This is a Plain English Papers summary of a research paper called From Model-centered to Human-Centered: Revision Distance as a Metric for Text Evaluation in LLMs-based Applications. If you like these kinds of analysis, you should subscribe to the AImodels.fyi newsletter or follow me on Twitter.
Overview
- This paper proposes using "revision distance" as a metric to evaluate the quality of text generated by large language models (LLMs) from a human-centric perspective.
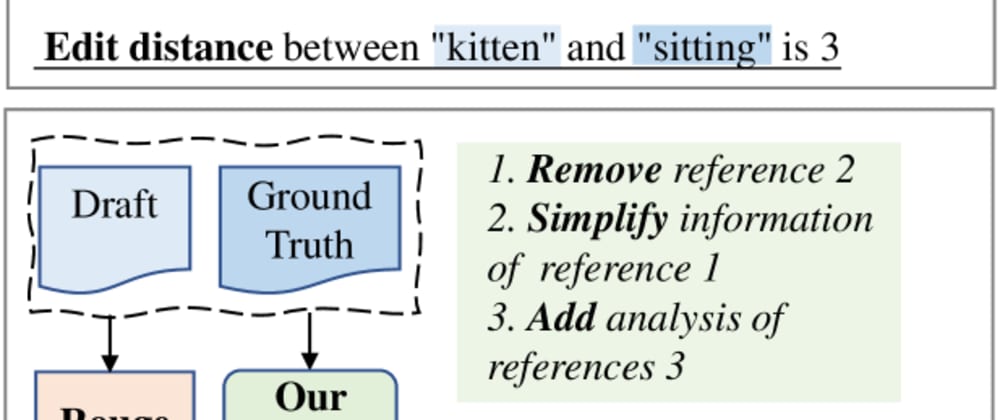
- Revision distance measures how much a human needs to edit the generated text to make it satisfactory, which the authors argue is a more meaningful metric than model-centric metrics like perplexity.
- The paper explores applications of revision distance in various LLM-based tasks, including text generation, summarization, and question answering.
Plain English Explanation
The paper is about finding a better way to evaluate the performance of large language models (LLMs) - the powerful AI systems that can generate human-like text. Traditional metrics used to assess LLMs, like "perplexity," focus on how well the model predicts the next word in a sequence. However, the authors argue that these model-centric metrics don't necessarily reflect how useful the generated text is from a human user's perspective.
Instead, the researchers propose using a metric called "revision distance" to evaluate LLMs. Revision distance measures how much a person would need to edit or revise the text generated by an LLM to make it satisfactory. The idea is that the less a human needs to change the text, the better the LLM has performed.
The paper explores applying revision distance to various LLM-based applications, such as generating original text, summarizing long documents, and answering questions. The key advantage of this human-centric approach is that it aligns more closely with the real-world usefulness of the LLM's output, rather than just its technical prowess.
Technical Explanation
The paper introduces "revision distance" as a new metric for evaluating the performance of large language models (LLMs) in text generation tasks. Revision distance measures the editing effort required for a human to make the LLM-generated text satisfactory, which the authors argue is a more meaningful evaluation than traditional model-centric metrics like perplexity.
To calculate revision distance, the researchers have human annotators make edits to the LLM-generated text until it meets their quality standards. The number of edits required is then used as the revision distance score. The authors explore applying revision distance to various LLM-based applications, including text generation, summarization, and question answering.
The key insight is that revision distance captures the human user's experience with the LLM's output, rather than just the model's internal perfor-mance. This human-centric perspective is argued to be more relevant for real-world applications of LLMs, where the ultimate goal is to generate text that requires minimal editing by end-users.
Critical Analysis
The paper makes a compelling case for using revision distance as a complement to traditional evaluation metrics for LLMs. By focusing on the human user's experience, revision distance provides a more holistic and meaningful assessment of an LLM's performance.
However, the authors acknowledge some limitations of their approach. Collecting human annotations to calculate revision distance can be time-consuming and resource-intensive, especially at scale. Additionally, the subjective nature of what constitutes "satisfactory" text may introduce some variability in the revision distance scores.
It would also be valuable to further explore how revision distance relates to other model attributes, such as coherence, factual accuracy, and fluency. Understanding these relationships could help developers optimize LLMs for real-world usability.
Overall, the revision distance metric proposed in this paper represents an important step towards a more human-centered approach to evaluating large language models. As LLMs become increasingly prevalent in various applications, such user-focused evaluation methods will be crucial for ensuring they deliver meaningful value to end-users.
Conclusion
This paper introduces "revision distance" as a novel metric for evaluating the performance of large language models (LLMs) from a human-centric perspective. By measuring the editing effort required for a person to make the LLM-generated text satisfactory, revision distance provides a more meaningful assessment of the model's real-world usefulness compared to traditional model-centric metrics.
The authors demonstrate the application of revision distance across various LLM-based tasks, including text generation, summarization, and question answering. While the approach has some practical limitations, it represents an important step towards aligning LLM evaluation with the needs and experiences of human users. As LLMs become more widely deployed, such human-centered evaluation methods will be critical for ensuring these powerful AI systems deliver tangible benefits to end-users.
If you enjoyed this summary, consider subscribing to the AImodels.fyi newsletter or following me on Twitter for more AI and machine learning content.





Top comments (0)