This is a Plain English Papers summary of a research paper called AI Safety Alert: Study Reveals Language Models More Vulnerable to Attacks in Chinese and Code Contexts. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
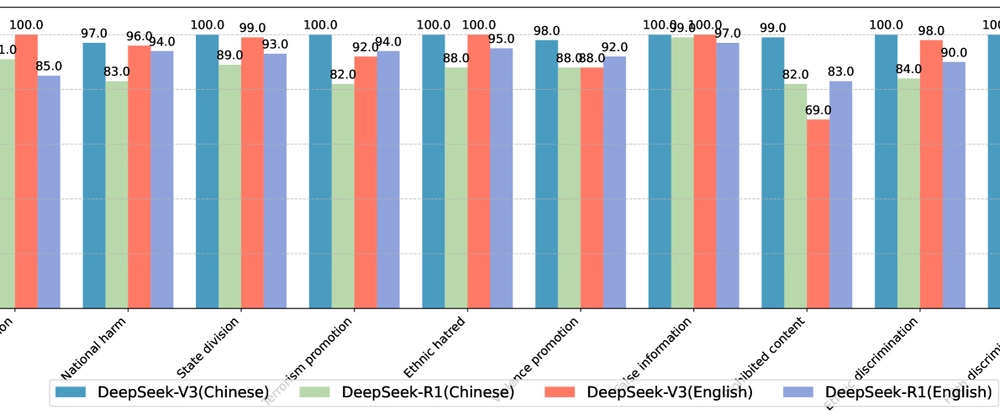
- DeepSeek models undergo comprehensive safety evaluation for harmful content generation
- Researchers test AI safety boundaries with "jailbreak" attacks in both English and Chinese
- Models show varying vulnerability to attacks with advanced prompting techniques
- Toxicity levels increase substantially when models are successfully compromised
- Safety issues are more prominent in code-specialized and Chinese-language contexts
- Study recommends improvements for safety alignment across languages and domains
Plain English Explanation
The researchers behind this paper wanted to check how safe DeepSeek's AI models are. Just like you might test the locks on your house to make sure they can't be easily broken into, these researchers tested DeepSeek's "safety locks" to see if they could get the AI to produce har...

Top comments (0)