", (0, 255, 0)) # Color format: BGR
else:
label = ("No Mask", (0, 0, 255))
if int(count) % 200 == 1:
engine.play_mp3(mp3_file)
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), label[1], 1)
cv2.putText(
frame,
f"{label[0]}: {detected_threshold :.2f}%",
(xmin - 2 * loc, _y),
cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.5,
color=label[1],
thickness=2,
)
return frame
def process_frame(frame, height, width):
"""Helper function for processing frame"""
p_frame = cv2.resize(frame, (width, height))
# Change data layout from HWC to CHW
p_frame = p_frame.transpose((2, 0, 1))
p_frame = p_frame.reshape(1, *p_frame.shape)
return p_frame
def infer_on_stream(args):
"""
Initialize the inference network, stream video to network,
and output stats and video.
:param args: Command line arguments parsed by `build_argparser()`
:param client: MQTT client
:return: None
"""
# Initialise the class
face_infer_network = Network()
mask_infer_network = Network()
# Set Probability threshold for detections
prob_threshold = args.prob_threshold
try:
mask_infer_network.load_model(
model_xml=args.mask_model,
device=args.device,
)
face_infer_network.load_model(
model_xml=args.face_model,
device=args.device,
)
except Exception:
raise
if args.input.lower() == "cam":
video_file = 0
else:
video_file = args.input
assert os.path.isfile(video_file)
stream = cv2.VideoCapture(video_file)
stream.open(video_file)
# Grab the shape of the input
orig_width = int(stream.get(3))
orig_height = int(stream.get(4))
average_infer_time = []
_, _, input_height, input_width = face_infer_network.get_input_shape()
_, _, mask_input_height, mask_input_width = mask_infer_network.get_input_shape()
if not stream.isOpened():
msg = "Cannot open video source!!!"
raise RuntimeError(msg)
count = 0
while stream.isOpened():
# Grab the next stream.
(grabbed, frame) = stream.read()
# If the frame was not grabbed, then we might have reached end of steam,
# then break
if not grabbed:
break
count += 1
p_frame = process_frame(frame, input_height, input_width)
m_frame = process_frame(frame, mask_input_height, mask_input_width)
start_infer = time.time()
face_infer_network.exec_net(p_frame)
mask_infer_network.exec_net(m_frame)
if face_infer_network.wait() == 0 and mask_infer_network.wait() == 0:
f_result = face_infer_network.get_output()
m_result = mask_infer_network.get_output()
end_infer = time.time() - start_infer
average_infer_time.append(end_infer)
message = f"Inference time: {end_infer*1000:.2f}ms"
cv2.putText(
frame, message, (20, 20), cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 0, 0), 1
)
# Draw the boxes onto the input
out_frame = draw_boxes(
frame,
f_result,
m_result,
count,
prob_threshold,
orig_width,
orig_height,
)
if args.debug:
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# # if the `q` key was pressed, break from the loop
if key == ord("q"):
break
# Release the out writer, capture, and destroy any OpenCV windows
stream.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
# Grab command line args
args = arg_parser()
# Perform inference on the input stream
infer_on_stream(args)
Running the application
- Download the docker images with a pre-installed version of OpenVINO 2020.2
docker pull mmphego/intel-openvino
- Download the facemask detection model.
wget https://github.com/didi/maskdetection/raw/master/model/face_mask.caffemodel
wget https://raw.githubusercontent.com/didi/maskdetection/master/model/deploy.prototxt
- Convert model to OpenVINO's
Intermediate Representations(IR) using theModel Optimizer, which will produce.xmland.binfiles.
docker run --rm -ti \
--volume "$PWD":/app \
--env DISPLAY=$DISPLAY \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw" \
mmphego/intel-openvino \
bash -c "/opt/intel/openvino/deployment_tools/model_optimizer/mo.py \
--framework caffe \
--input_model face_mask.caffemodel \
--input_proto deploy.prototxt"
- Download face detection model from the model zoo, which will produce
.xmland.binfiles.
docker run --rm -ti \
--volume "$PWD":/app \
--env DISPLAY=$DISPLAY \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw" \
mmphego/intel-openvino \
bash -c "/opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py \
--name face-detection-adas-0001 \
--precision FP16"
Usage
xhost +;
docker run --rm -ti \
--volume "$PWD":/app \
--env DISPLAY=$DISPLAY \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw" \
--device /dev/snd \
--device /dev/video0 \
mmphego/intel-openvino \
bash -c \
"source /opt/intel/openvino/bin/setupvars.sh && \
python main.py \
--face-model models/face-detection-adas-0001.xml \
--mask-model models/face_mask.xml \
--debug \
-i resources/mask.mp4"
xhost -;
-
--env DISPLAY=$DISPLAY: Enables GUI applications -
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw": Enable GUI applications -
--device /dev/snd: Enable sound from container -
--device /dev/video0: Share webcam with container
Reference
- Face mask detection caffe model: https://github.com/didi/maskdetection
- COVID-19: Face Mask Detector with OpenCV, Keras/TensorFlow, and Deep Learning by Adrian Rosebrock

Top comments (0)