In a previous post we saw basic object recognition in images using Google’s TensorFlow library from Smalltalk. This post will walk you step by step through the process of using a pre-trained model to detect objects in an image.
It may also catch your attention that we are doing this from VASmalltalk rather than Python. Check out the previous post to see why I believe Smalltalk could be a great choice for doing Machine Learning.
Liquid error: internal
TensorFlow detection model Zoo
In this post, we will be again using a pre-trained model:
We provide a collection of detection models pre-trained on the COCO dataset, the Kitti dataset, the Open Images dataset, the AVA v2.1 dataset and the iNaturalist Species Detection Dataset. These models can be useful for out-of-the-box inference if you are interested in categories already in those datasets. They are also useful for initializing your models when training on novel datasets.
The original idea of using these models was written in this great post. Our work was also inspired by this and this Juypiter notebooks for the demo.
Designing the demo with a Smalltalk object-oriented approach
In the previous post you can see that all the demo was developed in the class LabelImage. While starting to implement this new demo we detected a lot of common behaviors when running pre-trained frozen prediction models. So… we first created a superclass called FrozenImagePredictor and changed LabelImage to be a subclass of it, overriding only a small part of the protocol.


After we finished the refactor it was quite easy to add a new subclass ObjectDetectionZoo. And all we needed to implement on that class was just 7 methods (and only 5 methods inLabelImage). So…as you can see, it’s quite easy now to add more and more frozen image predictors.
In the previous example (with LabelImage) we processed the “raw” results just as TensorFlow would answer it. However, with ObjectDetectionZoo the results were a bit more complex and in addition we needed to improve the readability of the information, for example, to render the “bounding boxes”. So we reified the TensorFlow results in ObjectDetectionImageResults.

These pre-trained models can answer the data for the “bounding boxes”. We were interested in seeing if we could render the image directly from Smalltalk and draw the boxes and labels. Again, time to reify that in ObjectDetectionImageRenderer.
To conclude, we have ObjectDetectionZoo which will run the model and answer ObjectDetectionImageResults and then delegate to ObjectDetectionImageRenderer to display and draw the results.
Running the examples!
To run the examples, you must first check the previous post to see how to install VASmalltalk and TensorFlow. After that, you can check the example yourself in the class comment of ObjectDetectionZoo.
This example runs the basic mobilenet_v1 net which is fast but not very accurate:
ObjectDetectionZoo new
imageFiles: OrderedCollection new;
addImageFile: 'examples\objectDetectionZoo\images\000000562059.jpg';
graphFile: 'examples\objectDetectionZoo\ssd_mobilenet_v1_coco_2018_01_28\frozen_inference_graph.pb';
prepareImageInput;
prepareSession;
predict;
openPictureWithBoundingBoxesAndLabel
Then you can simply change the one line where you specify the graph to use rcnn_inception_resnet_v2 and you will see the results are much better:
In the tensorflow-vast repository we only provide a few frozen pre-trained graphs because they are really big. However, you can very easily download additional ones and use them. The only thing you must do is to uncompress the .tar.gz and simply change the one line where you specify the graph (graphFile:) to use rcnn_inception_resnet_v2 and you will see the results are much better:

You can see with mobilenet_v1 the spoon was detected as person, the apple on the left and the bowl were not detected and the cake was interpreted as a sandwich. With rcnn_inception_resnet_v2 all looks correct:
Something very cool from TensorFlow is that you can run multiple images in parallel on a single invocation. So here is another example:
ObjectDetectionZoo new
imageFiles: OrderedCollection new;
graphFile: 'z:\Instantiations\TensorFlow\faster_rcnn_inception_resnet_v2_atrous_coco_2018_01_28\frozen_inference_graph.pb';
addImageFile: 'examples\objectDetectionZoo\images\000000463849.jpg';
addImageFile: 'examples\objectDetectionZoo\images\000000102331.jpg';
addImageFile: 'examples\objectDetectionZoo\images\000000079651.jpg';
addImageFile: 'examples\objectDetectionZoo\images\000000045472.jpg';
prepareImageInput;
prepareSession;
predict;
openPictureWithBoundingBoxesAndLabel
Which brings these results:
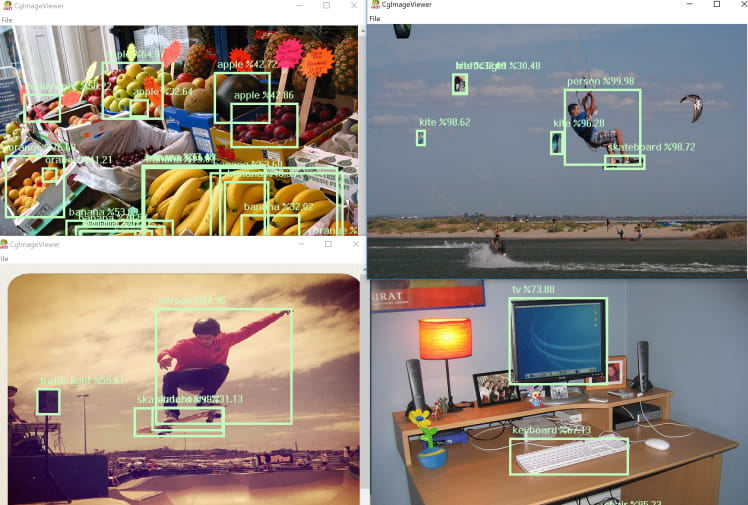
As you can see here there are many different pre-trained models so you can use and experiment with any of those. In this post we just took 2 of them (mobilenet_v1 and rcnn_inception_resnet_v2) but you can try with anyone. All you need to do is to download the .tar.gz of that model, uncompress it, and specify the graph file with graphFile:.
Finally, you can also try with different pictures. You can try with any image of your own or try with the ones provided in the databases used to train these models (COCO, Kitti, etc.).
Conclusions and Future Work
We keep pushing to show TensorFlow examples from Smalltalk. In the future, we would really like to experiment with training models in Smalltalk itself. Particularly, we want to experiment with IoT boards with GPU (like Nvidia Jetson or similar).
It would also be interesting to try detecting objects on videos aside from pictures.
Finally, thanks to Gera Richarte for the help on this work and to Maxi Tabacman for reviewing the post.

Top comments (0)