
Just over a year ago, I forked Facebook's Relay to fix a bug that caused an incorrect state based on network latency (yikes!). While the concepts of publish queues and distributed state are pretty complex, the bug itself is darn simple and a great foray into distributed systems, which is why I'm using it here to illustrate the fundamentals (and gotchas!) of building a simple client cache. This isn't a slam against Facebook developers; bugs happen & the shackles of legacy code at a mega corp are real. Rather, if it's something that professional developers at Facebook can goof up on, it can happen to anyone, so let's learn from it!
State vs. Transforms
The year is 1999 and I have a counter showing how many people are currently on my fresh new site. If I want that number to update in real time, My server could send 1 of 2 messages:
- State: "Hey, the new value is 8."
- Transform: "Hey, add 1 to whatever your counter is currently".
State works great for small things like a counter (8), whereas transforms work better for large things like a Google Doc (at position 5, insert "A"). With document stores like Relay, it may seem like a state update (replace old JSON with new JSON), but the server is just sending down a patch that Relay merges into a much larger document tree using a default transform. It then executes any extra transforms in the mutation updater function. The appearance of state makes it simple, the workings of a transform make it powerful. The perfect combo!
Updates and Lamport's Happened-Before
In all client caches, there are 3 kinds of updates: Local, Optimistic, and Server. A local update originates from the client & stays on the client, so it only contains state for that session. An optimistic update originates from the client & simulates the result of a server update so actions feel snappy, regardless of latency. A server update originates from a server and replaces the optimistic update, if available.
In all 3 cases, there's just one rule to follow: apply updates in the order they occurred. If I call an optimistic update, followed by a local update, the optimistic updater should run first, then pass its result to the local updater. This concept was cutting edge stuff when Leslie Lamport published it in 1978! Unfortunately, it's what Relay got wrong.
Instead of processing updates in the order they occurred, Relay processes server updates, then local updates, then optimistic updates. That means even though an optimistic update occurred first, Relay applies it after the local update. That's the crux of the bug.
Let's use that logic in a simple component like a volume slider that goes from 1 to 10. Say the volume is 3 and I optimistically add 1 to it. Then, I locally set the volume to 10. What's the result? If you guessed 10, you've correctly applied Lamport's relation. If you guessed 11, then you've got a broken app and a bright future at Facebook (Kidding. I'm totally kidding. 😉).
A Better Approach
If the current approach isn't mathematically sound, what's the alternative? The answer is pretty easy. Let's take a look at an example publish queue with 4 events: 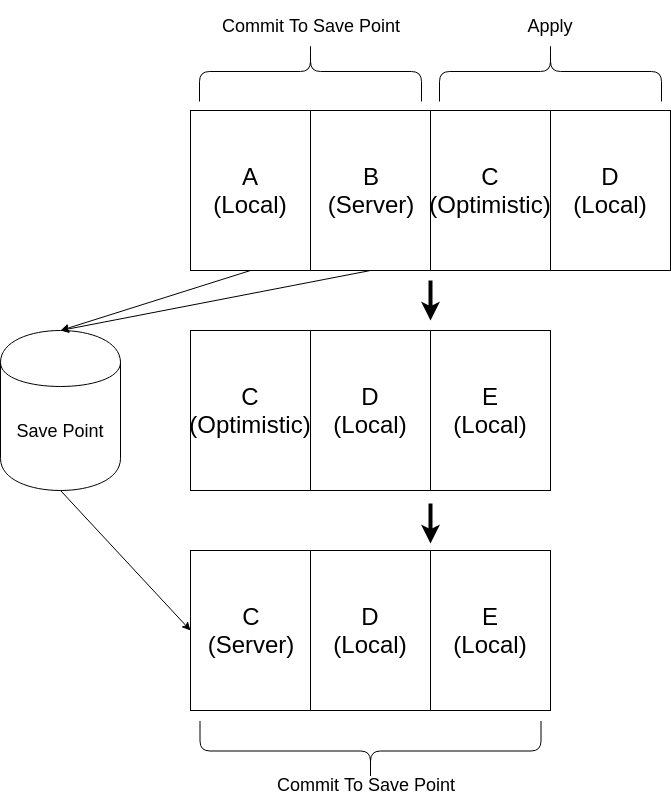
The above publish queue starts with 4 events: A local update, a server update, an optimistic update, and another local update. It doesn't matter what each update does because as long as they're applied in the order they occurred, we'll end up with the right answer.
In Row 1, we know A & B are deterministic (the opposite of optimistic) so we can commit those, meaning we'll never have to "undo" what they did. However, C is optimistic. If the C from the server is divergent from the optimistic C, then everything following could be different as well. For example, what if D were to multiply the result of C by 2? So, we apply those updates to create a current state, but keep them around in case we have to replay them.
In Row 2, we've got a save point that is the state after A and B have been applied. We've also kept all the events starting with the first optimistic event because they're all dependent on the result coming back from the server. As we wait for that server response, new events like E trickle in. We apply them so that the state is current but also hold onto them.
In Row 3, the server event for C comes back! We remove the optimistic event and replace it with the server event. Starting from the save point, we commit every event until there's another optimistic event. Since there are no more optimistic events, the queue is empty and we're done! It's really that simple. Now, why does C from the server get to jump in the queue? That's because C occurred at the time of the optimistic update, but because of latency, it wasn't received until after E. If you grok that, you grok distributed data types. If you'd like to see what that looks like in code, the package is here: relay-linear-publish-queue. Note that it depends on Relay merging this tiny PR.
With such a simple publish queue, it's possible to compare server events to optimistic events when they come in. If the server event just confirms what the optimistic event suspected, then we can flush the queue without performing a recalculation because we know it's correct. Performance gains to come!
Real World Application
Theory is boring. Now that we understand it, we can get to the fun stuff! With a functioning publish queue, I built an online sprint retrospective for folks like me who don't like conference rooms. If you're not familiar with a retrospective, it's a meeting where teams anonymously write what could've gone better last sprint, group them by theme, and then discuss the important issues. It's a great engineering habit that is slowly making its way into sales, marketing, and executive teams. While building the grouping phase, I didn't want to lose the ability for everyone to participate simultaneously. That meant building a system that could reliably share when someone else picked up and dragged a card:

If you'd like to play around with the demo you can check it out here (no signup necessary) or even view the source code.
Conclusion
I hope this clears up the purpose of a publish queue! If distributed systems sound interesting, this is only the beginning. From here, you can dive into data types such as Operational Transformations (what Google Docs uses) or serverless CRDTs, such as Automerge. If you'd like to get paid to learn about these things while avoiding pants and mega corps, we're hiring a few more remote devs. Reach out.





Top comments (0)