
Let’s see how Metis can prevent, monitor, and troubleshoot our databases. In this part we’re going to prepare a database based on IMDb and start with sample queries to see actual examples. We are going to see actual insights provided by Metis and how they improve the query performance.
Introduction
Metis can analyze queries, suggest improvements, find performance issues, and automatically troubleshoot problems. We are going to use IMDb datasets. We are going to play with some queries, and see how Metis can identify performance characteristics.
You can find the datasets at IMDb datasets.
Information courtesy of IMDb. Used with permission.
Dataset preparation
Let’s start with preparing the database. We are going to use the PostgreSQL (Postgres) database.
Let’s start with downloading files:
curl --output name.basics.tsv.gz https://datasets.imdbws.com/name.basics.tsv.gz \
&& curl --output title.akas.tsv.gz https://datasets.imdbws.com/title.akas.tsv.gz \
&& curl --output title.basics.tsv.gz https://datasets.imdbws.com/title.basics.tsv.gz \
&& curl --output title.crew.tsv.gz https://datasets.imdbws.com/title.crew.tsv.gz \
&& curl --output title.episode.tsv.gz https://datasets.imdbws.com/title.episode.tsv.gz \
&& curl --output title.principals.tsv.gz https://datasets.imdbws.com/title.principals.tsv.gz \
&& curl --output title.ratings.tsv.gz https://datasets.imdbws.com/title.ratings.tsv.gz
Next, we need to decompress them:
gzip -d name.basics.tsv.gz \
&& gzip -d title.akas.tsv.gz \
&& gzip -d title.basics.tsv.gz \
&& gzip -d title.crew.tsv.gz \
&& gzip -d title.episode.tsv.gz \
&& gzip -d title.principals.tsv.gz \
&& gzip -d title.ratings.tsv.gz
Next, we need to replace \N characters with empty values in order to import them as NULLs:
sed 's/\\N//g' name.basics.tsv > name.basics.tsv2 \
&& sed 's/\\N//g' title.akas.tsv > title.akas.tsv2 \
&& sed 's/\\N//g' title.basics.tsv > title.basics.tsv2 \
&& sed 's/\\N//g' title.crew.tsv > title.crew.tsv2 \
&& sed 's/\\N//g' title.episode.tsv > title.episode.tsv2 \
&& sed 's/\\N//g' title.principals.tsv > title.principals.tsv2 \
&& sed 's/\\N//g' title.ratings.tsv > title.ratings.tsv2 \
&& rm *.tsv
Now, we need to create a database in our PostgreSQL instance. You can install the server locally or use the Docker image. Next, create the schema:
CREATE SCHEMA imdb;
And now create tables. We are going to use TEXT columns to keep things simple:
CREATE TABLE imdb.name_basics(
nconst TEXT NOT NULL PRIMARY KEY,
primaryName TEXT,
birthYear INT,
deathYear INT,
primaryProfession TEXT,
knownForTitles TEXT
);
CREATE TABLE imdb.title_akas(
titleId TEXT NOT NULL,
ordering INT NOT NULL,
title TEXT,
region TEXT,
language TEXT,
types TEXT,
attributes TEXT,
isOriginalTitle BIT,
constraint pk_title_akas PRIMARY KEY (titleId, ordering)
);
CREATE TABLE imdb.title_basics(
tconst TEXT NOT NULL PRIMARY KEY,
titleType TEXT,
primaryTitle TEXT,
originalTitle TEXT,
isAdult BIT,
startYear INT,
endYear INT,
runtimeMinutes INT,
genres TEXT
);
CREATE TABLE imdb.title_crew(
tconst TEXT NOT NULL PRIMARY KEY,
directors TEXT,
writers TEXT
);
CREATE TABLE imdb.title_episode(
tconst TEXT NOT NULL PRIMARY KEY,
partentTconst TEXT,
seasonNumber INT,
episodeNumber INT
);
CREATE TABLE imdb.title_principals (
tconst TEXT NOT NULL,
ordering INT NOT NULL,
nconst TEXT,
category TEXT,
job TEXT,
characters TEXT,
constraint pk_title_principals PRIMARY KEY (tconst, ordering)
);
CREATE TABLE imdb.title_ratings (
tconst TEXT NOT NULL PRIMARY KEY,
averageRating NUMERIC(15, 8),
numVotes BIGINT
);
Finally, we need to load the IMDb database:
COPY imdb.name_basics FROM '/database/name.basics.tsv2' DELIMITER E'\t' QUOTE E'\b' CSV HEADER;
COPY imdb.title_akas FROM '/database/title.akas.tsv2' DELIMITER E'\t' QUOTE E'\b' CSV HEADER;
COPY imdb.title_basics FROM '/database/title.basics.tsv2' DELIMITER E'\t' QUOTE E'\b' CSV HEADER;
COPY imdb.title_crew FROM '/database/title.crew.tsv2' DELIMITER E'\t' QUOTE E'\b' CSV HEADER;
COPY imdb.title_episode FROM '/database/title.episode.tsv2' DELIMITER E'\t' QUOTE E'\b' CSV HEADER;
COPY imdb.title_principals FROM '/database/title.principals.tsv2' DELIMITER E'\t' QUOTE E'\b' CSV HEADER;
COPY imdb.title_ratings FROM '/database/title.ratings.tsv2' DELIMITER E'\t' QUOTE E'\b' CSV HEADER;
The database is now ready and we can remove the input files:
rm *.tsv2
rm *.tsv
rm *.tsv.gz
Registering in Metis
You can now go to Metis and register.
You are now ready to query the database. Start with a very simple query:
SELECT *
FROM imdb.name_basics
LIMIT 1
This should give the following output:
+-----------+--------------+------------+-----------+--------------------------------+-----------------------------------------+
| nconst | primaryname | birthyear | deathyear | primaryprofession | knownfortitles |
+-----------+--------------+------------+-----------+--------------------------------+-----------------------------------------+
| nm0000001 | Fred Astaire | 1899 | 1987 | soundtrack,actor,miscellaneous | tt0045537,tt0050419,tt0053137,tt0072308 |
+-----------+--------------+------------+-----------+--------------------------------+-----------------------------------------+
Now, we can get the execution plan for the query above. Let’s change the query to:
EXPLAIN (VERBOSE, BUFFERS, COSTS, FORMAT JSON)
SELECT *
FROM imdb.name_basics
LIMIT 1
We should get something along the lines:
[
{
"Plan": {
"Node Type": "Limit",
"Parallel Aware": false,
"Async Capable": false,
"Startup Cost": 0.00,
"Total Cost": 0.02,
"Plan Rows": 1,
"Plan Width": 66,
"Output": ["nconst", "primaryname", "birthyear", "deathyear", "primaryprofession", "knownfortitles"],
"Shared Hit Blocks": 0,
"Shared Read Blocks": 0,
"Shared Dirtied Blocks": 0,
"Shared Written Blocks": 0,
"Local Hit Blocks": 0,
"Local Read Blocks": 0,
"Local Dirtied Blocks": 0,
"Local Written Blocks": 0,
"Temp Read Blocks": 0,
"Temp Written Blocks": 0,
"Plans": [
{
"Node Type": "Seq Scan",
"Parent Relationship": "Outer",
"Parallel Aware": false,
"Async Capable": false,
"Relation Name": "name_basics",
"Schema": "imdb",
"Alias": "name_basics",
"Startup Cost": 0.00,
"Total Cost": 253832.48,
"Plan Rows": 12416948,
"Plan Width": 66,
"Output": ["nconst", "primaryname", "birthyear", "deathyear", "primaryprofession", "knownfortitles"],
"Shared Hit Blocks": 0,
"Shared Read Blocks": 0,
"Shared Dirtied Blocks": 0,
"Shared Written Blocks": 0,
"Local Hit Blocks": 0,
"Local Read Blocks": 0,
"Local Dirtied Blocks": 0,
"Local Written Blocks": 0,
"Temp Read Blocks": 0,
"Temp Written Blocks": 0
}
]
},
"Query Identifier": -599869187636405422,
"Planning": {
"Shared Hit Blocks": 0,
"Shared Read Blocks": 0,
"Shared Dirtied Blocks": 0,
"Shared Written Blocks": 0,
"Local Hit Blocks": 0,
"Local Read Blocks": 0,
"Local Dirtied Blocks": 0,
"Local Written Blocks": 0,
"Temp Read Blocks": 0,
"Temp Written Blocks": 0
}
}
]
We can see how the SQL engine is going to execute the query. This is only the estimated plan, and the actual execution may differ. To get the actual plan, we can run this:
EXPLAIN (ANALYZE, TIMING, VERBOSE, BUFFERS, COSTS, FORMAT JSON)
SELECT *
FROM imdb.name_basics
LIMIT 1
You can now copy the query and the execution plan to Metis Query Analyzer and get the following:

Let’s now see what environment I used for the experiments.
Platform
I used the following environment to run the tests below.
- RDS instance
db.m6g.largewithPostgreSQL 13.7. It has 2 vCPUs and 8 GB of RAM. - EC2 instance
t3.xlargewith AMIamzn2-ami-kernel-5.10-hvm-2.0.20221210.1-x86_64-gp2withAmazon Linux 2in version5.10.157-139.675.amzn2.x86_64. It has 4 vCPUs and 16 GB of RAM memory. - Mac Mini with
macOS 13 Venturarunning on M1 withDarwin Kernel Version 22.4.0. It has 3.2GHz 8-Core M1 and 16GB of RAM.
Both EC2 and Mac used PostgreSQL 15.2 (Debian 15.2-1.pgdg110+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit running in a Docker container that you can get at public.ecr.aws/o2c0x5x8/metis-demo-db:latest.
For a given actor, find their latest movies
First query I used shows some latest movies a given actor has been in. This is the query:
SELECT TB.*
FROM name_basics AS NB
LEFT JOIN title_principals AS TP ON TP.nconst = NB.nconst
LEFT JOIN title_basics AS TB ON TB.tconst = TP.tconst
WHERE NB.nconst = 'nm1588970'
ORDER BY TB.startyear DESC
LIMIT 10
And here is the output:
+------------+------------+-----------------------+-----------------------+----------+------------+----------+-----------------+-------------------+
| tconst | titletype | primarytitle | originaltitle | isadult | startyear | endyear | runtimeminutes | genres |
+------------+------------+-----------------------+-----------------------+----------+------------+----------+-----------------+-------------------+
| tt7513040 | short | Den gamla goda tiden | Den gamla goda tiden | false | 1946 | (null) | 6 | Documentary,Short |
| tt0000001 | short | Carmencita | Carmencita | false | 1894 | (null) | 1 | Documentary,Short |
+------------+------------+-----------------------+-----------------------+----------+------------+----------+-----------------+-------------------+
Execution time:
+------+------+-----+
| EC2 | RDS | Mac |
+------+------+-----+
| 37 | 31 | 24 |
+------+------+-----+
Let’s start with the estimated plan:
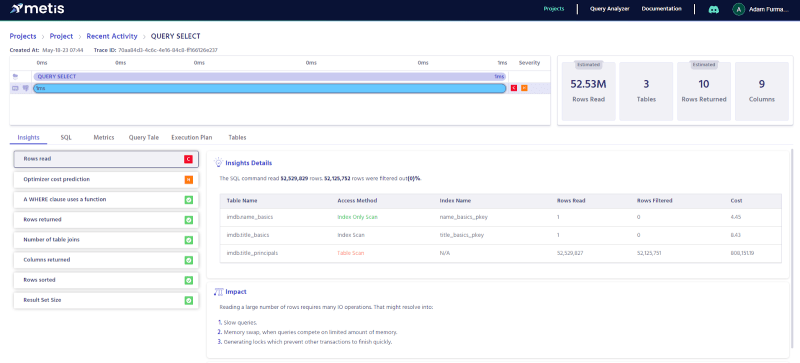
We can see that the SQL engine predicts using 3 tables, reading ~52M rows, and returning 10 of them. Let’s compare that with the actual:

We can see that the estimations were pretty accurate. The actual number of rows was closer to 56M, and the query returned 2 rows instead of 10.
However, based on the insights above, we can easily tell how to improve the performance. imdb.title_principals doesn’t have an index. If we go to the Query Tale tab, we can see that it scans the table:

How can we improve the query? Metis clearly indicates that a table is scanned and this decreases the performance! Let’s add the index:
CREATE INDEX IF NOT EXISTS title_principals_nconst_idx ON imdb.title_principals(nconst) INCLUDE (tconst);
The index is on the nconst column (which is used in the join operator), and it also includes the tconst column so that we can join it later on with another table. Now, the query finishes in less than a second:

The index clearly improved the performance.
For a given actor, find their ten most highly rated films
Let’s now find ten best movies a given actor has been in. The query is:
SELECT TB.*, TR.*
FROM name_basics AS NB
LEFT JOIN title_principals AS TP ON TP.nconst = NB.nconst
LEFT JOIN title_basics AS TB ON TB.tconst = TP.tconst
LEFT JOIN title_ratings AS TR on TR.tconst = TP.tconst
WHERE NB.nconst = 'nm1588970'
ORDER BY TR.averagerating DESC, TR.numvotes DESC
LIMIT 10
Here is the output:
+------------+------------+-----------------------+-----------------------+----------+------------+----------+-----------------+--------------------+------------+----------------+----------+
| tconst | titletype | primarytitle | originaltitle | isadult | startyear | endyear | runtimeminutes | genres | tconst | averagerating | numvotes |
+------------+------------+-----------------------+-----------------------+----------+------------+----------+-----------------+--------------------+------------+----------------+----------+
| tt7513040 | short | Den gamla goda tiden | Den gamla goda tiden | false | 1946 | (null) | 6 | Documentary,Short | (null) | (null) | (null) |
| tt0000001 | short | Carmencita | Carmencita | false | 1894 | (null) | 1 | Documentary,Short | tt0000001 | 5.70000000 | 1965 |
+------------+------------+-----------------------+-----------------------+----------+------------+----------+-----------------+--------------------+------------+----------------+----------+
This query runs for the following number of seconds:
+------+------+-----+
| EC2 | RDS | Mac |
+------+------+-----+
| 3 | 12 | 30 |
+------+------+-----+
Here is the estimated execution:

We can see a very similar story here. title_principals table doesn’t have an index, so the engine needs to scan it fully. Let’s compare with the actual execution:
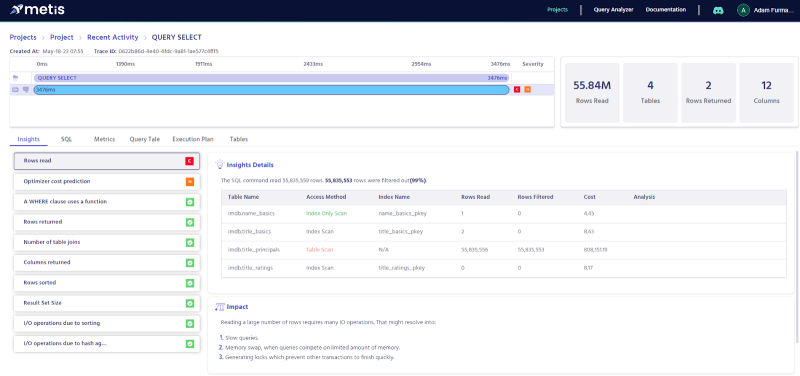
We can see that the performance is low because of this missing index. Once we add it, we get the following performance:

The query executes in 1 millisecond now.
Find the ten top rated films with some number of votes
Let’s now find the best movies that received some number of votes. This is the query:
SELECT TB.*, TR.*
FROM title_basics AS TB
LEFT JOIN title_ratings AS TR on TR.tconst = TB.tconst
WHERE TR.numvotes > 10000
ORDER BY TR.averagerating DESC
LIMIT 10
Result:
+-------------+------------+-------------------------+-------------------------+----------+------------+----------+-----------------+-----------------------------+-------------+----------------+----------+
| tconst | titletype | primarytitle | originaltitle | isadult | startyear | endyear | runtimeminutes | genres | tconst | averagerating | numvotes |
+-------------+------------+-------------------------+-------------------------+----------+------------+----------+-----------------+-----------------------------+-------------+----------------+----------+
| tt2301451 | tvEpisode | Ozymandias | Ozymandias | false | 2013 | (null) | 48 | Crime,Drama,Thriller | tt2301451 | 10.00000000 | 193154 |
| tt12187040 | tvEpisode | Plan and Execution | Plan and Execution | false | 2022 | (null) | 50 | Crime,Drama | tt12187040 | 9.90000000 | 48920 |
| tt9906260 | tvEpisode | Hero | Hero | false | 2019 | (null) | 24 | Action,Adventure,Animation | tt9906260 | 9.90000000 | 100806 |
| tt4283094 | tvEpisode | The Winds of Winter | The Winds of Winter | false | 2016 | (null) | 68 | Action,Adventure,Drama | tt4283094 | 9.90000000 | 152869 |
| tt2301455 | tvEpisode | Felina | Felina | false | 2013 | (null) | 55 | Crime,Drama,Thriller | tt2301455 | 9.90000000 | 127058 |
| tt13857684 | tvEpisode | Assault | Assault | false | 2021 | (null) | 24 | Action,Adventure,Animation | tt13857684 | 9.90000000 | 79715 |
| tt4283088 | tvEpisode | Battle of the Bastards | Battle of the Bastards | false | 2016 | (null) | 60 | Action,Adventure,Drama | tt4283088 | 9.90000000 | 215387 |
| tt2178784 | tvEpisode | The Rains of Castamere | The Rains of Castamere | false | 2013 | (null) | 51 | Action,Adventure,Drama | tt2178784 | 9.90000000 | 110274 |
| tt9313966 | tvEpisode | The Phantom Apprentice | The Phantom Apprentice | false | 2020 | (null) | 27 | Action,Adventure,Animation | tt9313966 | 9.90000000 | 14657 |
| tt10023374 | tvEpisode | Midnight Sun | Midnight Sun | false | 2019 | (null) | 24 | Action,Adventure,Animation | tt10023374 | 9.90000000 | 46063 |
+-------------+------------+-------------------------+-------------------------+----------+------------+----------+-----------------+-----------------------------+-------------+----------------+----------+
Timings:
+------+------+-----+
| EC2 | RDS | Mac |
+------+------+-----+
| 2 | 1 | 1 |
+------+------+-----+
Let us now check the plan:

Once again, we lack an index. Metis clearly shows what index we should add:
CREATE INDEX IDX_title_ratings_637d5836 ON title_ratings (numvotes)
This creates the index on the title_ratings table on the numvotes column. Let’s see if the actual execution agrees:

We can see that the number of rows read is actually higher than the estimate (1.31M vs 1.06M). The index would definitely help. Let’s add it and see the performance:

We can see that it greatly improved the performance.
Given two people, list what movies they appeared in together
Let’s now write a query that finds movies with two specified actors. Query is:
SELECT TB.*
FROM title_basics AS TB
JOIN title_principals AS TP1 ON TP1.tconst = TB.tconst
JOIN title_principals AS TP2 ON TP2.tconst = TB.tconst
WHERE TP1.nconst = 'nm0302368' AND TP2.nconst = 'nm0001908'
Output:
+------------+------------+--------------------------+--------------------------+----------+------------+----------+-----------------+------------------------+
| tconst | titletype | primarytitle | originaltitle | isadult | startyear | endyear | runtimeminutes | genres |
+------------+------------+--------------------------+--------------------------+----------+------------+----------+-----------------+------------------------+
| tt0000439 | short | The Great Train Robbery | The Great Train Robbery | false | 1903 | (null) | 11 | Action,Adventure,Crime |
+------------+------------+--------------------------+--------------------------+----------+------------+----------+-----------------+------------------------+
Let’s now see the estimated execution plan:
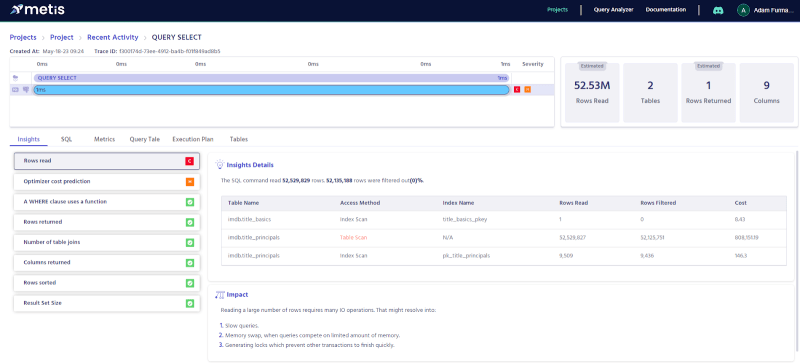
Once again we see that the title_principals table is slowing the query down. Let’s compare that with the actual execution:
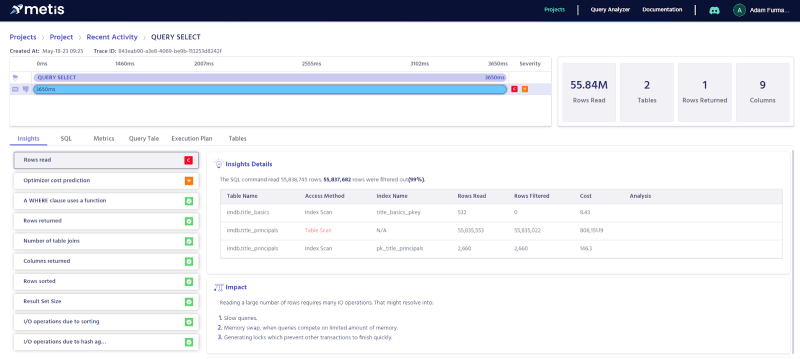
Estimations were pretty correct, and the query is slow. Metis shows that the table scan is the root cause of the low performance. Let’s add the index with:
CREATE INDEX IF NOT EXISTS title_principals_nconst_idx ON imdb.title_principals(nconst) INCLUDE (tconst);
Let’s see the performance now:

And we can see the performance is much better now.
List all of the cast and crew in a given movie
Let’s now find all the people involved in the movie. Here comes the query:
SELECT DISTINCT NB.*
FROM title_basics AS TB
LEFT JOIN title_principals AS TP ON TP.tconst = TB.tconst
LEFT JOIN title_crew AS TC ON TC.tconst = TB.tconst
LEFT JOIN name_basics AS NB ON
NB.nconst = TP.nconst
OR TC.directors = NB.nconst
OR TC.directors LIKE NB.nconst || ',%'::text
OR TC.directors LIKE '%,'::text || NB.nconst || ',%'::text
OR TC.directors LIKE '%,'::text || NB.nconst
OR TC.writers = NB.nconst
OR TC.writers LIKE NB.nconst || ',%'::text
OR TC.writers LIKE '%,'::text || NB.nconst || ',%'::text
OR TC.writers LIKE '%,'::text || NB.nconst
WHERE TB.tconst = 'tt0000439'
Here is the output:
+------------+--------------------------------------+------------+------------+------------------------------------+-----------------------------------------+
| nconst | primaryname | birthyear | deathyear | primaryprofession | knownfortitles |
+------------+--------------------------------------+------------+------------+------------------------------------+-----------------------------------------+
| nm0302368 | Donald Gallaher | 1895 | 1961 | actor,director,miscellaneous | tt0021457,tt0020221,tt0029541,tt0020275 |
| nm1145809 | Scott Marble | 1847 | 1919 | writer | tt0438068 |
| nm0001908 | Gilbert M. 'Broncho Billy' Anderson | 1880 | 1971 | director,actor,producer | tt0183803,tt0001706,tt0003719,tt0176832 |
| nm2313241 | John Manus Dougherty Sr. | 1885 | (null) | actor | tt0000439 |
| nm0807466 | Blair Smith | 1859 | (null) | cinematographer,camera_department | tt0343568,tt0000439,tt0368073,tt0344376 |
| nm0055607 | George Barnes | 1880 | 1951 | actor | tt0434558,tt0408105,tt0003756,tt0322643 |
| nm0131750 | Walter Cameron | 1872 | 1942 | actor,cinematographer | tt0010346,tt0004760 |
| nm0055661 | Justus D. Barnes | 1862 | 1946 | actor | tt0233527,tt0415631,tt0415738,tt0002504 |
| nm0007625 | A.C. Abadie | 1878 | 1950 | cinematographer,director,actor | tt0485015,tt0477387,tt0167051,tt0918623 |
| nm0692105 | Edwin S. Porter | 1870 | 1941 | director,cinematographer,writer | tt0000757,tt0004654,tt0006279,tt1932747 |
+------------+--------------------------------------+------------+------------+------------------------------------+-----------------------------------------+
And the timings:
+------+------+-----+
| EC2 | RDS | Mac |
+------+------+-----+
| 94 | 98 | 685 |
+------+------+-----+
Here are the estimates:

We can see three insights. One regarding number of rows (and missing index), one about the total cost of the plan, and one about the sorting of rows. Let’s compare that with the actuals:
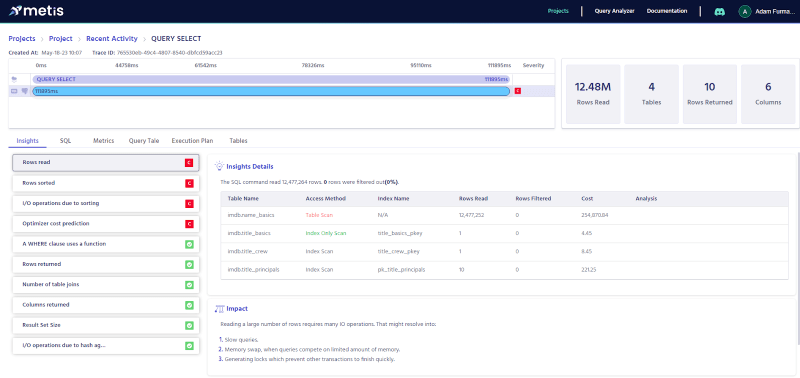
We can see one more insight. That is regarding the I/O operations for the sorting part. When we go to the query tale, Metis shows that indeed scanning the name_basics table took a lot:

The optimizer decided to materialize the result of the scan because it couldn’t optimize the join with multiple filters.
Why do we need that join? This is because in directors and writers we store the value as CSV:
nm0001,nm002,nm003
Not to mention, that this query extracted the title_basics table which we don’t need at all.
How can we improve the query? We need to split the CSV into a regular column. First, let’s see how many identifiers we store at most:
SELECT MAX(CHAR_LENGTH(writers) - CHAR_LENGTH(REPLACE(writers, ',', '')))
FROM title_crew
We take the length of the writers column and subtract the length of the writers column with commas removed. The maximum value we get is 1390. This means that we have at most 1391 identifiers serialized in that field. For directors we get 490. Based on that we can safely assume that there are no more than 1500 identifiers. We can use that to split them and build a table with nconst identifiers:
WITH RECURSIVE numbers AS (
SELECT 1 AS number
UNION ALL
SELECT number + 1 AS number FROM numbers WHERE number < 1500
),
split_associations AS (
SELECT SPLIT_PART(TC.directors, ',', N.number) AS nconst
FROM title_crew AS TC
CROSS JOIN numbers AS N
WHERE tconst = 'tt0000439' AND directors IS NOT NULL AND CHAR_LENGTH(directors) - CHAR_LENGTH(REPLACE(directors, ',', '')) + 1 >= N.number
UNION
SELECT SPLIT_PART(TC.writers, ',', N.number) AS nconst
FROM title_crew AS TC
CROSS JOIN numbers AS N
WHERE tconst = 'tt0000439' AND writers IS NOT NULL AND CHAR_LENGTH(writers) - CHAR_LENGTH(REPLACE(writers, ',', '')) + 1 >= N.number
),
all_associations AS (
SELECT SA.nconst
FROM split_associations AS SA
UNION
SELECT TP.nconst
FROM title_principals AS TP
WHERE TP.tconst = 'tt0000439'
)
SELECT *
FROM all_associations
Output:
+-----------+
| nconst |
+-----------+
| nm0807466 |
| nm1145809 |
| nm0007625 |
| nm0302368 |
| nm0692105 |
| nm0055661 |
| nm0055607 |
| nm0131750 |
| nm0001908 |
| nm2313241 |
+-----------+
We can now join this with name_basics table and get the final query:
WITH RECURSIVE numbers AS (
SELECT 1 AS number
UNION ALL
SELECT number + 1 AS number FROM numbers WHERE number < 1500
),
split_associations AS (
SELECT SPLIT_PART(TC.directors, ',', N.number) AS nconst
FROM title_crew AS TC
CROSS JOIN numbers AS N
WHERE tconst = 'tt0000439' AND directors IS NOT NULL AND CHAR_LENGTH(directors) - CHAR_LENGTH(REPLACE(directors, ',', '')) + 1 >= N.number
UNION
SELECT SPLIT_PART(TC.writers, ',', N.number) AS nconst
FROM title_crew AS TC
CROSS JOIN numbers AS N
WHERE tconst = 'tt0000439' AND writers IS NOT NULL AND CHAR_LENGTH(writers) - CHAR_LENGTH(REPLACE(writers, ',', '')) + 1 >= N.number
),
all_associations AS (
SELECT SA.nconst
FROM split_associations AS SA
UNION
SELECT TP.nconst
FROM title_principals AS TP
WHERE TP.tconst = 'tt0000439'
)
SELECT NB.*
FROM name_basics AS NB
JOIN all_associations AS AA ON AA.nconst = NB.nconst
Execution plan and analysis:

We can see that now the query uses indexes and is much faster. We could optimize it even further by calculating data that would let us avoid splitting by comma with each request.
Find the most prolific actor in a given period
Let’s now find the actor that did the most movies in a given period of time. Query:
SELECT NB.nconst, MAX(NB.primaryname), MAX(nb.birthyear), MAX(NB.deathyear), MAX(nb.primaryprofession), COUNT(*) AS number_of_titles
FROM title_basics AS TB
RIGHT JOIN title_principals AS TP ON TP.tconst = TB.tconst
RIGHT JOIN name_basics AS NB ON NB.nconst = TP.nconst
WHERE TB.startyear >= 1900 AND TB.startyear <= 1915
GROUP BY NB.nconst
ORDER BY number_of_titles DESC
LIMIT 1
Output:
+------------+-----------------+-------+-------+--------------------------+------------------+
| nconst | max | max | max | max | number_of_titles |
+------------+-----------------+-------+-------+--------------------------+------------------+
| nm0002615 | Siegmund Lubin | 1851 | 1923 | producer,director,actor | 2993 |
+------------+-----------------+-------+-------+--------------------------+------------------+
Execution times:
+------+------+-----+
| EC2 | RDS | Mac |
+------+------+-----+
| 180 | 51 | 45 |
+------+------+-----+
Let’s see the estimated analysis:
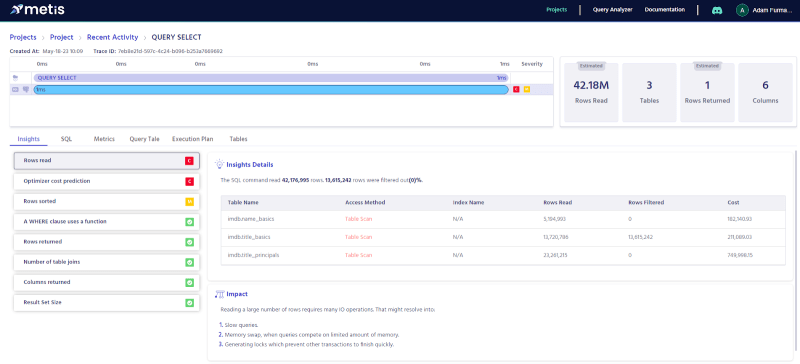
Metis shows table scans, a lot. That’s because we filter based on the startyear column which isn’t indexed. Let’s fix that with the following indexes:
CREATE INDEX IF NOT EXISTS title_basics_startyear_idx ON imdb.title_basics(startyear) INCLUDE (tconst);
CREATE INDEX IF NOT EXISTS title_principals_tconst_idx ON imdb.title_principals(tconst) INCLUDE (nconst);
Let’s also notice that we don’t need to join name_basics first. We can start from the titles, and then get the details of the actor once we know who we’re looking for:
WITH best_actor AS (
SELECT TP.nconst, COUNT(*) AS number_of_titles
FROM title_basics AS TB
LEFT JOIN title_principals AS TP ON TP.tconst = TB.tconst
WHERE TB.startyear >= 1900 AND TB.startyear <= 1915 AND TP.nconst IS NOT NULL
GROUP BY TP.nconst
ORDER BY number_of_titles DESC
LIMIT 1
)
SELECT BA.nconst, BA.number_of_titles, NB.primaryname, nb.birthyear, NB.deathyear, nb.primaryprofession
FROM best_actor AS BA
JOIN name_basics AS NB ON NB.nconst = BA.nconst
This gives the following analysis:

We can see how these changes improved the query significantly.
Find most prolific actors in a given genre
Let’s now find ten actors doing most movies in a given genre. The query goes like this:
SELECT NB.nconst, NB.primaryname, NB.birthyear, COUNT(*) AS movies_count
FROM name_basics AS NB
LEFT JOIN title_principals AS TP ON TP.nconst = NB.nconst
LEFT JOIN title_basics AS TB ON TB.tconst = TP.tconst
WHERE TB.genres = 'Action' OR TB.genres LIKE 'Action,%' OR TB.genres LIKE '%,Action,%' OR TB.genres LIKE '%,Action'
GROUP BY NB.nconst, NB.primaryname, NB.birthyear
ORDER BY movies_count DESC
LIMIT 10
Output:
+------------+---------------------+------------+--------------+
| nconst | primaryname | birthyear | movies_count |
+------------+---------------------+------------+--------------+
| nm0411127 | Shotaro Ishinomori | 1938 | 3428 |
| nm0256607 | Hiroko Emori | 1961 | 2211 |
| nm0496556 | John Ledford | (null) | 2205 |
| nm0881576 | Yoshio Urasawa | (null) | 2197 |
| nm0840642 | Teiyû Ichiryûsai | 1958 | 2175 |
| nm2029519 | Coco Martin | 1981 | 2106 |
| nm0782841 | Toshihiko Seki | 1962 | 2090 |
| nm1167622 | Tsutomu Shibayama | 1941 | 2082 |
| nm1113319 | Soubee Amako | (null) | 2065 |
| nm1114802 | Akiko Muta | (null) | 2064 |
+------------+---------------------+------------+--------------+
Timings:
+------+------+-----+
| EC2 | RDS | Mac |
+------+------+-----+
| 17 | 78 | 93 |
+------+------+-----+
Metis tells the following:

Metis immediately identifies a lack of indexes and operations that can be optimized. There are two things that we can do here. First, let’s add an index to find titles for a given genre faster:
CREATE INDEX title_basics_genres_gin_idx ON title_basics USING gin (genres gin_trgm_ops);
Next, let’s rewrite the query to get the titles first and then join actors:
WITH best_actors AS (
SELECT TP.nconst, COUNT(*) AS movies_count
FROM title_basics AS TB
LEFT JOIN title_principals AS TP ON TP.tconst = TB.tconst
WHERE TB.genres = 'Action' OR TB.genres LIKE 'Action,%' OR TB.genres LIKE '%,Action,%' OR TB.genres LIKE '%,Action'
GROUP BY TP.nconst
ORDER BY movies_count DESC
LIMIT 10
)
SELECT BA.nconst, NB.primaryname, NB.birthyear, BA.movies_count
FROM best_actors AS BA
JOIN name_basics AS NB ON NB.nconst = BA.nconst
ORDER BY movies_count DESC
This gives the following analysis:

Specifically, we can see that we use indexes for each table and reach much fewer rows:
Finding most common coworkers
Let’s now find five people a given person worked with the most. We start with the following query:
WITH RECURSIVE numbers AS (
SELECT 1 AS number
UNION ALL
SELECT number + 1 AS number FROM numbers WHERE number < 1500
),
titles_for_person AS (
SELECT TC.tconst
FROM title_crew AS TC
WHERE directors = 'nm0000428' OR directors LIKE 'nm0000428,%' OR directors LIKE '%,nm0000428,%' OR directors LIKE '%,nm0000428'
UNION
SELECT TC.tconst
FROM title_crew AS TC
WHERE writers = 'nm0000428' OR writers LIKE 'nm0000428,%' OR writers LIKE '%,nm0000428,%' OR writers LIKE '%,nm0000428'
UNION
SELECT tconst
FROM title_principals
WHERE nconst = 'nm0000428'
),
titles_corresponding AS (
SELECT TC.tconst, TC.directors, TC.writers
FROM title_crew AS TC
JOIN titles_for_person AS TFP ON TFP.tconst = TC.tconst
),
split_associations AS (
SELECT TC.tconst, SPLIT_PART(TC.directors, ',', N.number) AS nconst
FROM titles_corresponding AS TC
CROSS JOIN numbers AS N
WHERE directors IS NOT NULL AND CHAR_LENGTH(directors) - CHAR_LENGTH(REPLACE(directors, ',', '')) + 1 >= N.number
UNION
SELECT TC.tconst, SPLIT_PART(TC.writers, ',', N.number) AS nconst
FROM titles_corresponding AS TC
CROSS JOIN numbers AS N
WHERE writers IS NOT NULL AND CHAR_LENGTH(writers) - CHAR_LENGTH(REPLACE(writers, ',', '')) + 1 >= N.number
),
all_associations AS (
SELECT SA.tconst, SA.nconst
FROM split_associations AS SA
UNION
SELECT TP.tconst, TP.nconst
FROM title_principals AS TP
JOIN titles_for_person AS TFP ON TFP.tconst = TP.tconst
),
other_people AS (
SELECT nconst
FROM all_associations
WHERE nconst != 'nm0000428'
),
top_peers AS (
SELECT OP.nconst, COUNT(*) as common_titles
FROM other_people AS OP
GROUP BY nconst
ORDER BY common_titles DESC
LIMIT 5
)
SELECT TP.nconst, TP.common_titles, NB.*
FROM top_peers AS TP
JOIN name_basics AS NB ON NB.nconst = TP.nconst
ORDER BY TP.common_titles DESC
Output:
+------------+----------------+------------+--------------------+------------+------------+---------------------------------------------+-----------------------------------------+
| nconst | common_titles | nconst | primaryname | birthyear | deathyear | primaryprofession | knownfortitles |
+------------+----------------+------------+--------------------+------------+------------+---------------------------------------------+-----------------------------------------+
| nm0005658 | 479 | nm0005658 | G.W. Bitzer | 1872 | 1944 | cinematographer,director,camera_department | tt0431889,tt0006864,tt0315105,tt0009968 |
| nm0115524 | 156 | nm0115524 | Kate Bruce | 1860 | 1946 | actress | tt0014604,tt0000816,tt0000909,tt0006745 |
| nm0555522 | 134 | nm0555522 | Arthur Marvin | 1859 | 1911 | cinematographer,director,camera_department | tt0300052,tt0291476,tt0233612,tt0000412 |
| nm0038106 | 130 | nm0038106 | Linda Arvidson | 1884 | 1949 | actress,writer | tt1487900,tt0160818,tt0000770,tt0000628 |
| nm0424530 | 121 | nm0424530 | Arthur V. Johnson | 1876 | 1916 | actor,director,writer | tt0000628,tt0003675,tt0337827,tt0000697 |
+------------+----------------+------------+--------------------+------------+------------+---------------------------------------------+-----------------------------------------+
Timings:
+------+------+-----+
| EC2 | RDS | Mac |
+------+------+-----+
| 6 | 29 | 866 |
+------+------+-----+
And analysis:

Metis shows table scans and lack of indexes. See the numbers that the query reads millions of rows. Let’s build indexes for title_crew table:
CREATE INDEX title_crew_directors_gist_idx ON title_crew USING gist (directors gist_trgm_ops);
CREATE INDEX title_crew_writers_gist_idx ON title_crew USING gist (writers gist_trgm_ops);
Let’s also add indexes for title_principals:
CREATE INDEX IF NOT EXISTS title_principals_nconst_idx ON imdb.title_principals(nconst) INCLUDE (tconst);
CREATE INDEX IF NOT EXISTS title_principals_tconst_idx ON imdb.title_principals(tconst) INCLUDE (nconst);
This should give us a significant speedup:

We can see that we read thousands of rows now. That’s a great improvement.
Summary
We have seen a couple of good examples where Metis can clearly show database performance improvements. Thanks to that, we don’t go blind anymore. We can see our improvements, verify if indexes are beneficial, and see how the database performs. The crucial part is that we can finally get some clarity around the database internals. That’s the very first step towards building proper database guardrails.

Top comments (0)