
Welcome, fellow nerds, to the 1st part of a blog series on replication. We will be discussing why we even need to distribute a database across multiple machines, what are leaders and followers, how to handle the failure of leaders and followers, etc. It will set it up nicely for our future blog in this series.
Why distribute a database across multiple machines?
- Scalability - If your data volume, read load, or write load grows larger than what a single machine can handle, you can spread the load across multiple machines
- High availability - If your application needs to continue to serve even if one or more machines goes down, you can use multiple machines to give you redundancy/ fault tolerance.
- Latency - If you have users over the globe, you will want to have servers at various locations worldwide so that each user is served from a data center that is geographically closer to them.
There are 2 common ways to distribute data across multiple machines (or nodes)
- Replication - Keeping a copy of the same data on several different nodes, potentially in different locations. Replication provides redundancy.
- Partition - Splitting the database into smaller subsets called partitions so that different partitions can be assigned to different nodes (also known as sharding)
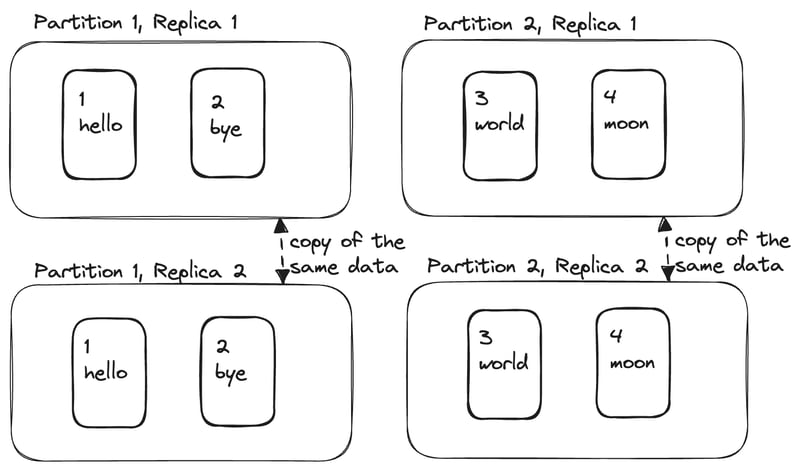
Leaders & Followers
Every node that has a copy of the database is called a replica. Every write needs to be processed by every replica; otherwise, the replicas would no longer have the same data. One of the replicas is designated as the leader. When a client wants to write to the database, they must send their request to the leader that first writes the new data to its local storage.
The replicas other than the leader are known as followers. Whenever the leader writes new data to its local storage, it also sends the data change to all of its followers as part of the replication log or change stream in the same order they were processed by the leader. All the followers are read-only, while only the leader accepts the writes. So, when the client wants to read from the database, the followers or the leader can serve the read request.
Async vs Sync Replication
In synchronous replication, the leader waits until the follower confirms that it received the write before reporting the success to the user and before making the write visible to other clients. In asynchronous replication, the leader sends the message and doesn't wait for the acknowledgment from the follower.
The advantage of synchronous replication is that the follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader. If the leader suddenly fails, we can be sure the follower has the data available. The disadvantage is that if the follower doesn't respond, for some reason, it has crashed, network fault, etc. The write cannot be processed. The leader will have to block all the writes and wait for the acknowledgment from the follower whenever it is available again.
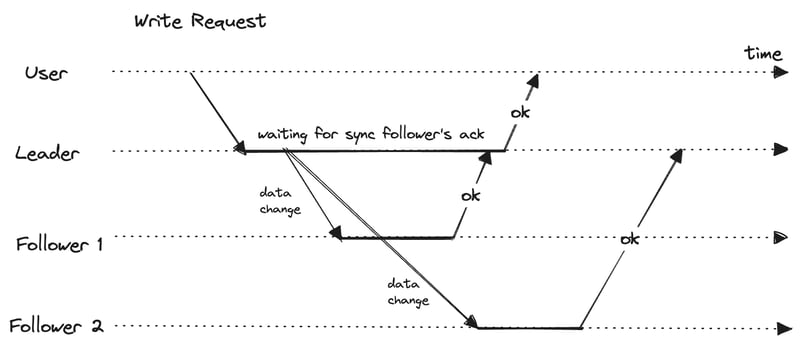
It is definitely impractical to have all the followers as synchronous. Any one node outage would cause the whole system to grind to a halt. If we have a synchronous replication setting enabled on a database, it usually means that one of the followers is synchronous, and the others are asynchronous. If the synchronous follower becomes unavailable or slow, one of the asynchronous followers is promoted to synchronous. It guarantees we have an up-to-date copy of the data on at least two nodes: the leader and one synchronous follower.
In asynchronous replication, if the leader fails and isn't recoverable, any writes that haven't yet been replicated to the followers are lost. It means the writes aren't guaranteed to be durable, even if it has been confirmed to the client. However, the advantage of a fully asynchronous configuration is that the leader can continue processing writes even if all the followers have fallen behind. Weak durability may sound like a bad trade-off, but asynchronous replication is widely used, especially if there are many followers or if they are geographically distributed.
How to add new Followers?
Let's say we want to add a new replica because we want to scale or replace a failed node. Simply copying data files from one node to another is not sufficient. Clients are constantly writing to the database, and the data is always in flux, so a standard file copy would see different parts of the database at different points in time. We can lock the database, making it unavailable for any writes, but that would go against our goal of high availability.
Here is how it's done
- Take a consistent snapshot of the leader's database at some point in time. If possible, without taking a lock on the database
- Copy the snapshot to the new follower node
- The follower connects to the leader and requests all the data changes that have happened since the snapshot was taken
- When the followers have processed the backlog of data changes since the snapshot, we say it has caught up. It can now continue to process data changes from the leader as they happen
Handling Node Outages
Follower Failure
Each follower stores a log of the data changes it has received from the leader on its local disk. If a follower crashes and restarts or the network between the leader and the follower is temporarily interrupted. The follower can recover from its log: it knows the last transaction that was processed before the fault occurred. Thus, the follower can connect to the leader and request all the data changes that occurred when the follower was disconnected.
Leader Failure
What if the leader himself goes down? TLDR; One of the followers is promoted to be the leader. Clients are reconfigured to send all the writes to the new leader, and the followers need to start consuming data from the new leader. This process is called failover.
- There is no foolproof way of detecting what has gone wrong, so most systems use a timeout. Nodes frequently bounce messages back and forth between each other, and if a node doesn't respond for some time - say 30 seconds, it is assumed to be dead. (This doesn't apply if the leader is taken down for planned maintenance)
- Choosing a new leader is done through an election where the leader is chosen by a majority of the remaining replicas, or a new replica could be appointed by the previous leader. The best candidate is usually the replica with the most up-to-date data changes from the previous leader.
- Clients are now reconfigured to send their write requests to the new leader. If the old leader comes back, it might still believe it is the leader, not realizing that the other replicas have forced it to step down. The system has to ensure that the older leader becomes a follower and recognizes the new leader.
The time between when the leader is down and the next leader is getting elected. Writes are blocked or queued in the leaderless period. Consistent reads are served by the replicas if synchronous replication is enabled else there is the possibility that stale and inconsistent data is served because of eventual consistency.
What could go wrong with Failover?
If asynchronous replication is used, the new leader may not have received all the writes from the old leader before it failed. If the former leader rejoins the cluster after a new leader has been chosen, what should happen to the writes that the new leader hasn't received? The new leader may receive conflicting writes in the meantime. The most common solution is to discard the unreplicated changes of the old leader. But, discarding the writes is dangerous business as it violates the client's durability.
In certain fault situations, two nodes might believe that they are the leader. This situation is called split brain, and it is dangerous. If both the leaders accept writes, and there is no process for resolving conflicts, data is likely to be lost or corrupted. As a safety catch, some systems have mechanisms to shut down one node if two leaders are detected.
And finally, what should be the ideal timeout before the leader is declared dead? A longer timeout means a longer time to recover in case where the leader fails. However, if the timeout is too short, there could be unnecessary failovers.
Implementation of Replication Logs
Statement Based Replication
The leader logs every write request that it executes and sends that statement log to its followers. For a relational database, every INSERT, UPDATE, or DELETE statement is forwarded to followers, and each follower parses and executes that SQL statement as it has received from a client. But this approach could break down on statements that call a non-deterministic function such as Now() or RAND() that is likely to generate different values on each replica.
Write Ahead Log (WAL)
This log is an append-only sequence of bytes containing all writes to the database. We can use the same log to build a replica on another node. The main disadvantage is that the log describes the data on a very low level, which makes it tightly coupled to the storage engine. If the database changes its storage format from one version to another, it is typically not possible to run different versions of the database software on the leader and the followers.
Logical Log Replication (row-based)
A logical log is decoupled from the storage engine and uses different log formats for the storage engine and replication. For a relational database, it is usually a sequence of records describing writes to database tables at the granularity of a row. As it is decoupled from a storage engine, it can be made backward compatible, allowing the leader and the follower to run different versions of the database software or even different storage engines.
Parting Words
The first part of the blog series aimed at laying the foundation for future blogs in this series on replication in distributed systems. We still have a lot to discuss on this topic that we will do in the next one.
If you liked the blog, don't forget to share it on Twitter, LinkedIn, Peerlist, and other social platforms and tag me. You may also write to me at guptaamanthan01@gmail.com to share your thoughts about the blog.
References
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann




Top comments (0)