Speech synthesis

Speech synthesis is the artificial production of human speech. Text-to-Speech (TTS) is way to converts language to human voice (or speech). The goal of TTS is to render naturally sounding speech signals for downstream such as assistant device (Google’s Assistant, Amazon’s Echo, Apple’s Siri). This story will talk about how we can generate a human-like voice. Concatenative TTS and Parametric TTS are the traditional ways to generate audio but there are some limitations. Google released a generative model, WaveNet, which is a break through on TTS. It can generate a very good audio and overcoming traditional ways’ limitation.
This story will discuss about WaveNet: A Generative Model for Raw Audio (van den Oord et al., 2016) and the following are will be covered:
- Text-to-Speech
- Technique of Classical Speech Synthesis
- WaveNet
- Experiment
Trending AI Articles:
2. Making a Simple Neural Network
Text-to-Speech (TTS)
Technically, we can treat TTS as a sequence-to-sequence problem. It includes 2 major stages which are text analysis and speech synthesis. Text analysis is quite similar to generic natural language processing (NLP) steps (Although we may not need heave preprocessing when using deep neural network). For example, sentence segmentation, word segmentation, part-of-speech(POS). The output of first stage is grapheme-to-phoneme (G2P) which is the input of second stage. In speech synthesis, it takes the output from first stage and generating waveform.
Technique of Classical Speech Synthesis
Concatenative TTS and Parametric TTS are the traditional ways to generate audio by feeding text. As named mentioned, Concatenative TTS concatenate a short clip to form a speech. As short clips are recorded by human, quality is good and voice is clear. However, the limitations are huge human effort for recordings and re-recording if transcript is changed. Parametric TTS can generate voice easily as it stores all base information such as fundamental frequency, magnitude spectrum. As voice is generated, voice is more unnatural than Concatenative TTS.
WaveNet
WaveNet is introduced by van den Oord et al. It can generate audio from text and achieving very good result which you may not able to distinguish generated audio and human voice. On the other hand, dilated causal convolutions architecture is leveraged to deal with long-range temporal dependencies. Also, a single model can generate multiple voices
It is based on PixelCNN ( van den Oord et al., 2016) architecture. By leveraging dilated causal convolutions, it contributes to increasing receptive field without greatly increasing computational cost. A dilated convolution is similar to normal convolution but the filter is applied over an area larger than its length and causing some of input values are skipped. It is similar to larger filter but less computational cost.
From the following figure, you notice that second layer (Hidden Layer , Dilation=2) get current input and the one of previous one input. In next layer (Hidden Layer, Dilation =4), current input and 4 previous one input. During the experiment, van den Oord et al. doubled for every layer up to a limit and then repeated. So dilation sequence is
1, 2, 4, 8, 512, 1, 2, 4 ….
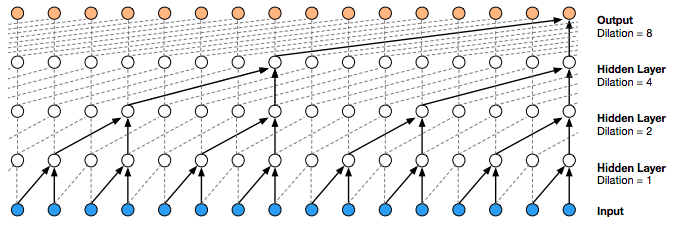
The following animation show the operation of dilated causal convolutions. Previous output becomes input and it combines previous input to generate new outputs.

Experiment
van den Oord et al. conducts four experiments to validate this model. First experiment is multi-speaker speech generation. By leveraging CSTR Voice Cloning Toolkit dataset, it can generate up to 109 speaker voices. More speaker training data lead to a better result as WaveNet’s internal representation are shares among speaker voices.
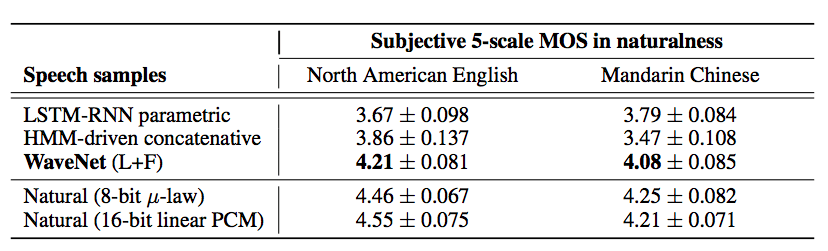
The second experiment is TTS. van den Oord et al. use Google’s North American English and Mandarin Chinese TTS systems as a training data to compare different models. To make the comparison fairly, researchers use hidden Markov model (HMM) and LSTM-RNN-based statistical parametric model as baseline models. Mean Opinion Score (MOS) is used to measure the performance. It is a five-point scale score (1: Bad, 2: Poor, 3: Fair, 4: Good, 5: Excellent). From the following, although WaveNet’s score is still lower than human natural voice but it is better than those baseline models a lot.
The third and forth experiments are music generation and speech recognition. Resear
The following figures hows the latest Google DeepMind’s WaveNet performance.

Take Away
- Google applied WaveNet on Google Assistant such that it can response to our voice command without storing all of the audio but generating it in realtime.
Like to learn?
I am Data Scientist in Bay Area. Focusing on state-of-the-art in Data Science, Artificial Intelligence , especially in NLP and platform related. Feel free to connect with me on LinkedIn or following me on Medium or Github. I am offering short advise on machine learning problem or data science platform for small fee.
Extension Reading
Reference
- Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio. 2016
- Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, Koray Kavukcuoglu. Conditional Image Generation with PixelCNN Decoders. 2016
Don’t forget to give us your 👏 !

https://medium.com/media/c43026df6fee7cdb1aab8aaf916125ea/href




Top comments (0)