This is a Plain English Papers summary of a research paper called Study Shows Major AI Models Fail at Most Chinese Minority Languages, GPT-4 Leads Limited Success. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
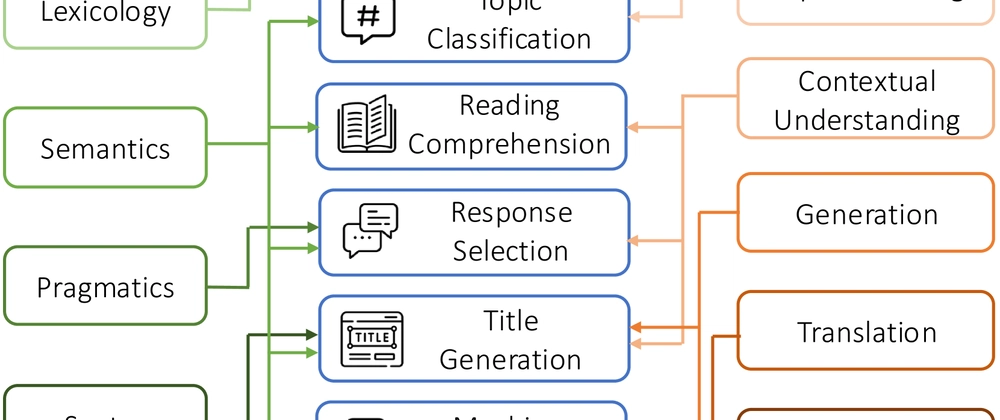
- MiLiC-Eval evaluates LLMs on China's minority languages
- Covers 8 languages including Tibetan, Mongolian, Uyghur, Kazakh, Korean, Yi, Zhuang, and Dai
- First benchmark focusing on China's ethnic minority languages
- Tests 13 multilingual LLMs including GPT-4, Claude, Llama-3, and others
- Finds significant performance gaps between major and minority languages
- Results show poor performance on Yi, Zhuang, and Dai languages
- GPT-4o emerges as best performer across most tasks
Plain English Explanation
China has 56 ethnic groups and many languages, but LLMs (Large Language Models) like ChatGPT mainly focus on major languages like English and Chinese. This research introduces MiLiC-Eval, the first benchmark to test how well AI models handle China's minority languages.
The tea...

Top comments (0)