This is a Plain English Papers summary of a research paper called Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper explores the impact of input length on the reasoning performance of large language models (LLMs) when completing the same task.
- The researchers investigate how increasing the amount of textual input affects an LLM's ability to reason and provide accurate responses.
- They examine factors like the model's capacity to maintain context, extract relevant information, and draw logical conclusions from longer inputs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. Researchers in this study wanted to see how the length of the text given to an LLM affects its ability to reason and provide accurate responses.
Typically, LLMs are trained on large amounts of text data, which allows them to learn patterns and relationships in language. However, when presented with longer input texts, LLMs may struggle to maintain the full context and extract the most relevant information to answer a question or complete a task.
The researchers in this paper explored what happens when you give an LLM more text to work with - does it perform better at reasoning and providing accurate responses? They designed experiments to test this by giving the same task to the LLM but with varying amounts of input text.
By understanding the impact of input length on LLM reasoning, we can learn more about the capabilities and limitations of these powerful AI systems. This knowledge can then inform how we design tasks and prompts to get the best performance from LLMs in real-world applications.
Technical Explanation
The researchers conducted a series of experiments to investigate the impact of input length on the reasoning performance of large language models (LLMs). They used a diverse set of reasoning tasks, including question answering, logical inference, and common sense reasoning.
For each task, the researchers varied the length of the input text provided to the LLM, ranging from short prompts to longer, more contextual passages. They then compared the model's performance across these different input lengths to understand how the amount of textual information affects its ability to reason and provide accurate responses.
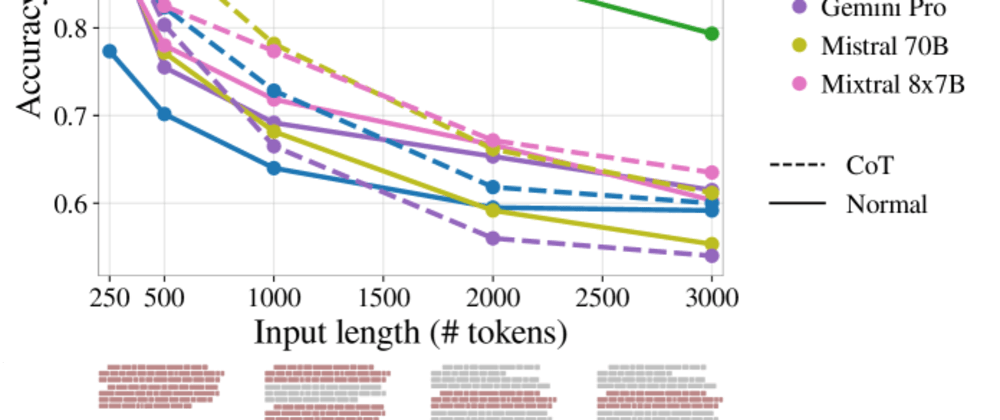
The results showed that, in general, increasing the input length led to improved reasoning performance for the LLMs. With more context to draw from, the models were better able to maintain the relevant information, extract the most salient details, and apply logical reasoning to arrive at the correct answer.
However, the researchers also observed that there were practical limits to the performance gains from longer inputs. At a certain point, the models began to struggle to effectively process and integrate the additional information, leading to diminishing returns or even decreased accuracy.
These findings align with previous research on the challenges LLMs face with long-context learning and the need for techniques to extend the context capabilities of these models.
The researchers also discussed potential approaches, such as the XL3M framework and the BabiLong system, which aim to address the limitations of LLMs in handling long-form inputs and reasoning over extended contexts.
Critical Analysis
The researchers in this paper provide valuable insights into the impact of input length on the reasoning performance of large language models (LLMs). Their experimental design and analysis offer a nuanced understanding of the capabilities and limitations of these AI systems when faced with varying levels of contextual information.
One potential area for further research is the exploration of task-specific differences in the relationship between input length and reasoning performance. The paper suggests that certain types of reasoning tasks may be more or less sensitive to changes in input length, and a deeper investigation into these task-specific dynamics could yield additional insights.
Additionally, the researchers acknowledge the need for continued advancements in techniques to extend the context capabilities of LLMs, as the practical limits observed in their experiments highlight the ongoing challenges in this area. Exploring and evaluating emerging approaches, such as the XL3M framework and BabiLong system, could help advance the state of the art in long-context reasoning for large language models.
Overall, this paper contributes to our understanding of the factors that influence the reasoning capabilities of LLMs, which is crucial as these models become increasingly prevalent in real-world applications. By critically examining the impact of input length, the researchers provide a foundation for the development of more robust and adaptable language models that can effectively reason across a wide range of contexts.
Conclusion
This research paper provides valuable insights into the impact of input length on the reasoning performance of large language models (LLMs). The findings suggest that increasing the amount of textual information available to an LLM can generally improve its ability to reason and provide accurate responses, but there are practical limits to these performance gains.
By understanding the relationship between input length and reasoning, researchers and practitioners can develop more effective strategies for designing tasks and prompts that leverage the full capabilities of LLMs. This knowledge can also inform the development of advanced techniques, such as the XL3M framework and BabiLong system, which aim to extend the context handling abilities of these powerful AI models.
As large language models continue to play a crucial role in various applications, this research contributes to the ongoing efforts to push the boundaries of their reasoning and context-processing capabilities. By critically examining the factors that influence LLM performance, the scientific community can work towards building more robust and adaptable language models that can reliably reason and make decisions across a wide range of real-world scenarios.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)