This is a Plain English Papers summary of a research paper called JetMoE: Reaching Llama2 Performance with 0.1M Dollars. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- Introduces a new language model called JetMoE that can match the performance of Llama2 while costing only $0.1 million to train
- Leverages a Mixture of Experts (MoE) architecture to achieve high performance with a much smaller model size
- Demonstrates impressive results on a variety of benchmarks, rivaling the performance of larger language models like Llama2
Plain English Explanation
The paper introduces a new language model called JetMoE that can achieve similar performance to the powerful Llama2 model, but at a fraction of the cost. Llama2 is a highly capable language model that requires significant computational resources to train, on the order of millions of dollars. In contrast, the researchers behind JetMoE were able to train their model for just $0.1 million.
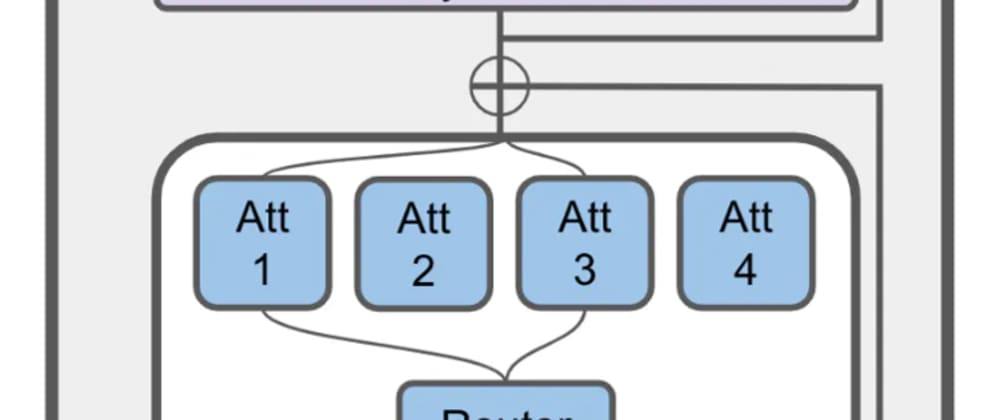
The key to JetMoE's efficiency is its use of a Mixture of Experts (MoE) architecture. Rather than having a single large neural network, MoE models use a collection of smaller "expert" networks that each specialize in different tasks or types of information. During inference, the model dynamically selects the most appropriate experts to use for a given input, allowing it to leverage its specialized knowledge while remaining compact.
This approach allows JetMoE to achieve Llama2-level performance without requiring the same massive model size and computational resources. The researchers demonstrate that JetMoE performs on par with Llama2 on a variety of benchmarks, including language understanding, generation, and reasoning tasks. This is an impressive feat considering the significant cost and resource differences between the two models.
The success of JetMoE highlights the potential of efficient Mixture of Experts architectures for building highly capable language models at a much lower cost. It also raises interesting questions about the role of prompting and prompt-based adaptation in enabling small models to achieve large-language-model-level performance.
Technical Explanation
The key innovation in the JetMoE model is its use of a Mixture of Experts (MoE) architecture. Rather than a single large neural network, JetMoE consists of a collection of smaller "expert" networks that each specialize in different tasks or types of information. During inference, the model dynamically selects the most appropriate experts to use for a given input, allowing it to leverage its specialized knowledge while remaining compact.
The MoE architecture is implemented as follows:
- The input is first processed by a shared "trunk" network, which extracts general features.
- The trunk output is then fed into a gating network, which determines how to weight and combine the different expert networks.
- The weighted expert outputs are then combined to produce the final model output.
This allows JetMoE to achieve high performance without requiring a single large monolithic network. The researchers demonstrate that JetMoE can match the performance of Llama2 on a variety of benchmarks, including language understanding, generation, and reasoning tasks, while having a much smaller model size and training cost.
The researchers also explore the role of prompt-based adaptation in enabling JetMoE to achieve Llama2-level performance. By fine-tuning the model on carefully crafted prompts, they are able to further enhance its capabilities without increasing the model size.
Overall, the JetMoE model represents an exciting advance in efficient language modeling, demonstrating that Mixture of Experts architectures can be a powerful tool for building highly capable models at a fraction of the cost of traditional approaches.
Critical Analysis
The JetMoE paper presents a compelling approach to building efficient language models, but it is important to consider some potential limitations and areas for further research.
One potential concern is the reliance on prompt-based adaptation to achieve Llama2-level performance. While this technique is effective, it raises questions about the stability and generalization of the model's capabilities. It's possible that the model may be overly specialized to the specific prompts used during fine-tuning, which could limit its broader applicability.
Additionally, the paper does not provide a detailed analysis of the computational efficiency of the JetMoE model during inference. While the training cost is significantly lower than Llama2, the runtime performance and energy efficiency of the model during deployment are also important considerations, especially for real-world applications.
Further research could also explore the scalability of the MoE approach, as the number of experts and the complexity of the gating network may become a bottleneck as the model size increases. [Techniques like TeenyTinyLLaMA could be leveraged to address this challenge.
Finally, it would be valuable to see how JetMoE performs on a broader range of tasks and datasets, beyond the specific benchmarks reported in the paper. This could provide a more comprehensive understanding of the model's strengths, weaknesses, and potential use cases.
Conclusion
The JetMoE model представs an exciting development in the field of efficient language modeling. By leveraging a Mixture of Experts architecture, the researchers were able to achieve Llama2-level performance at a fraction of the training cost, demonstrating the potential of this approach to democratize access to powerful language models.
The success of JetMoE highlights the importance of continued research into innovative model architectures and efficient training techniques for language models. As the field continues to evolve, models like JetMoE could play a crucial role in making advanced language capabilities more widely available and accessible to a diverse range of applications and users.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)