This is a Plain English Papers summary of a research paper called Dynamic Query Grouping Makes AI 2x Faster with Long Text. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
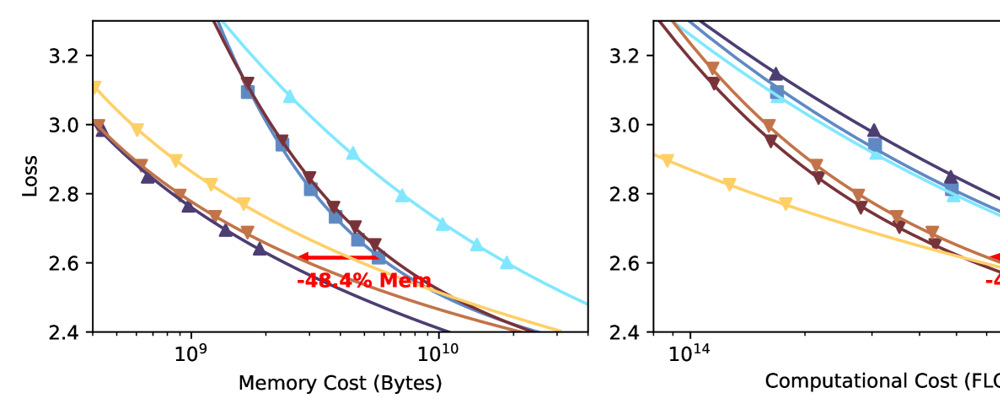
- GQA (Grouped-Query Attention) reduces training costs but doesn't optimize for inference
- Cost-Optimal GQA (COGQA) adapts group sizes based on sequence length
- COGQA achieves 1.8× faster inference without quality loss
- Dynamically adjusts query-head group sizes during different processing phases
- Works especially well for long-context (100K+ tokens) language models
- Maintains model quality while improving computational efficiency
Plain English Explanation
Large language models (LLMs) like GPT-4 need to process and "pay attention to" huge amounts of text. The way they handle this attention is crucial for both how well they work and how expensive they are to run.
Traditional LLMs use something called Multi-Head Attention (MHA), w...

Top comments (0)