
Knowledge distillation is a common way to train compressed models by transferring the knowledge learned from a large model into a smaller model. Today we’ll be taking a look at using knowledge distillation to train a model that screens for pneumonia in chest x-rays.
What is the point?
Let’s say you’re working in an area where privacy is extremely important, like healthcare. It may be the case that we cannot send patient data to the cloud where all our fancy GPU’s live. This creates the need to train a model that can be downloaded and run on a low power machine.
So… what are we working with?
Let’s use the Chest X-Ray Images dataset from Kaggle. The task is to identify pneumonia in chest x-rays.
Pneumonia is a lung infection that causes coughing, fever, chills, and breathing difficulties. It’s caused by an immune response to some kind of infection to the lungs, by virus or bacteria. The ongoing COVID-19 virus can cause pneumonia.
Basically, your lung has air sacs, which is where oxygen and carbon dioxide is exchanged for you to breathe. When these air sacs are infected by virus or bacteria, your body produces an immune response, by inflaming the area with fluid.

Most people can recover from this, but it can cause death in some people due to respiratory failure.
Pneumonia kills many more people in developing countries. While 50,000 people died in the US from pneumonia in 2017, it caused 3 million deaths worldwide.
 Access to high quality healthcare is a major factor in the lethality of pneumonia
Access to high quality healthcare is a major factor in the lethality of pneumonia
Limited access to healthcare infrastructure motivates the need for technology to bring down costs and increase efficiency.
Let’s take a look at the data
With this in mind, given a chest x-ray, we would be looking for cloudy regions that indicate fluids in the lungs.
Here is a normal chest x-ray

Here is an chest x-ray of a patient with pneumonia
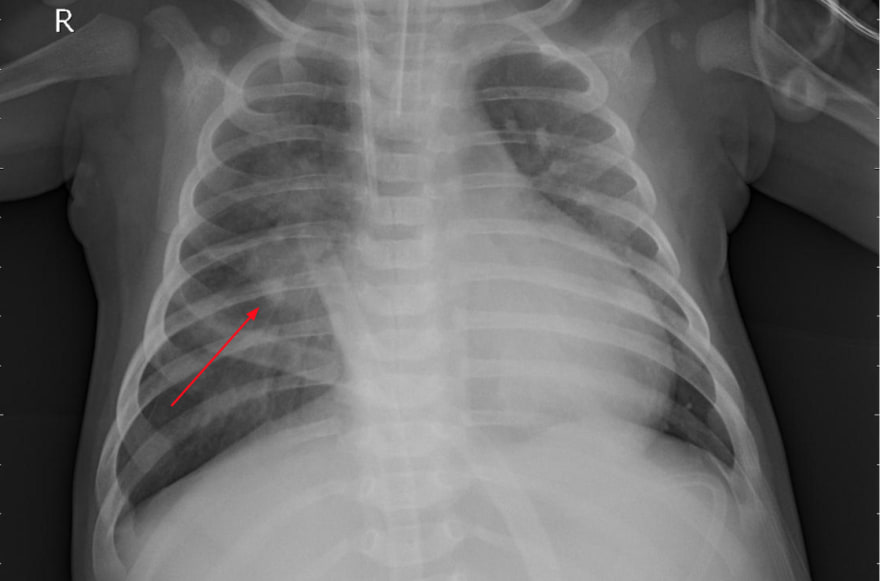 Not so easy to tell the difference is it?
Not so easy to tell the difference is it?
It’s not that obvious why one scan is healthy while the other is infected. From what I’ve researched on this, doctors look for white clumps around the peripherals of the lungs.
So let’s model it!
If you want to skip ahead to the code, go here.
The easiest thing we can do here is simply to throw this into a pre-trained convolutional ResNet model and see how far we can get.
We’ll be using PyTorch and PyTorch lightning to build and train the models.
PyTorch Lightning is a library that will let us modularize our code so we can separate the bits that are common in basically all image classification tasks and the bits that are specific to image distillation tasks.
Let’s start by building a generic BaseImageClassificationTask class to take care of all the boring stuff in image classification tasks like configuring optimizers and loading datasets. See the code here and dataset loading here.
Now, let’s create a simple ImageClassificationTask which can consume any PyTorch image classification model, and compute the cross entropy loss. This sets us up to plug in any PyTorch model that can consume an image and output a prediction.
class ImageClassificationTask(BaseImageClassificationTask):
def __init__(self, net, train_dataset, test_dataset, val_dataset, classes=10, learning_rate=1e-5):
super().__init__()
self.train_dataset = train_dataset
self.test_dataset = test_dataset
self.val_dataset = val_dataset
self.learning_rate = learning_rate
self.net = net
def training_step(self, batch, batch_idx):
# training_step defined the train loop. It is independent of forward
x, y = batch
prediction = self.net(x)
loss = F.cross_entropy(prediction, y)
self.log('train_loss', loss)
return loss
Magically (not really), we can now kick off a training loop. PyTorch Lightning will take care of sampling from data loaders, and back propagating the loss.
checkpoint_callback = ModelCheckpoint(
monitor='val_loss',
dirpath='./checkpoints/',
filename='chest-xray-{epoch:02d}-{val_loss:.2f}-{val_acc:.2f}',
mode='min',
)
trainer = pl.Trainer(max_epochs=40, gpus=1, callbacks=[
checkpoint_callback,
])
model = ImageClassificationTask(ResNet18(num_classes=2), train_dataset, test_dataset, val_dataset)
Here are the results training with ResNet-18 after 40 epochs:
 Validation Accuracy
Validation Accuracy
Final test set accuracy: 91%
How “small” can we make this model?
Remember, the original goal was to build models that can be downloaded and run on low power machines. In this case, let’s build a simple 3 layer CNN as the student model.
We can measure the size of this model in 2 ways:
Model size, which translates to number of parameters
Model speed, which typically translates to number of layers
Size
The ResNet-18 model has 11.7M parameters while the 3 layer CNN has 277,000 parameters. This is a 97.5% reduction in model parameters.
Speed
CPU inference with ResNet-18 takes 45 ms while the 3 layer CNN takes 3 ms. This is a 15x speed up in inference speed.
Do we actually need a teacher?
The first question we should ask is, do we actually need a teacher model? Let’s naively take the our student model and train it with the ImageClassificationTask, as we did with the ResNet model.
Here are the results after 40 epochs:

Test set accuracy: 72%
Distillation
Now let’s build our ImageClassificationDistillationTask class.
The only meaningful difference between the ImageClassificationTask and the ImageClassificationDistillationTask is how the final training loss is computed, as well as some hyper-parameters to configure the loss.
Starting with a trained teacher network and untrained student network
(We already did this with the ResNet-18 above)Forward pass through the teacher model and get logits
Make sure you put the teacher model into a test mode so we don’t needlessly collect gradients.Compute the final loss as distillation loss + classification loss
Backpropagate loss through student model
class ImageClassificationDistillationTask(BaseImageClassificationTask):
def __init__(self, teacher_model, student_model, train_dataset, test_dataset, val_dataset, learning_rate=0.001, temperature=2., alpha=0.5):
super().__init__()
self.learning_rate = learning_rate
self.teacher_model = teacher_model
self.train_dataset = train_dataset
self.test_dataset = test_dataset
self.val_dataset = val_dataset
self.net = student_model
self.temperature = temperature
self.alpha = alpha
def training_step(self, batch, batch_idx):
# training_step defined the train loop. It is independent of forward
x, y = batch
student_logits = self.net(x)
student_target_loss = F.cross_entropy(student_logits, y)
with torch.no_grad():
teacher_logits = self.teacher_model(x)
distillation_loss = nn.KLDivLoss()(F.log_softmax(student_logits / self.temperature, dim=1),
F.softmax(teacher_logits / self.temperature, dim=1))
loss = (1 - self.alpha) * student_target_loss + self.alpha * distillation_loss
self.log('train_loss', loss)
return loss
How does the loss function work?
The loss function is a weighted sum of 2 things:
The normal classification loss, referred to as
student_target_lossin the gist.The cross entropy loss between student logits and teacher logits, referred to as the
distillation_lossin the gist.
The loss is typically expressed in literature like this:
 The first part is the classification loss and the second is the distillation loss
The first part is the classification loss and the second is the distillation loss
The cross entropy loss between the student and the teacher is the main innovation. Intuitively, this trains the student on the teacher’s uncertainty. This is also commonly referred to as the distillation loss. Intuitively, the purpose of this is to teach the student how the teacher “thinks”. In addition to training the student on the ground truth label, we also train the student on the uncertainty of the label that the teacher learned.
If the teacher outputs a prediction of 51% pneumonia and 49% not pneumonia, we also want the student to be equally uncertain.
 An intuitive visualization of distillation loss
An intuitive visualization of distillation loss
This is motivates the need for the two parameters to adjust the behavior of this loss:
Alpha: How much weight we put on the student-teacher loss relative to the normal classification loss
Temperature: How much we scale the uncertainty of the teacher model
Alpha
The alpha parameter controls the weight that is put on the distillation loss. An alpha of 1 means we only consider the distillation loss while an alpha of 0 means we completely ignore the distillation loss.
Temperature
The temperature is a more interesting parameter which scales how “uncertain” the teacher predictions are.
Here’s an example for a model that outputs 3 classes:

Here is how the predictions scale with various values for temperature to scale the uncertainty of these predictions.
 T < 1 makes the model more certain of its predictions
T < 1 makes the model more certain of its predictions
 T > 1 makes the model less certain of its predictions
T > 1 makes the model less certain of its predictions
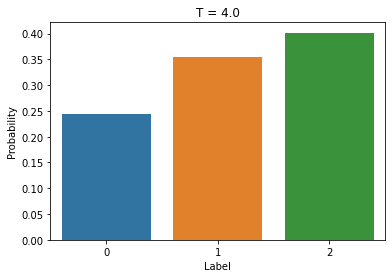 At T = 4, the model is very uncertain compared to the original predictions.
At T = 4, the model is very uncertain compared to the original predictions.
The purpose of the temperature parameter is to control how uncertain the teacher predictions are.
Which hyper-parameters work best?
Here are the final results for the student 3 layer CNN model with different hyper-parameter settings:
 Something weird happened at alpha=0.75 temperature=4. Better performance seems to skew to the upper left of this table.
Something weird happened at alpha=0.75 temperature=4. Better performance seems to skew to the upper left of this table.
The best performing setting by far was alpha = 0.25, temperature = 1, which achieves 86% on the test set. This is an improvement from the original 72% when we just trained the student model from scratch, without distillation.
Here are the final results:

In Summary
We were able to train a model that is 97.5% smaller and 15 times faster than ResNet-18 and is about 5% worse than the teacher model.





Top comments (4)
👏
👏🦾
Very cool!
Wow, this is some advanced ML. Thank you for sharing. More on the advanced side, but super helpful to those who have some working experience with neural networks.