
Seguro que en los últimos años has oído hablar del concepto de microservicios, puede que hayas profundizado en el tema, o incluso llegado a trabajar en algún proyecto en base a microservicios, pero para la mayoría sigue siendo un tema del que muchos hablan pero pocos se han pasado por las manos.
Como cualquier otra tecnología que cobra relevancia, tiene sus defensores y sus detractores, cada uno con su línea de argumentación (totalmente válida). El caso es que existe y que no sea una solución para nuestro proyecto o nuestros proyectos del día a día, no quiere decir que no tenga su caso de uso.
En este post vamos a intentar explicar en líneas generales en qué consiste la arquitectura de microservicios, sus pros, sus contras, problemas conocidos y distintas formas de comunicación. No pretende ser una guía exhaustiva, por lo que no voy a tratar en profundidad demasiados conceptos.
Vamos allá!
Introducción
Habitualmente abreviado como MSA (Micro Services Architecture), es una variación de SOA o Arquitectura Orientada a Servicios (Service Oriented Architecture), y aunque parezca algo totalmente nuevo y actual, se viene hablando, escribiendo y poniendo en práctica desde 1996 (Gartner).
Aunque no sería hasta 2005 cuando Peter Rodgers acuñaría el termino Micro-Web Services durante una presentación en la Web Services Edge conference.
Desde entonces, muchos han sido los que han hablado o escrito sobre el tema:
Y una lista casi infinita de expertos reconocidos. Pero ¿en qué consiste una arquitectura de microservicios? ¿Qué características tiene?
Básicamente, una arquitectura de microservicios consiste en construir una aplicación como un conjunto de pequeños servicios, independientes entre ellos tanto a nivel código como a nivel de infraestructura y que se comunican entre ellos con mecanismos ligeros (baja latencia).
Cada servicio:
- Gestiona una parte de negocio única y exclusivamente
- Debe poder desplegarse y escalarse de forma independiente sin tener esto efecto sobre el resto de servicios
- Puede estar escrito con el lenguaje que mejor se adapte a su propósito, así como usar las tecnologías más convenientes (por ejemplo, bases de datos no-SQL cuando el resto de microservicios usan SQL).
Ventajas
Teniendo en cuenta la anterior descripción, no son pocas las ventajas que nos aporta esta arquitectura:
- Desarrollo modular: Cada servicio tiene una única meta, esto hace que su responsabilidad quede claramente acotada y su equipo de desarrollo puede especializarse en ello, sin interferencias de cambios en otros aspectos del negocio. Es una especie de SRP a nivel módulo.
- Independencia de infraestructura: Los módulos pueden y deben seguir su propio ciclo de vida, desplegarse nuevas versiones cuando sea necesario (sin conflictos o necesidad de esperar a otros). Asimismo, cada microservicio es responsable de su propia infraestructura, incluyendo su propia base de datos.
- Escalado independiente: En un escenario donde tenemos un monolito y de repente tenemos un incremento bestial de un tipo de peticiones en concreto (registros por ejemplo, debido a una agresiva campaña de marketing), nuestra única solución va a ser escalar todo el proyecto a la vez, bien sea de forma vertical (añadiendo o mejorando el hardware) o si hemos sido suficientemente prudentes de tener separada la base de datos y otros servicios en otras maquinas, un escalado horizontal (aumentar el número de servers con servidores web y poner un balanceador de carga al frente). En un sistema basado en microservicios simplemente necesitas escalar de forma horizontal el número de servers que sirven el microservicio de usuarios.
- Optimización del esquema de datos: La independencia de infraestructura, permite que en nuestros modelos de datos guardemos únicamente lo imprescindible para lograr nuestro objetivo. Si por ejemplo disponemos de un microservicio de Posts y uno de Users, podemos guardar en la base de datos de Users tan solo un contador con el número de posts (si solo necesitamos ese dato), y en la base de datos de Posts nos podemos permitir almacenar solamente el id, nombre y apellidos de cada User, ya que no vamos a necesitar nada más en nuestras vistas. Resultado: prácticamente resolvemos todas las consultas a base de datos sin hacer JOIN, consultas directas a índice.
- Independencia de stack: Pueden desarrollarse con el lenguaje que mejor encaje en el problema a resolver, sin tener en cuenta en cuál (o cuáles) se ha desarrollado el resto de microservicios.
Inconvenientes
- Desarrollo más complejo: A medida que el número de microservicios crece, levantar un entorno de desarrollo para cada equipo es más complicado. Además, el debug de estas arquitecturas es bastante más complejo que el de un monolito.
- Versionado de microservicios: La independencia de cada microservicio puede llegar a ser un caos si no se versiona correctamente, ya que puede haber otros microservicios dependientes de uno que se acaba de actualizar que aún no sea compatible con los nuevos cambios, y eso nos obliga a mantener distintas versiones de cada microservicio en marcha que garantice el funcionamiento de todo el enjambre.
- Información duplicada: Gran parte de la información estará duplicada en las distintas bases de datos de los distintos microservicios, ya que cada uno debe de ser independiente a nivel datos.
- Consistencia eventual: Las actualizaciones pueden ser un quebradero de cabeza, por ejemplo, si el usuario decide actualizar su nombre y apellidos, ya que en el microservicio de Posts deberemos de actualizar este dato en todos sus posts. Esto puede dar lugar a problemas de consistencia eventual debido a la latencia entre comunicaciones (el dato se ha actualizado en algunos servicios, pero no en otros).
Arquitectura de microservicios
Como convención, vamos a hablar de diseño de “microarquitectura” cuando nos refiramos a la arquitectura interna de cada microservicio, y diseño de “macroarquitectura” cuando nos refiramos a la arquitectura que los une.
Veamos a continuación algunos detalles a cada nivel.
Detalles de diseño a nivel microarquitectura
La construcción interna de los microservicios no está atada a ningun contrato, ya que como hemos repetido varias veces, cada microservicio es independiente de los demás a nivel infraestructura y a nivel stack tecnológico, pero lo que si es cierto es que hay una serie de técnicas y patrones de diseño que favorecen mucho el mantenimiento de estos, y que al mismo tiempo simplificará en algunos casos la comunicación entre ellos.
Arquitectura Hexagonal
Hemos hablado de arquitectura hexagonal en otras ocasiones, aunque quizá sea interesante dedicar un post entero a tratar el tema, pero para no desviar la atención del tema principal, haré un pequeño resumen.
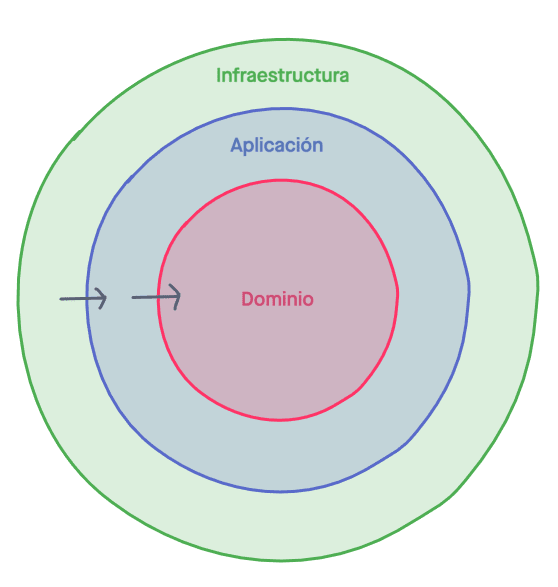
La arquitectura hexagonal o también llamada arquitectura limpia (de Clean Architecture) es una forma de diseñar software por capas haciendo un uso del también conocido patrón adapter. La arquitectura por capas favorece la cambiabilidad de las dependencias de terceros sin afectar a las capas dependientes (inversión de dependencias).
Tenemos tres capas:
- Dominio
- Aplicación
- Infraestructura
Cada una de las capas solo puede conocer a las más internas, es decir, siempre de fuera hacia adentro. Por lo tanto, Infraestructura conoce Aplicación y Dominio, Aplicación conoce a Dominio, y Dominio solo se conoce a sí misma.
Y qué es cada capa?
- Dominio contiene únicamente el código relativo a entidades, value objects, interfaces de servicios… básicamente los contratos que deberá de cumplir el código. En otros contextos lo podemos relacionar con el core de una aplicación.
- Infraestructura son las implementaciones de los contratos definidos en Dominio. Por ejemplo, si tenemos una interfaz del servicio de repositorio UserRepository, en infraestructura podemos tener distintas implementaciones del mismo, por ejemplo RedisUserRepository_,_ DoctrineUserRepository_,_ o ElasticSearchUserRepository por citar algunos ejemplos.
- Aplicación contiene la implementación de casos de uso de nuestra aplicación, como por ejemplo Registrar un Usuario o Publicar un Post. Esta capa solo conoce los contratos definidos en Dominio con lo que cualquier implementación de Infraestructura deberá de ser inyectada como una interfaz de Dominio. Así, para por ejemplo Registrar un usuario necesitaríamos un UserRepository, no importa qué implementación, ya que cualquiera de ellas cumplirá con el contrato y sabremos de qué métodos disponemos.
Viéndolo de forma gráfica quedaría algo así (fíjate en que cada color que representa la capa a la que pertenece):
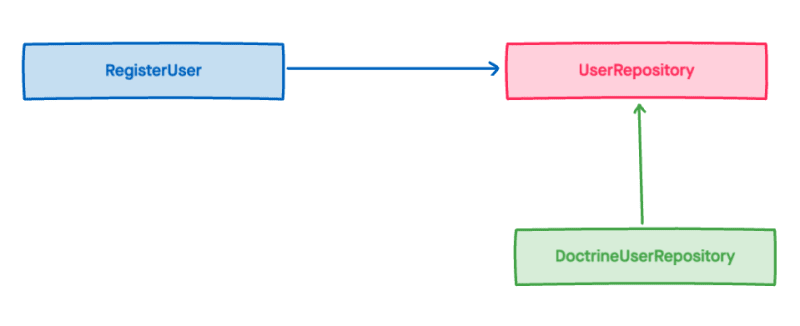
Esto es inversión de dependencias en estado puro, y es lo que hace que nuestro código sea limpio, cambiable, testeable y fácilmente mantenible.
CQRS
Sobre CQRS también podríamos dedicar posts enteros a tratar el tema, pero vamos a tratar de resumirlo de forma simple.
Bertrand Meyer definió originalmente el concepto de Separación de consultas y comandos (CQS) en el libro Object-Oriented Software Construction. La idea básica es que las operaciones de un sistema se pueden dividir en dos categorías claramente diferenciadas:
- Consultas (Queries). Devuelven un resultado sin cambiar el estado del sistema y no tienen efectos secundarios (side effects).
- Comandos (Command). Cambian el estado de un sistema (y pueden tener side effects).
Posteriormente Greg Young introdujo el concepto Segregación de responsabilidad de consultas y comandos (CQRS). Se basa en el principio CQS, aunque con más detalles, por ejemplo, con CQRS se puede tener una base de datos para operaciones de lectura (queries) distinta de la de operaciones de escritura (commands), o distintos modelos de datos para las respuestas de las queries o las peticiones de los commands.
Pero una de las mayores diferencias es la posibilidad de realizar operaciones asíncronas mediante el envío de commands a través de un bus de comandos asíncrono, de forma que no necesitemos esperar a la respuesta de la base de datos para seguir con el hilo de la ejecución.
En resumen a nuestra infraestructura vamos a incorporar una serie de nuevos elementos:
- Commands: Clases que encapsulan operaciones de escritura. Por ejemplo, en el caso de Registrar un usuario este command incluiría el email y la contraseña del usuario registrado.
- Queries: Clases que encapsulan operaciones de lectura. Por ejemplo, en el caso de uso Obtener un post la query incluiría el id del post a obtener.
- Handlers: Tendremos QueryHandlers y CommandHandlers, los QueryHandlers devuelven el contenido deseado, los CommandHandlers, debido a que su ejecución puede ser asíncrona, no devuelven nada.
- Buses: Tendremos QueryBus y CommandBus, y el CommandBus puede ser síncrono (esperamos a la operación de escritura) o asíncrono (no esperamos a la operación de escritura). Básicamente son colas donde metemos las queries y los commands para que se ejecuten.
Veamos gráficamente como quedaría el ejemplo anterior (fíjate en que cada color que representa la capa a la que pertenece):
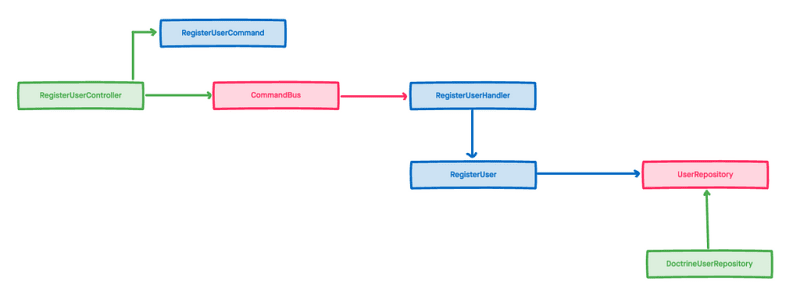
Este bus de asíncrono será la base de lo que más adelante veremos como comunicación basada en eventos.
Detalles de diseño a nivel macroarquitectura
Ahora que tenemos claro como desarrollar nuestros microservicios nos enfrentamos al reto de hacer que hablen entre ellos, que se comuniquen.
Cuando teníamos un monolito esto no implicaba mayor problema, ya que todo quedaba en casa:

Todas las peticiones apuntan al mismo sitio, solo hay una conexión a una base de datos y esa base de datos es la única fuente de datos de toda la plataforma.
Como ya hemos comentado antes, en el caso de que, por ejemplo, la creación de posts se incrementara de forma inesperada, la única base de datos del nuestro sitio se saturaría por las escrituras que está recibiendo por parte de usuarios publicando contenido. Esto por supuesto afectaría al endpoint de obtener usuarios, aumentando los tiempos de respuestas e incluso obteniendo timeouts.
En el caso de tener microservicios la comunicación es más compleja, pero podemos evitar el problema de que un pico de peticiones de un tipo en concreto nos tumbe el sitio entero.
Vamos a ver a continuación distintas formas de comunicación en microservicios.
Formas de comunicación
Microlitos sin infraestructura
Un caso muy común cuando se empieza con a migrar una arquitectura monolítica a una basada en microservicios es romper el monolito en otros más pequeños que popularmente reciben el nombre de microlitos.
El esquema que vamos a ver a continuación sería el de Microlitos sin infraestructura: aunque hemos separado a nivel software el código en distintos servicios, seguimos compartiendo la infraestructura común (en este caso la base de datos).

¿Se puede considerar este esquema como una arquitectura de microservicios? A duras penas podemos decir que cumple con todas las condiciones para ser un esquema de microservicios:
- ✅ Cada servicio gestiona una parte de negocio única y exclusivamente.
- ❌ No puede desplegarse y escalarse de forma independiente sin tener esto efecto sobre el resto de servicios. Si por ejemplo desplegamos una nueva versión del microservicio de usuarios que aplica cambios a la base de datos, puede afectar al microservicio de posts.
- ❌ No son independientes, una sobrecarga de peticiones en el microservicio de posts seguiría perjudicando al microservicio de usuarios.
- ❌ No utilizan mecanismos de comunicación de baja latencia para comunicarse, de hecho, no se comunican, la base de datos es el único intermediario, toda la información obtenido por cada microservicio sale del mismo sitio.
Es un punto de partida, pero no podemos quedarnos aquí indefinidamente, debemos evolucionar nuestra arquitectura.
Microlitos vía HTTP
Una segunda parada en el camino hacia los microservicios independientes es hacer que nuestros microlitos es dejar de compartir la base de datos.
Puesto que el microlito de usuarios solo mantiene datos relacionados con los usuarios, es posible que surja la necesidad de obtener alguna información relacionada con los posts propiedad de ese usuario, por ejemplo, saber el número de posts que ha publicado.
No podemos guardar ese dato, no nos corresponde. Cada microlito expone una API por lo que parece una buena opción que nuestros microlitos se comuniquen vía HTTP para obtener la información necesaria.

Ahora que nuestros microlitos tienen cada uno su propia base de datos no nos preocupa que una sobrecarga en el número de peticiones de crear posts bloqueen el microlito de usuarios… o sí debería preocuparnos?
Aunque somos independientes a nivel código e infraestructura, una eventual caída de otro microlito podría dejarnos fuera de juego también, ya que si el número de peticiones POST aumenta en el microlito de posts, esto afectará también a las peticiones GET que hacemos desde el microlito de usuarios, la base de datos puede seguir bloqueándose y por tanto bloquearnos.
Y cómo solucionamos esto? Circuit Breaker al rescate!
Circuit Breaker
Circuit Breaker es un patrón popularizado por Michael T. Nygard en el libro Release It!, básicamente se basa en el comportamiento que tiene un fusible en un circuito eléctrico: cuando algo se sobrecarga actúa como barrera abriendo el circuito (en electrónica un circuito eléctrico es aquel que esta discontinuado, y por lo tanto no funciona). Cómo se aplicaría esto a microservicios? Miremos el siguiente esquema:

En el la línea de eventos podemos ver como el cliente solicita a un servicio un dato, pero este tiene un intermediario, el circuit breaker. Este circuit breaker esta configurado para tener un umbral de error de 2 reintentos, al segundo fallo abrirá el circuito y dejará de haber comunicación entre cliente y servicio.
Tal y como muestra el gráfico, tras dos errores, la comunicación es cortada y aquí podemos optar por técnicas como mostrar un valor por defecto para el dato consultado (por ejemplo, en este caso, total_posts: 0 sería una solución de compromiso).
Esta apertura del circuito permite al servicio recuperarse de la avalancha de tráfico que le ha hecho caer. Obviamente pasado un tiempo el circuito vuelve a cerrarse y vuelve a aceptar peticiones, pero no voy a entrar en detalle en cómo se hace esto.
Otro dato importante, aunque en el esquema solo se vea un servicio, en una arquitectura de microservicios cloud lo habitual es tener más de un servicio detrás del circuit breaker:

Eventos de dominio
La última forma de comunicación que vamos a ver es a través de eventos de dominio, una forma que desde mi punto de vista tiene una serie de ventajas respecto a escalabilidad bastante interesante.
Partimos del concepto de “dominio” que ya hemos comentado antes cuando hablábamos de arquitectura hexagonal a nivel de diseño de microarquitectura. Como su nombre indica, un evento de dominio representa un suceso que ha ocurrido en nuestro sistema, relacionado con el dominio de nuestra aplicación, nuestro core, nuestra lógica de negocio.
Algunas características de los eventos de dominio:
- Deben de ser serializables en un formato que permita interoperabilidad. Recordemos que nuestros microservicios son tecnológicamente independientes, si emitimos un evento serializado con el formato nativo de nuestro lenguaje (PHP, JAVA, Python…) difícilmente va a ser entendible para otros microservicios que usen un stack diferente. Formatos como JSON, XML o YAML son ejemplos de formatos que permiten la interoperabilidad.
- Deben de ser identificables. Cada evento debe de ser capaz de ser buscado por un identificador único, con lo que debemos asegurarnos de utilizar un sistema de identificación que no lleve a error. Formatos autonuméricos incrementales suelen ser una mala idea: vamos a tener muchos microservicios emitiendo eventos, ¿cómo llevamos la cuenta del autoincremento? Sistemas como los UUID dan garantías de unicidad y también son un formato de identificación interoperable.
- La fecha es importante. Tan importante como su identificación es saber cuándo sucedió. En el caso de eventos es importante poder ordenarlos de forma unívoca (recordemos que no podemos usar identificadores autonuméricos), por lo que la fecha es muy importante. Ahora bien, tenemos que tener en cuenta que el formato de fecha y hora debe de ser interoperable entre distintos stack, por lo que es importante usar formatos como ISO-8601 o POSIX Timestamp. Algo de vital importancia también es usar como zona horaria UTC, ya que podemos tener microservicios operando en distintas zonas horarias y eso puede causar un caos informativo. A través de UTC podemos transformar la fecha a cualquier franja horaria sin mayores complicaciones.
- Han ocurrido ya (pasado). Esto es importante tenerlo en cuenta a la hora de definir una estrategia de nombrado para nuestros eventos de dominio, esto es importante para poder distinguir un evento de dominio (verbos en pasado) de acciones o casos de uso (verbos en infinitivo).
- Formato estandarizado. Además del nombre del evento, también el contenido del evento debe de seguir una estandarización. En el cuerpo de un evento debemos de encontrar la información necesaria para manejar la situación, ya que la respuesta habitual a un evento son los efectos secundarios o side-effects, una respuesta del sistema ante tal evento. Que todos los eventos tengan una estructura similar simplifica el desarrollo de listeners para nuestros eventos de dominio.
- No necesariamente todo evento debe de disparar efectos secundarios. No solo debemos de lanzar eventos cuando deseemos que ocurra un efecto secundario, en una arquitectura orientada a eventos todo suceso debe de quedar registrado, aunque no haya ningún efecto secundario esperando a que suceda un evento. Esto además nos permite llevar un registro (da igual la forma: base de datos, archivos de log…) de todo cuanto sucede en nuestro sistema.
Algunos ejemplos de serializado de un evento de dominio:


Como se puede apreciar en ambos ejemplos, la información relativa al evento se puede expresar de múltiples maneras, lo importante es conservar un esqueleto común a todos los eventos y que el contenido propio de cada evento se adapte a las necesidades de cada caso.

Me gustaría dar una opinión personal al respecto del contenido de los eventos, y es que es mejor añadir información de más que de menos. Hay que intentar adelantarse en la medida de lo posible a las futuras necesidades de los manejadores de eventos, ya que es probable que si actualizamos en algún momento el cuerpo de nuestros eventos, en el momento de hacer el despliegue haya todavía en cola muchos eventos con el anterior contenido, y eso puede darnos pie a errores en el manejo de los eventos.
Comunicación mediante eventos de dominio
Ahora que estamos ya familiarizados con el concepto de eventos de dominio, vamos a ver cómo quedaría nuestra macroarquitectura de comunicación en el siguiente gráfico:

Hemos incorporado un nuevo elemento a nuestra arquitectura de comunicación: el bus de eventos.
Los microservicios ya no se comunican directamente entre ellos, sino que lo hacen a través de un nuevo elemento arquitectural que implementa el patrón Pub/Sub (Publisher/Subscriber). No hemos hablado nunca en el blog sobre este patrón así que vamos a dar unas pinceladas sobre cómo funciona para meternos en contexto.
Patrón Pub/Sub
El patrón Pub/Sub ofrece una forma eficaz de comunicación asíncrona desacoplando a los emisores de mensajes de sus receptores, evitando de esta manera que el emisor quede bloqueado a la espera de una respuesta.
Hay 3 actores principales en este patrón:
- Emisor (Publisher): Es quien lanza un evento, quien decide comunicar que algo ha sucedido, permitiendo a quien esté interesado en reaccionar de alguna manera hacerlo, pero sin depender de la respuesta de estos.
- Bus de Eventos (Message Broker): Es el canal de comunicación donde el emisor publica sus mensajes (eventos) y es este mismo sistema el encargado de notificar a los suscriptores de que se ha producido el evento que están interesados en manejar.
- Subscriptor (Subscriber): Es el cliente, el receptor de el mensaje. No necesariamente debe de haber un único subscriptor para cada mensaje, ni un mismos subscriptor debe de estar esperando un único tipo de mensajes.
Para garantizar la asincronía el bus de eventos suele delegar su capa de transporte sobre un servicio de colas de mensajería como puede ser Redis, RabbitMQ, Apache Kafka, IronMQ, AmazonSQS, MQTT… que disponen de muchas funcionalidades extra que permiten manejar de forma optima todos los puntos oscuros de este patrón, como los eventos desordenados o los duplicados.
Ventajas
- Añade una capa de indirección entre productor de mensajes y consumidores. Esto incluso nos permite tener productores implementados en un lenguaje diferente al que ha sido implementado el consumidor (y viceversa). Este desacople es una de las virtudes por las que la arquitectura de microservicios es elegida.
- Se evitan bloqueos a la hora de esperar una respuesta por parte del consumidor. Si es necesaria una respuesta, la recibiremos por el mismo Bus en el que hemos publicado nosotros el mensaje, y podremos subscribirnos a ella, mientras tanto, podemos seguir con nuestro trabajo.
Inconvenientes
- Añade una capa de indirección entre productor de mensajes y consumidores. La misma virtud puede llegar a ser un defecto en determinados escenarios. Tenemos que estar seguros de no necesitar una respuesta inmediata a nuestro evento. El debug en estos casos también se vuelve mucho más complejo.
- Las colas pueden saturarse y esto puede acabar con efectos secundarios poco deseados, como mensajes duplicados o mensajes que llegan desordenados. Mas adelante profundizaremos en esto.
Por lo tanto, la comunicación de nuestros microservicios ahora queda delegada a un nuevo elemento con gran capacidad de escalado, por lo que no podemos llegar a saturarlos por llamadas internas entre ellos como en el caso de comunicación por HTTP.
Consistencia Eventual
Antes hemos introducido el concepto de consistencia eventual sin entrar en mucho detalle, para hacernos una idea y sin entrar en mucho detalle, podríamos definir la consistencia eventual como el hecho de que la información en todos nuestros microservicios puede no estar perfectamente actualizada en todo momento (no es consistente), pero que tarde o temprano acabará estándolo.
Por qué sucede esto? Es fácil suponer que en un sistema formado por eventos que fuerza la actualización de los datos en distintos microservicios, todo esto no ocurre de forma simultánea ni cohesionada, cada microservicios puede tener sus tiempos, su carga de trabajo, su latencia, sus tiempos de ejecución…
Estamos en un ecosistema muy diverso a muchos niveles: podemos tener múltiples stacks tecnológicos a nivel de microarquitectura, con lenguajes más o menos rápidos, con distintas cargas de trabajo, probablemente con sistemas de bases de datos diferentes que puede que estén optimizadas para lectura y no para escritura o al revés… Así que tenemos que convivir con el hecho de que no todo estará siempre actualizado.
¿Cómo evitar la consistencia eventual?
Ni puedo ni me atrevo a profundizar en este post sobre este tema, ya que daría para una nueva colección de posts, pero sí, existen formas de convivir con la consistencia eventual, por ejemplo con las transacciones distribuidas aunque también tengan sus puntos oscuros .
Hay otras corrientes de pensamiento que afirman que si necesitas que varios sistemas sean siempre consistentes, quizá deberían ser un único sistema.
Sistemas de colas
El uso de sistemas de colas como RabbitMQ, MQTT, Amazon SQS… y otros proveedores es uno de los puntos fuertes de la comunicación basada en eventos de dominio.
Estos sistemas también llamados brokers de mensajería nos permiten comunicar nuestros eventos en una amplia variedad de formas, por mi parte puedo hablar más específicamente de RabbitMQ que es el que más he usado y que me parece muy potente y versátil.
En todo sistema de colas tenemos una serie de actores:
- Productores: Son quienes emiten el mensaje
- Exchange/Broker: Es el sistema encargado de distribuir el mensaje en las colas apropiadas, pueden tener distintas formas de distribución: topic, fanout o direct.
- Colas: Son los recipientes de los mensajes, a las colas se conectan los consumidores para obtener los mensajes.
- Consumidores: Son quienes se conectan a las colas en busca de mensajes que procesar. Si procesan el mensaje de forma correcta devuelven a la cola un código ACK indicando que el procesamiento ha sido correcto, en caso contrario, responderán a la cola con un NACK, provocando que el mensaje sea reencolado para volver a ser consumido posteriormente.
Como antes decía, el broker puede estar configurado para distribuir los mensajes de varias maneras, veamos en el caso de RabbitMQ como funcionan estas tres formas:
- Fanout: Los mensajes recibidos se envían a todas las colas sin excepción.
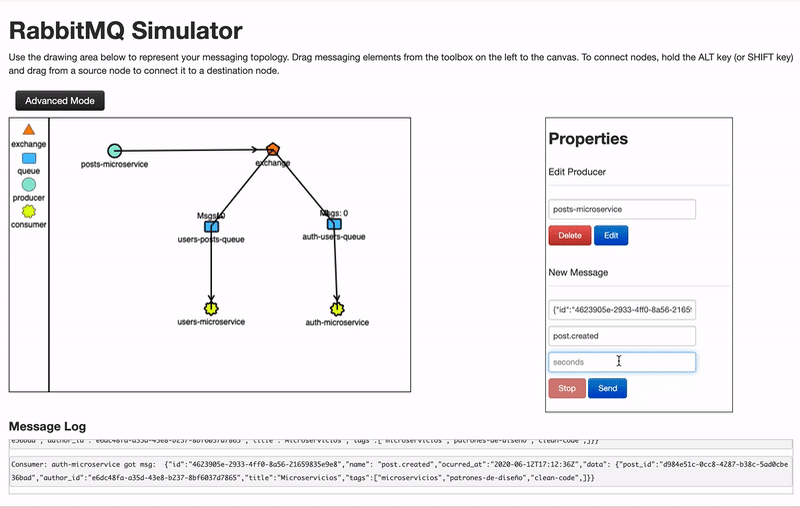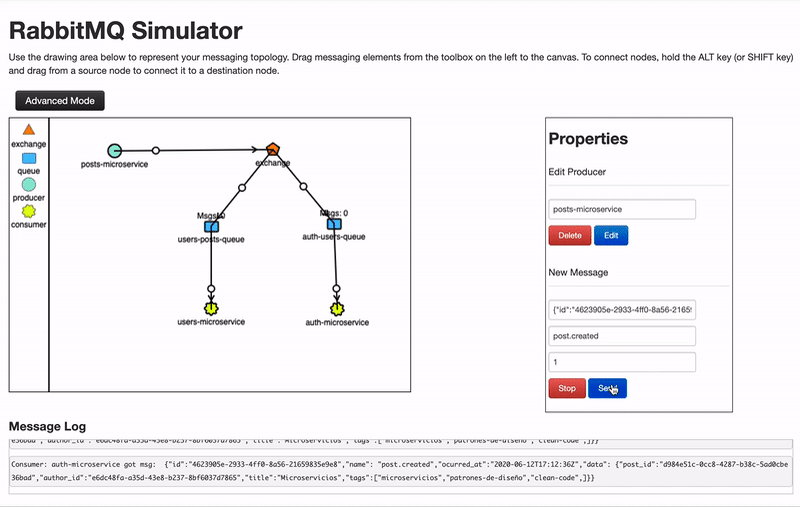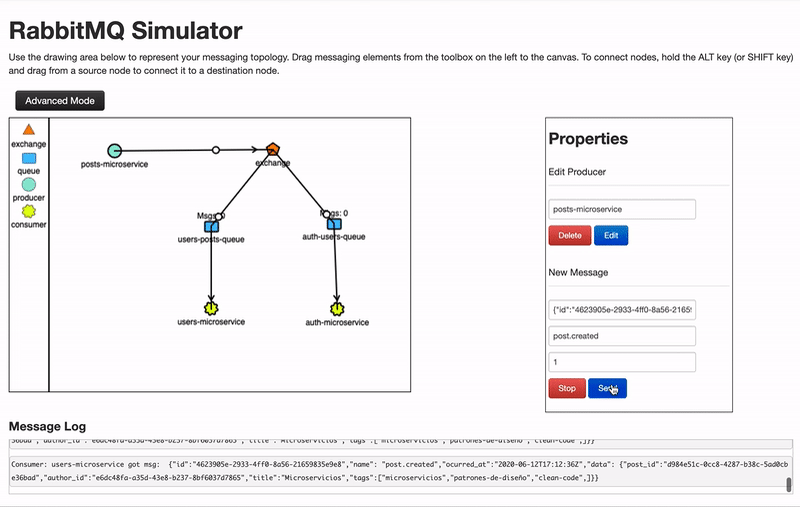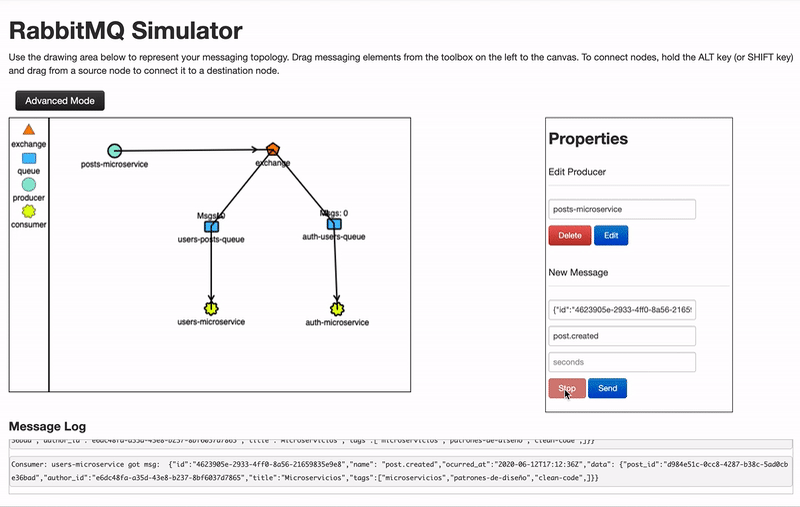
- Direct: El mensaje se publica solo a las colas suscritas a ese tipo de mensaje. El tipo suele ser el nombre del evento producido.
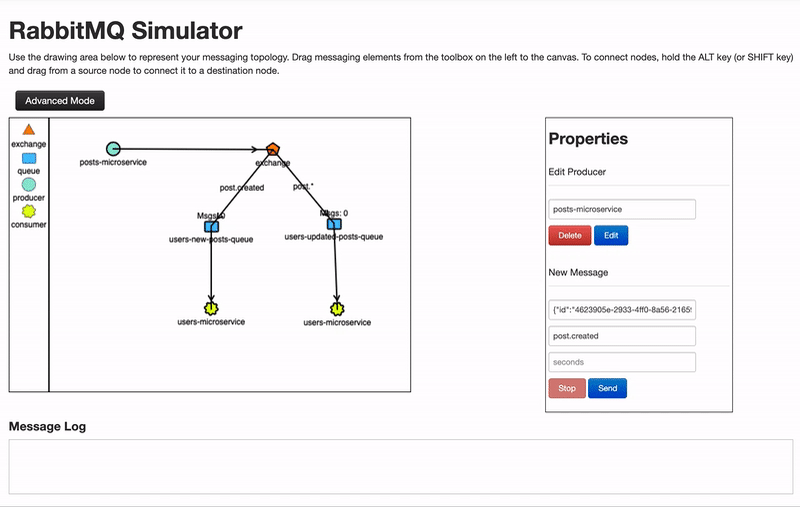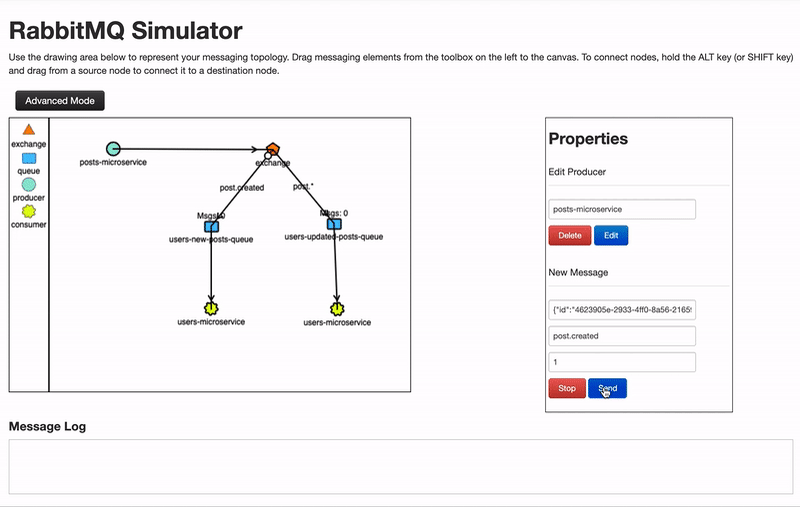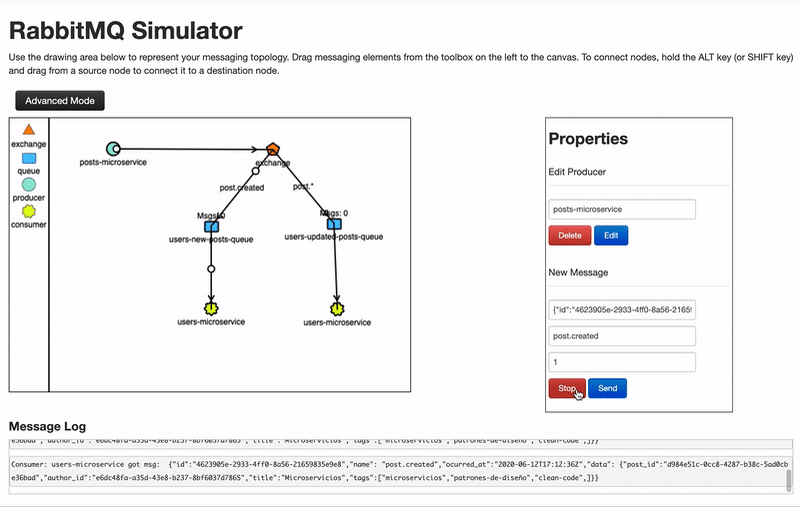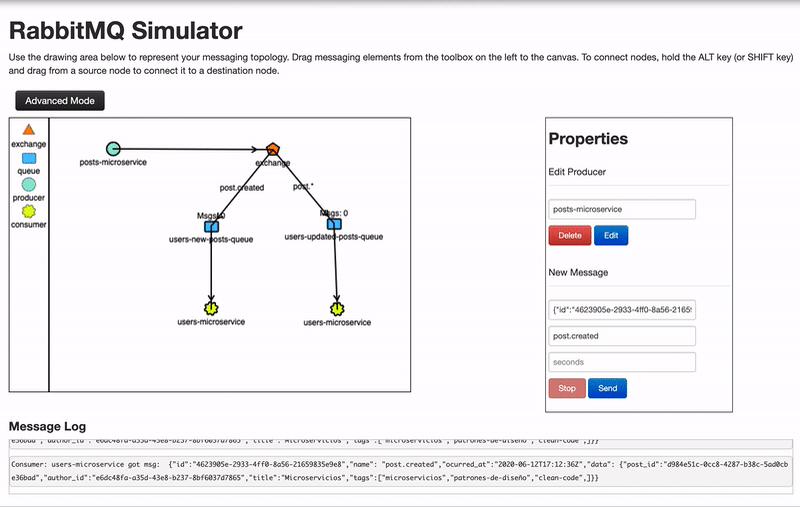
- Topic: Es como direct , solo que permite el uso de expresiones regulares, por ejemplo, en direct la clave o binding key de una cola podría ser post.created_,_ en topic la binding key podría ser post.* y estaría suscrito a cualquier mensaje que empiece por post.

Todos estos modos de operar de las colas nos permiten una amplia flexibilidad, podemos usar por ejemplo el modo topic y crear una cola suscrita a los eventos de tipo *.log y añadir un consumidor que se encarga de hacer un logging de todos los eventos producidos.
Otras ventajas de estos sistemas es su fácil escalabilidad, al tratarse de servicios de infraestructura (como las bases de datos o las cachés), podemos tener tantas instancias como necesite nuestro sistema y crecer de forma indefinida.
Gestión de errores de las colas
Básicamente hay dos errores que se pueden producir al usar eventos de dominio con sistemas de colas, y son los eventos desordenados, y nada lo ejemplifica mejor que este twitt de Mathias Verraes:
Algo que podríamos traducir como:
Hay dos problemas difíciles en sistemas distribuidos:
- Recibir el evento sólo una vez
- El orden de los eventos
- Recibir el evento sólo una vez
Eventos desordenados y Dead letter queues

Hay sistemas de colas que no garantizan el orden de entrega, de hecho, es casi lo más habitual.
Esto puede no ser un problema por sí mismo, salvo que los eventos desordenados sean dependientes entre sí, por ejemplo notificar a un usuario de que su autor favorito ha escrito un nuevo post antes de el evento de que el post ha sido creado haya sido recibido. Esto podría provocar un error de consistencia eventual al tratar de buscar el post si aún no existe en la base de datos.
Una forma de gestionar estos errores es el uso de dead-lettering. Esto básicamente consiste en llevar una cuenta de las veces que un mensaje ha sido devuelto con un NACK, si supera cierto umbral, este mensaje es mandado a una cola de dead-lettering, donde un consumidor especial podrá procesarlo de la manera adecuada:
- Elimándolo
- Notificando a alguien del suceso
- …
Eventos duplicados
Cuando nuestra infraestructura de colas crece y aumentan el número de máquinas que la controlan, existe la posibilidad de que un mismo evento se envíe dos veces o más (por distintas máquinas). Los sistemas de colas distribuidas necesitan mantener los mensajes en un espacio compartido, que bien puede ser memoria o disco duro. En ambos casos se produce una latencia que puede provocar el envío de un mensaje de forma duplicada:
- La máquina A envía el mensaje 815c5068-72e6-40ad-96f1-b0ec7cd57d73
- El consumidor A empieza el procesado del mensaje 815c5068-72e6-40ad-96f1-b0ec7cd57d73
- La máquina B envía el mensaje 815c5068-72e6-40ad-96f1-b0ec7cd57d73
- El consumidor A envía un ACK a la máquina A
- El consumidor B empieza el procesado del mensaje 815c5068-72e6-40ad-96f1-b0ec7cd57d73
- La máquina A elimina el mensaje 815c5068-72e6-40ad-96f1-b0ec7cd57d73
Entre el paso 1 y 6 el mensaje sigue disponible para ser enviado a consumidores, por lo que si el procesado es largo puede provocar que se procese más de una vez.
En realidad los sistemas de colas disponen de mecanismos para evitar estos problemas (sistemas de lock que impiden que se sirva dos veces el mismo mensaje), pero tienen un alto coste en el rendimiento de las colas y suele preferirse prescindir de él y manejar los posibles errores de duplicidades.
¿Cómo gestionamos estos errores?
De nuevo muy a grosso modo vamos a ver unas posibles soluciones:
- Dead Lettering. Si el mensaje no puede ser procesado dos veces, dará un error y el consumidor devolverá un NACK, si esto se produce las veces suficientes, acabará en Dead Lettering y será procesado de otra manera.
- Registro de mensajes ejecutados. Podemos llevar un registro con el id de todos los mensajes ejecutados, y antes de ejecutar un nuevo mensaje, comprobar si ya ha sido previamente ejecutado. Esto en un entorno de muchos consumidores para un mismo mensaje, puede seguir dando problemas, ya que mientras se registra el mensaje como procesado podría volverse a procesar.
- Idempotencia . Este concepto nos garantiza que la misma ejecución de un evento repetidas veces producirá el mismo resultado. Por ejemplo, en el caso de un evento de post.created intentaremos volver a insertar ese registro en nuestra base de datos, si obtenemos un error porque el registro ya existe, simplemente ignoraremos el error y devolveremos un ACK a la cola. Otra opción sería antes de intentar insertar el registro comprobar si existe previamente.
Conclusiones
Las arquitecturas de microservicios son complejas, pero resuelven muchos problemas de escalabilidad y crecimiento allá donde es necesario.
Probablemente si no trabajamos en grandes empresas con tráfico masivo y picos que puedan hacer peligrar la disponibilidad del servicio, jamás nos veremos ante un proyecto que requiera de su uso.
Pero no por ello es una solución innecesariamente complicada o basada en la sobreingeniería, solo lo será si intentamos matar moscas a cañonazos y decidimos implementar esta arquitectura por ser un poco más mainstream o porque es el concepto de moda.
Quizá se hable más ahora que hace 20 años de microservicios porque el número de grandes empresas con estas necesidades ha crecido y ha popularizado el termino, pero eso no lo convierte en un martillo de oro.
Espero que os haya gustado este post, aunque se ha quedado bastante más largo de lo habitual ;)
Saludos y hasta la próxima!

Top comments (0)