
On paper, the Aggregate pattern appears streamlined. However, practical implementation often reveals complexities. Aggregates, representing not just single objects but entire clusters, magnify the challenges of managing states and their combinations.
Understanding DDD Concepts
Aggregate is a cluster of associated objects that are treated as a unit for the purpose of data changes. External references are restricted to one member of the AGGREGATE, designated as the root. A set of consistency rules applies within the AGGREGATE’S boundaries.
Entity is an object fundamentally defined not by its attributes, but by a thread of continuity and identity.
Value Object is an object that describes some characteristic or attribute but carries no concept of identity.
Invariant is an assertion about some design element that must be true at all times, except during specifically transient situations such as the middle of the execution of a method, or the middle of an uncommitted database transaction.
The Bananas, The Gorilla, and The Jungle
Joe Armstrong, Erlang's creator, articulates a foundational issue with object-oriented programming (OOP): the implied baggage. Using an object often means pulling in its entire context, akin to wanting a banana but getting the gorilla and the jungle too:
I think the lack of reusability comes in object-oriented languages, not functional languages. The problem with object-oriented languages is they’ve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.
public class Banana
{
public Gorilla Owner {get; set;}
}
public class Gorilla
{
public Jungle Habitat {get; set;}
}
public class Jungle
{
// ...
}
This results in two types of complications:
- Compile-time Coupling: unclear dependency hierarchies increase complexity.
- Runtime Coupling: excessive memory consumption due to unnecessary dependencies.
This is a fly in the ointment of object-oriented programming as a whole. However, it's still valid in the more narrow context of the Aggregate pattern.
Guidelines for Effective Aggregate Design
Vaughn Vernon, in his book, "Implementing Domain-Driven Design", elucidates the following rules:
- Model True Invariants in Consistency Boundaries
- Design Small Aggregates
- Reference Other Aggregates by Identity
- Use Eventual Consistency Outside the Boundary
- Avoid Dependency Injection
Let's check out Vaughn's example domain.
Starting from here, this article borrows examples and quotes some paragraphs from Vaughn Vernon's, "Implementing Domain-Driven Design".
Designing a Scrum Management Application
The company has assembled a group of talented Scrum experts and developers.
Key Features
- Products have backlog items, releases, and sprints.
- New product backlog items are planned.
- New product releases are scheduled.
- New product sprints are scheduled.
- A planned backlog item may be scheduled for release.
- A scheduled backlog item may be committed to a sprint.
Key Constraints
- If a backlog item is committed to a sprint, we must not allow it to be removed from the system.
- If a sprint has committed backlog items, we must not allow it to be removed from the system.
- If a release has scheduled backlog items, we must not allow it to be removed from the system.
- If a backlog item is scheduled for release, we must not allow it to be removed from the system.
First Attempt: Large-Cluster Aggregate
Product is first modeled as a very large Aggregate. The root object, Product, held all BacklogItem, all Release, and all Sprint instances associated with it. The interface design protected all parts from inadvertent client removal.
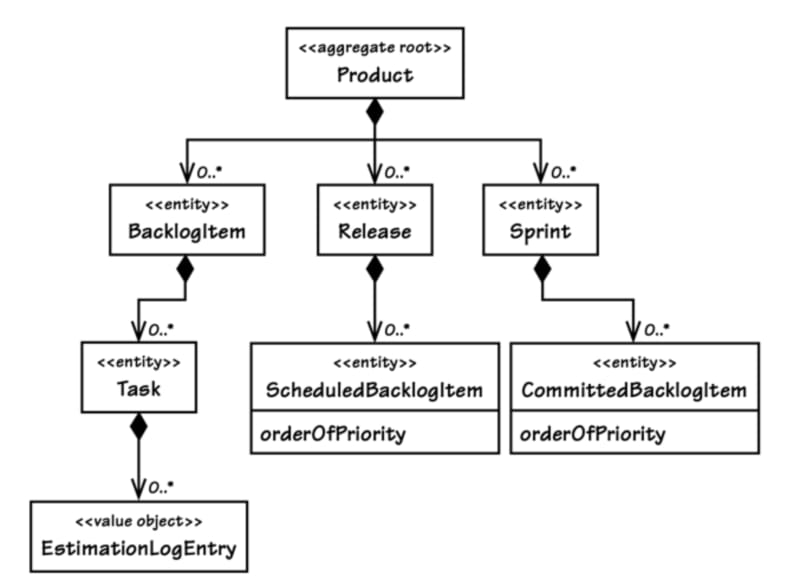
The big Aggregate looked attractive, but it wasn’t truly practical. Once the application was running in its intended multi-user environment, it began to regularly experience transactional failures.
Persistence mechanism (optimistic locking)
In EF Core, optimistic concurrency is implemented by configuring a property as a concurrency token. The concurrency token is loaded and tracked when an entity is queried - just like any other property. Then, when an update or delete operation is performed during SaveChanges(), the value of the concurrency token on the database is compared against the original value read by EF Core. Consider a common simultaneous, multi-client usage scenario:
- Two users, Bill and Joe, view the same
Productmarked as version 1 and begin to work on it. - Bill plans a new
BacklogItemand commits. TheProductversion is incremented to 2. - Joe schedules a new
Releaseand tries to save it, but his commit fails because it was based onProductversion 1.
Assuming your Aggregate boundaries are aligned with real business constraints, it’s going to cause problems. Thinking through the various commit order permutations, you’ll see that there are cases where two of the three requests will fail.

Aggregate was designed with false invariants in mind, not real business rules. These false invariants are artificial constraints imposed by developers. There are other ways for the team to prevent inappropriate removal without being arbitrarily restrictive. Besides causing transactional issues, the design also has performance and scalability drawbacks.
Second Attempt: Multiple Aggregates

Vaughn's solution resolves transaction failures by modeling collection navigation properties away and replacing object navigation properties with identifiers.
Product
public class Product : EntityBase
{
int ProductId { get; set; }
}
Backlog Item
public class BacklogItem : EntityBase
{
int ProductId { get; set; }
}
Task
public class Task : EntityBase
{
public string Name { get; set; }
public int BacklogItemId { get; set; }
public List<EstimationLogEntry> Logs { get; set; }
}
Scalability

Since Aggregates don’t use direct references to other Aggregates but reference by identity, their persistent state can be moved around to reach a large scale. Almost-infinite scalability is achieved by allowing for continuous repartitioning of Aggregate data storage, as explained by Pat Helland in his position paper “Life beyond Distributed Transactions: An Apostate’s Opinion”.
Estimating Aggregate Cost
You might be wondering if we need navigation properties at all. A key to making a proper determination lay in the Ubiquitous Language. Here is where the Task invariant was stated:
- When progress is made on a backlog item task, the team member will estimate the task hours remaining.
- When a team member estimates that zero hours are remaining on a specific task, the backlog item checks all tasks for any remaining hours. If no hours remain on any tasks, the backlog item status is automatically changed to "done".
- When a team member estimates that one or more hours are remaining on a specific task and the backlog item’s status is already done, the status is automatically regressed.
This sure seems like a true invariant. Thus, the ICollection<EstimationLogEntry> navigation property is required for a Task:
public class Task : EntityBase
{
// Reference other aggregates by Id.
public int BacklogItemId { get; set; }
// Don't allow to update directly
private List<EstimationLogEntry> _logs = new();
public ReadOnlyCollection<EstimationLogEntry> Logs => _logs.AsReadOnly();
// Don't allow to update directly
public int HoursRemaining { get; protected set; }
// Update HoursRemaining and add a log entry within the same transaction
public void Estimate(int hoursRemaining)
{
HoursRemaining = hoursRemaining;
_logs.Add(new EstimationLogEntry(this, hoursRemaining));
}
}
The regular sprint length is 2 weeks. Even if the task estimate changes daily, we would have 5 working days * 2 weeks = 10 estimation log entries. Another factor is that the higher end of objects is not reached until the last day of the sprint. During much of the sprint, the Aggregate is even smaller.
Harnessing Aggregates with GraphQL
GraphQL stands out as a potent query language for APIs. It can efficiently manage and optimize data queries. With GraphQL, one can:
- Define precise data requirements.
- Reduce over-fetching or under-fetching of data.
- Seamlessly integrate with DDD aggregates, especially on query operations.
Thus, navigation properties only make sense when we are quite sure that the aggregate size is reasonably small. I found that the whole banana-gorilla-jungle thing is much less of a hustle when using GraphQL rather than traditional REST-like APIs, at least on the query side of things. Consider the following GraphQL schema definition:
Task Query
Let's make aggregation roots GraphQL queries:
type Query {
tasks: [Task!]!
}
type Task {
name: String!
backlogItem: BacklogItem!
logs: [EstimationLogEntry!]!
id: Int!
}
Estimation Log Entry
Estimation logs will be available as separate GraphQL resolvers:
type EstimationLogEntry {
hoursRemaining: Int!
id: Int!
}
Query Example
{
tasks {
id
logs {
hoursRemaining
}
}
}
Resolvers
The Resolver concept is natural for a GraphQL API. We can replace all navigation properties with resolvers, making sure that we only reference other entities/aggregates by an object link rather than by ID when we absolutely have to:
public class BacklogItemType : ObjectType<BacklogItem>
{
protected override void Configure(
IObjectTypeDescriptor<Task> descriptor)
{
descriptor
.Field(x => x.Logs)
.Resolve<IQueryable<EstimationLogEntry>>(context =>
context
.Services
.GetRequiredService<IDbContextFactory<ScrumDbContext>>()
.CreateDbContext()
.Set<EstimationLogEntry>()
.Where(x => x.Task.Id == context.Parent<Task>().Id));
}
}
Summary
The Aggregate pattern in DDD, despite its inherent challenges, can be greatly optimized using tools like GraphQL. By following established best practices and embracing modern techniques, developers can seamlessly model aggregates, ensuring efficient and scalable applications.





Top comments (0)