
When you're modeling and building an API, storing ID references to other documents to create relationships between types of data within your domain is paramount to efficient querying, scalability, and even your own sanity.
Imagine you're building the backend for a blog platform and want users to be able to search blog posts by category. So you store the category name on your posts, and you can query for "all posts with a category field equal to 'Tutorials'." But what if you wanted to eventually change "Tutorials" to "Walkthroughs"?
You would have to update not only the category data but every post within the category too. If you instead store an ID for the category, the name — or any other property — can change, and the ID will still reference the correct object and keep the relationship alive.
Most service providers for databases and API-driven SaaS products provide a mechanism to make this easy for developers. Stream Feeds has enrichment for users and collections in your Activities and MongoDB allows you to store a ref via an ObjectID that points to a document in another collection. In both cases you can store a reference to another thing and have it "auto-populate" when you query for the data and the ID you stored is replaced with the full document.
However, MongoDB cannot auto-populate an ID for anything other than another MongoDB document that is stored in the same database. You can't reference the ID of a Stream activity and expect it to just show up. At least, not out-of-the-box. The same applies to Stream: We can only enrich data for IDs that reference other "Stream Objects" — like collections or users.
This is just a fact of life for a developer, and it's not even necessarily a bad thing. Most platforms work this way so they can remain efficient, keep as much control as possible in their customers' hands, and allow you as the developer the flexibility to use whatever combination of tools, services, and APIs you see fit.
But what if we could do better? What if we could teach a GraphQL API to understand all of our data, regardless of its origin or implementation, so that we can enrich data seamlessly and bidirectionally between the tools, services, and APIs that comprise our stack?
Sounds idealistic right?
What We'll Be Building
Funnily enough, building this kind of nested relationship is something that GraphQL is designed to handle. Today, I'm going to walk through a relatively quick and simple example of how you can use Stream Feeds with @stream-io/graphql-feeds (our new, early-release GraphQL toolset for Stream Feeds) and extend the provided types to produce functionality such as this:
As you can see, there is a new custom field search — on the Feed itself — that will utilize Algolia under the hood, take full advantage of everything Algolia offers for best-in-class search, but will ultimately return actual Stream Activities rather than a list of search results with references to activities, collection entries, or users.
Disclaimer: In this tutorial, I aim only to introduce the concepts of relationships across different services with a GraphQL API as the middleman, and how
graphql-feedscan be leveraged in this way. We are going to gloss over some details such as authentication, which in this case will not be production-ready. In later posts we will expand on this example, add a database to go beyond Stream Collections, implement better authentication, and so much more.
Initial Setup
To get started, rather than step through the linting and babel setup and installing dependencies, I've created a template repository so you can get straight to coding with the same setup I'm using.
If you have the GitHub CLI installed (brew install gh) you can run the following command:
If you don't have/want the GH CLI, you can clone the repo as normal, or create your own repo from the template on the GitHub website, and then clone to your local machine from there.
Once you have the repo on your computer, cd into it and run yarn (you will also need to run git pull origin main if you created using the GitHub CLI).
Lastly, create a .env file in the root and paste in the following:
This is everything we need to get up and running! You'll no doubt notice that src/index.js (our entry point) is an empty file. We'll be getting to this next — but first, let's get that .env filled out and make sure we have everything set up for Stream and Algolia.
Stream
For Stream, this tutorial will be easiest when using a new/empty Feeds App. You can take the things you learned and apply them to your own existing projects later.
Go to the Stream Dashboard (create an account if you haven't already) and once you're logged in, click "Create App" in the top right.
Then, on the next screen, grab your Stream API Key, Secret, and App ID:
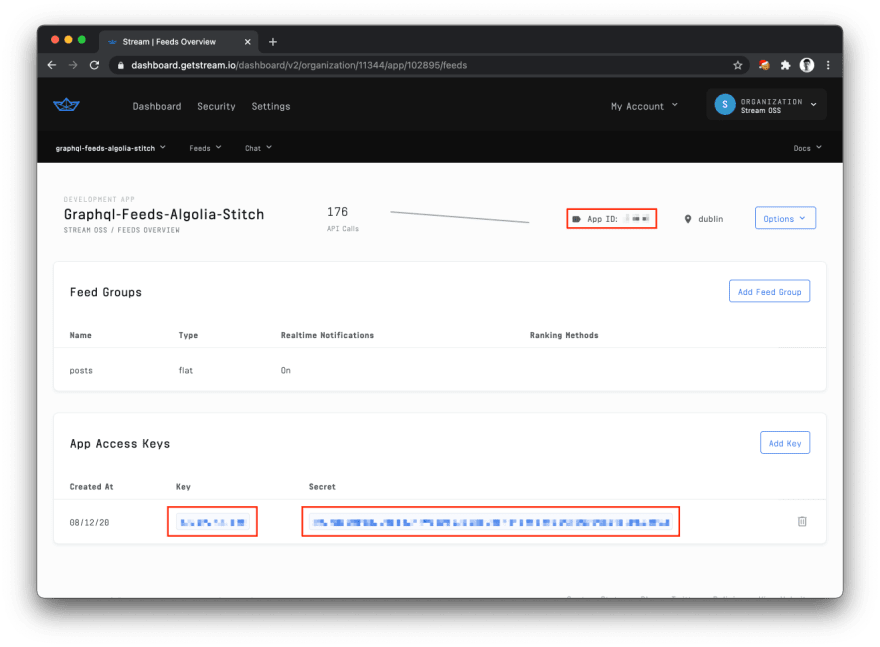
Add these to the correct spots in the .env file from above and we're pretty much ready to move over to Algolia!
We just have one more quick task in the Stream Dashboard: Click the "Add Feed Group" button in the dashboard (visible in the above screenshot) and create a new Flat feed group called "posts".
Algolia
Next, you'll need an Algolia account. You can set up a free trial on their website and spin up an Algolia application in just a few seconds.
Once set up, you will be presented with the Algolia dashboard and a drawer on the right side with instructions to set up your search indexes etc. Click "Create Index" and enter POSTS for the name.
After clicking "Create", you will be redirected to the "index" screen.
Algolia is now ready to integrate into our API; however, we'll take this opportunity to add some facets to our index so we don't have to come back here later on.
First, click "Configuration" in the tabbed toolbar at the top of the index management screen, and choose "facets" from the sidebar menu on the left beneath "Filters and Faceting".
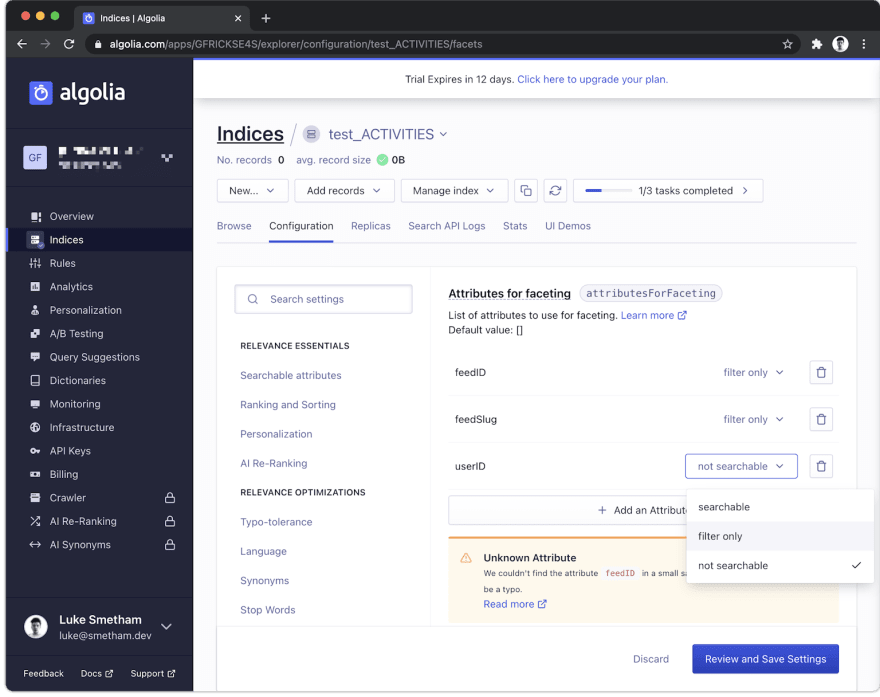
We will add a new facet for the following fields feedID userID and feedSlug. This data does not exist yet in your Algolia index, so you will see the following warning below:

This can be safely ignored as we will be adding objects containing these fields very shortly.
Now, make sure all of the facets are set to "filter only" by selecting it from the dropdown for each list item, and once done, click "Review and Save Settings".
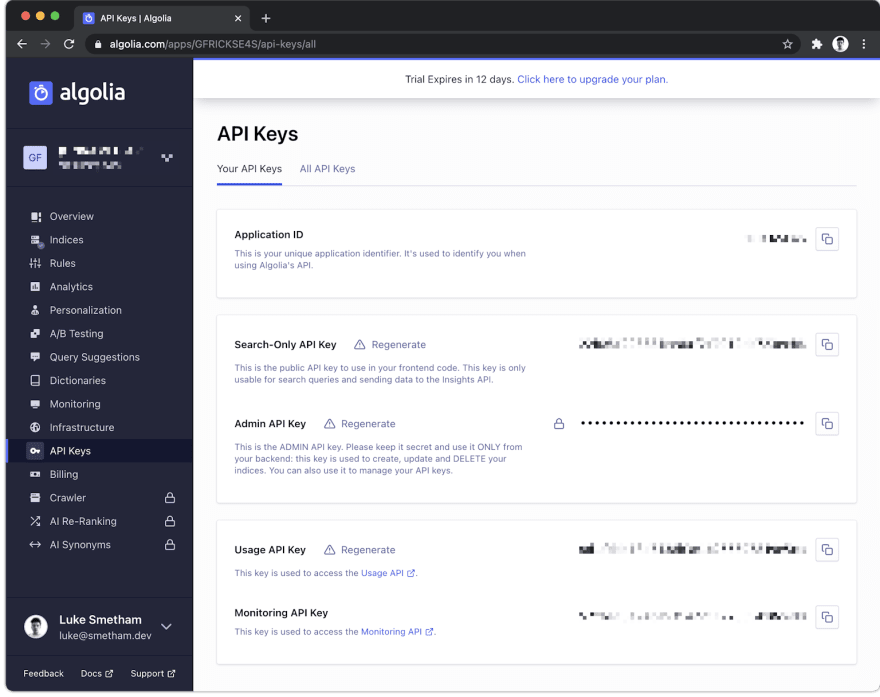
Lastly, we need to get our Algolia Admin Key and App ID from the "API Keys" page and add them to our .env:
Now we can finally start to write some code! 🤓
Initialize the API
Now that we have everything set up for our environment, we can start to implement apollo-server. The concepts from here on out apply to pretty much all JS GraphQL server libraries, and if you're using something like apollo-server-express, the setup will be pretty much identical.
Disclaimer: We will not be implementing authentication in this example and instead just passing the Stream token along as a means of identifying the user. In subsequent articles, we will learn to stitch in MongoDB and create custom authentication and user management.
Let's create a new file, inside of a new directory, in the src folder: src/schema/index.js
Now, back in our empty src/index.js we can add the following:
In future posts, we'll likely swap this out and implement apollo-server-express to give us extra capabilities — but this will serve us well for the purpose of this tutorial!
All we do here is import the schema and dataSources that we exported from schema/index and pass them to a new ApolloServer instance. At this point, you can run yarn dev and the GraphQL Playground should open up on localhost:4000 and you will see the feeds schema in the "Docs" tab — but we still need a couple more things for everything to actually work when you call one of the resolvers.
Context and Authentication
Every resolver in GraphQL receives the following arguments:
Context in GraphQL is most commonly used to authenticate a request and pass along the user object or ID to be utilized in your resolvers.
One common example of this is when GraphQL APIs often have a me query that returns profile data for the user performing the query. This is usually achieved by verifying the Authorization header in the req and adding an ID or user object to the context. The user is then available in all of your resolvers, so you can make resolvers that are "scoped" to the authenticated user.
This leads to an important point with GraphQL Stream, and although it's a little outside the scope of this article, it's worth mentioning, even if only briefly. When using Stream in this way, you need to implement authentication yourself because the server client is, by nature, allowed to make authenticated admin requests due to the use of your API secret.
I will cover this in more detail with the Mongo and Auth examples as it will be implemented slightly differently from the context we create today. But, with the setup we have in this tutorial, there are two ways to handle this that I can quickly explain:
- Verify the token yourself with
jsonwebtokenand the Stream secret environment variable as the signature. Then you can use the JWT payload along with anything else in your context to perform auth checks, fetch user data, etc. - If the Stream token is in the
reqheaders, override the secret when creating the "Stream Context". This will make GraphQL Stream work like the client-side SDK, where users can only request their own data.
For this tutorial, we'll be keeping this pretty light and focusing on relationships between Stream and Algolia rather than authorization. However, we will be using an implementation similar to option 1 above to scope requests to the user. We just won't be performing any auth checks explicitly beyond "is there a valid Stream token in the request headers".
So, what is the Stream Context?
The "Stream Context" mentioned above refers to a helper method exported from the feeds schema that will add both the Feeds Client, and a GQL Subscriptions Helper for realtime feeds to the context object.
Let's create a new file src/schema called context.js and add the following code:
To quickly explain what's going on here:
- The context function gets called on every request, and receives an object containing either
reqorconnectiondepending on whether the transport ishttp(s)://orws(s)://respectively. - We then grab the Bearer Token from the
Authorizationheader (this will be a Stream User token in this case) and if it exists, verify the JWT with our secret. - The resulting payload is then stored as
context.auth, and therefore made available to all of our resolvers from here on out. (We could, for example, check whether this exists and throw an error if not for resolvers we want to protect.) - Finally we call
createFeedsContextfrom@stream-io/graphql-feedsand pass our credentials fromprocess.env.
Last but not least, let's go back to index.js, import our context creation method, and pass it to ApolloServer.
Just like that, we're ready to start writing resolvers, and we're discovering the power and flexibility of Stream Feeds combined with GraphQL.
Before we continue:
Let's do a super quick recap into what our resolver context now looks like and why:
As you can see above, we now have the payload from our JWT containing the ID of the authenticated user, dataSources with a search property with key/value referecences to our Algolia indexes (just search.posts in our case), and finally, the Stream context including an initialized Stream Feeds server client.
The Ultimate Feeds Setup
Okay, so that claim might be a little rich, but I firmly believe this is the easiest, fastest way to get set up with Stream Feeds — especially as a beginner or feeds newbie — and start poking around.
You can totally ignore the authentication part and only include the Stream context to have an unrestricted GraphQL playground where you can test how data moves around in your Stream Feeds application before you even think about writing any code — not to mention the frontend.
Check the @stream-io/graphql-feeds README for quick examples for getting started with apollo-server and apollo-server-express with subscriptions and more.
I digress, but beyond the benefits of creating your own Stream Feeds sandbox to play around in, the real silver bullet lies with the ability to "teach" our datasources how to understand each other and return data in one unified object.
Back in our src/schema/index.js, let's start by amending the code slightly to utilize "schema stitching".
As you can see, we have imported stitchSchemas from @graphql-tools/stitch and added our feeds schema as a "subschema".
When you save and the playground refreshes, there will be no change in functionality and everything will work exactly as before. So what happened? 👀
Schema stitching (@graphql-tools/stitch) creates a single GraphQL gateway schema from multiple underlying GraphQL services. Unlike schema merging, which simply consolidates local schema instances, stitching builds a combined proxy layer that delegates requests through to many underlying service APIs. graphql-tools.
As defined above by graphql-tools, stitching is almost definitely overkill for our use case in the scope of this tutorial. Merging can be more appropriate depending on your setup or where the schema is kept, but we can go into more detail on this in a later post.
However, implementing stitching now allows us to set ourselves up on the right foot for stitching in additional services in later articles (like Mongo, S3 etc.), and helps to illustrate another really awesome thing about GraphQL: Technically, the feeds schema (or your own extended and customized instance of the feed schema) could live on a totally different server somewhere else as a "microservice" of sorts, and you can still stitch it in and access it in the exact same way.
See the above graphql-tools links for more information on exactly how this works with remote schemas. But don't go anywhere just yet — it's about to get good. 😉
We now need to create two new files in our schema directory, one to define our custom type definitions, and one to teach GraphQL how to resolve them from our data.
First, let's create src/schema/typeDefs.js and add this:
In the above snippet, we are writing a GraphQL SDL (Schema Definition Language) string that tells Apollo that we want to:
- Add a type called
Post- Essentially the "model" for our Stream Collections entries
- Add an input type called
CreatePostInput- An input type can be used to define the shape of non-scalar argument for a Query, Mutation or Subscription (this is like defining the "model" for what the arguments of your resolvers will look like if the are not a scalar type).
- Then we extend the
StreamUsertype from@stream-io/graphql-feedsbecause our users will have names.- The base
StreamUsertype has two properties-
id- to uniquely identify this user. -
token- to optionally request the the token for this user (if auth allows it) - This is intentionally bare-bones so you can extend the type to suit your domain. If you want the
nameproperty to be anIntfor some reason, go for it!
-
- The base
- Finally, we tell Apollo that there will be a
createPostresolver of typeMutationthat returns the newly created Activity.- If you're new to GQL, in simplified terms:
Queryis akin toGEToperations in REST, whereasMutationis like a catch-all forPOSTPUTandDELETEoperations.
- If you're new to GQL, in simplified terms:
At this point, you can go back into your src/schema/index.js file and amend it to import your typeDefs and pass them to the gateway schema created by stitchSchemas.
Going back to the playground, you should see our new types in the "Docs" and "Schema" tabs. Try searching "Docs" for StreamUser or createPost!
However, attempting to run createPost right now will fail. We have told Apollo that there will be a resolver called createPost but it still has no way of actually running this Mutation. We also added a new field to the StreamUser type — but how do we make all this actually work?
Back in src/schema let's create a new file as a sibling to typeDefs called resolvers.js and start out by creating the createPost resolver:
Technically with graphql-feeds you can just use the provided addActivity mutation, but to add custom behavior like saving to Algolia, we can use the above approach to wrap our own custom functionality around the original resolver.
Libraries like graphql-compose have helpers such as withMiddlewares to achieve a similar effect.
To break it down:
- We first destructure some keys from our context for later on, and check if there is a
user_idin ourauthpayload that came from the JWT. - Next, we take our
args.data(which is of typeCreatePostInput) and use the feeds client in context to create a collection entry. - We then take the returned data, and use the
idfrom the payload to reference the post entry in our activity. - Then we create the activity by using
delegateToSchemato call our stitched feeds schema and pass off the task of creating the activity, but instead of passing the args along as-is, we construct the feedId ourselves with String Interpolation and theuser_idfrom our auth context. - Finally we add some data to our Algolia index about the activity, and return the
Activityobject we got back from thedelegateToSchemacall.
With this in place, we can import our schema/resolvers.js file into our schema in the same way we did the typeDefs:
Opening up the playground, you can now run createPost and your new Post will be added to a Stream Collection, referenced in an activity on a feed, and then added to our Algolia index for later too.
Before that, let's quickly create a user and get a token so everything works as expected:
This will create a new StreamFeeds user, with the name Luke and id luke (change these to whatever you like), and we are requesting that the mutation return us the token for this user if successful.
Now copy the token, and in the bottom left of the playground, open up HTTP Headers and add the following:
And finally, the moment of truth: Create a new tab in the playground and run this mutation:
Assuming it succeeded, you just created a post, an activity, and added it to the Algolia index! 🎉
You can verify that this worked by going into Algolia and viewing the index. You should see the newly created object that represents your post.
We're nearly there! This is a fairly long post, but hopefully, you're still with us 😛
At this point, you can add activities to your heart's content — and I recommend you do! Add varying strings in the text so that the search results are varied once we implement the remaining resolvers.
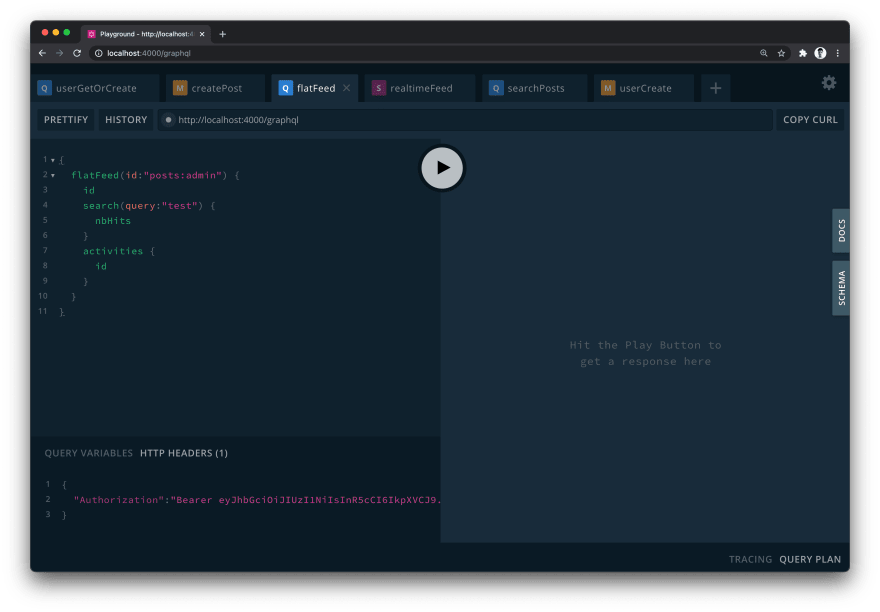
You can also run the flatFeed query to view your activities in a regular Stream Feed (remember to switch the id argument to include the user id you just created):
You will see the results in the exact shape we request above, for each activity in the feed!
Searching with Algolia
Now all that's left is to implement a resolver that can call Algolia, but before returning the response to the playground, it will revisit our typeDefs and resolve any custom fields we have in there. This is the magic of relational data in GraphQL.
For this to work, we need to create a type for the response we get from Algolia. Open up src/schema/typeDefs and somewhere within the type defs string add this:
If you have used Algolia before you will recognize this shape, except for one crucial difference.
We tell Apollo that hits will return an array of StreamActivities rather than the usual array of objects from Algolia that match your query. So if we were to call a resolver that returned a SearchResponse right now, it would fail because hits wouldn't match the expected response in the schema.
This is great for utilizing Algolia more efficiently without worrying about storing data that is only there to display in the UI, i.e. the Title of an article. Algolia has a limit on the size of objects, just like Stream has a limit on Activity size. So with this solution, you only need to store an ID to create the relationship within GraphQL, and enough data to perform the queries and faceting you want.
However, if we create a resolver for this field in our resolvers object, we can tell Apollo to do something different with specific fields. This is where the first argument of all resolvers, source, becomes useful.
The source object will always be the original, untouched response — in this case, from Algolia. So with that in mind, let's go back to our schema/resolvers file and add the following property to the resolvers object. (Should be in the "root" of the object, not nested beneath Mutation, or any other type.)
Query, Mutation and Subscription are just types, known as Root types. When you create a new type, e.g. StreamActivity, it is also a root type. So to define how GraphQL should resolve its fields, you can add a StreamActivity property to the resolvers object just like we did for Mutation.
Now Apollo knows that instead of giving you the hits directly from Algolia, it should flatten the results into a list of IDs, and pass these along to the getActivites method from Stream which returns activities in batch by their IDs.
Finally, add the following to resolvers.js and typeDefs.js respectively:
Adds the query resolver we can use to search activities. We only ask for the
objectIDfrom Algolia as it is all we need to get the activities. (Algolia has already taken care of the search.)
With that, you can run the following query and return actual Stream Activities, but using Algolia as the search engine.
Bonus
From here the possibilities are endless, especially when you consider that Algolia or Stream in this instance could be any SaaS service, database, library etc that you choose. But things are still somewhat "separate" within the schema.
The searchPosts query will return all posts in your Stream app regardless of user, and it's a standalone resolver. However, what if we wanted to search just one feed? At this point it should be relatively straightforward to add a new argument to searchPosts that accepts a valid facet or filter string for Algolia. This would be great addition, but we can do better. 😏
Open your typeDefs again and add the following extension to the StreamFlatFeed type:
Here we add a new field to the StreamFlatFeed type. This is exactly what we did with the hits field for SearchResponse. The difference is that there is no search key in the source object for a feed. There is, however, an id for the feed.
Back in resolvers.js, let's teach Apollo how to resolve the search field:
This is slightly repetitive, and realistically, we could store this resolver method elsewhere and utilize the same function for searchPosts and this StreamFlatFeed.search. But in essence, we call Algolia again from our dataSources, this time passing a filters argument to the options object that will scope all results of the search to the "parent" feed that we are requesting.
And by running the above query in the playground, you can see that your StreamFlatFeed now has a nested property for searching its own activities! 🎉
The best part is that if you don't request it, Algolia will never get called! The resolver will only run if it has been asked to run.
Extra Footnotes
One topic area I didn't cover in this article is the object field, enrichment, and some of the quirks of enriching the object and actor fields either with Stream's own enrichment, or via a GraphQL field like we have discussed today. I strongly recommend reading this next section if you plan on playing around with GraphQL feeds — but feel free to skip it for now. There is more information on all of these concepts in the README when you're ready.
The actor and object fields in a Stream Activity are versatile. This is excellent when using Stream in any other setting, but when actually creating the schema we can't define actor or object as a definite type. Ultimately, it's up to you what those fields look like.
More often that not, these will be IDs referencing documents stored elsewhere — like in MongoDB — with which we can utilize the methods above to, in the case of actor, for example, add a new field actorData, and define a resolver for this field that takes the [source.actor](http://source.actor) value and uses it to resolve the full object from Mongo etc.
However, we also offer "Collections" with Stream Feeds, which can be utilized to store larger objects (like user profile data) that you can later reference in activities (like our posts). If you are using collections, it makes a lot of sense to pass the enrich flag when you request activities and have the data automatically appear in the feed without extra boilerplate or extra network requests.
Because of this, the actor and object fields are of type JSON in the schema, which allows them to be objects, arrays but also a String. This provides perfect flexibility but also means these fields are always JSON (JSON is a Scalar with no subfields) as they inherit from a shared Interface.
So, we can't override with a new type that graphql can then resolve, and we can't define nested relationships for fields within the object or actor should they be embedded objects. (Technically we could override it via something like graphl-compose but depending on your setup this can cumbersome for the sake of one field. It should be easy to use this schema however you want, regardless of you GraphQL client or Node stack.)
This may change down the line as this library matures, but right now the recommended approach if you use Streams enrichment is as follows (assuming the user has an identical shape to that used in this post):
and in your resolvers you can define the resolver for the actorData field like so:
Assuming you called the feed like the below query (with the enrich option), you would now be able to access a typed version of the actors profile data that you can go on to extend and add more nested fields too if you feel necessary.
We're Outta Here!
That's all, folks! There is a lot to go over here so thank you if you made it this far down the post! Hopefully, you learned a little about GraphQL — or at least how Stream can now start to be implemented in your GraphQL APIs. Also a massive thank you to our friends at Algolia for a consistently amazing product.
You can also check out the finished code for this tutorial here.
The @stream-io/graphql-feeds library is still very young and very much a work in progress, but expect more posts very soon, where we can expand further on what's possible with Feeds and GraphQL.

Top comments (1)
Nice one! Thanks for the awesome content, Luke! 👏