
This post illustrates how one can use the open-source Forestplot package to plot estimates with confidence intervals.
This package plots correlation coefficients or regression estimates from upstream analyses (see this example of correlation analysis).
Prepare the package and load the data
To install the package from PyPI:
pip install forestplot
Load example dataset that reports how certain factors correlate with the amount of sleep one gets:
import forestplot as fp
df = fp.load_data("sleep") # companion example data
df.head(3)
| var | r | moerror | label | group | ll | hl | n | power | p-val | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | age | 0.0903729 | 0.0696271 | in years | age | 0.02 | 0.16 | 706 | 0.67 | 0.0163089 |
| 1 | black | -0.0270573 | 0.0770573 | =1 if black | other factors | -0.1 | 0.05 | 706 | 0.11 | 0.472889 |
| 2 | clerical | 0.0480811 | 0.0719189 | =1 if clerical worker | occupation | -0.03 | 0.12 | 706 | 0.25 | 0.201948 |
In the above dataframe, each row is an individual characteristic with a corresponding correlation coefficient from correlating the characteristic with the amount of sleep one gets per night.
The first row, age, for instance, with a correlation coefficient of 0.09 (p = 0.016), says that people who are older get more sleep.
(See this notebook to see how the correlation coefficients are computed from the real sleep75.csv data.)
Plot the estimates
Forest plots (or coefficient plots, dot plots, coefplots) are useful to visualize the estimates and their confidence intervals.
To plot the estimates in df:
fp.forestplot(df, # the dataframe with results data
estimate="r", # col containing estimated effect size
ll="ll", hl="hl", # columns containing conf. int. lower and higher limits
varlabel="label", # column containing variable label
ylabel="Confidence interval", # y-label title
xlabel="Pearson correlation" # x-label title
)

Customizing and adding annotations (Pt. 1)
You can add variable group subheadings (e.g. the Labor Factors subheading) and sort the estimates (within groups). You can also sort the order of the variable group subheadings (group_order):
fp.forestplot(df, # the dataframe with results data
estimate="r", # col containing estimated effect size
moerror="moerror", # columns containing conf. int. margin of error
varlabel="label", # column containing variable label
groupvar="group", # Add variable groupings
# group ordering
group_order=["labor factors", "occupation", "age", "health factors",
"family factors", "area of residence", "other factors"],
sort=True # sort in ascending order (sorts within group if group is specified)
)

Customizing and adding annotations (Pt. 2)
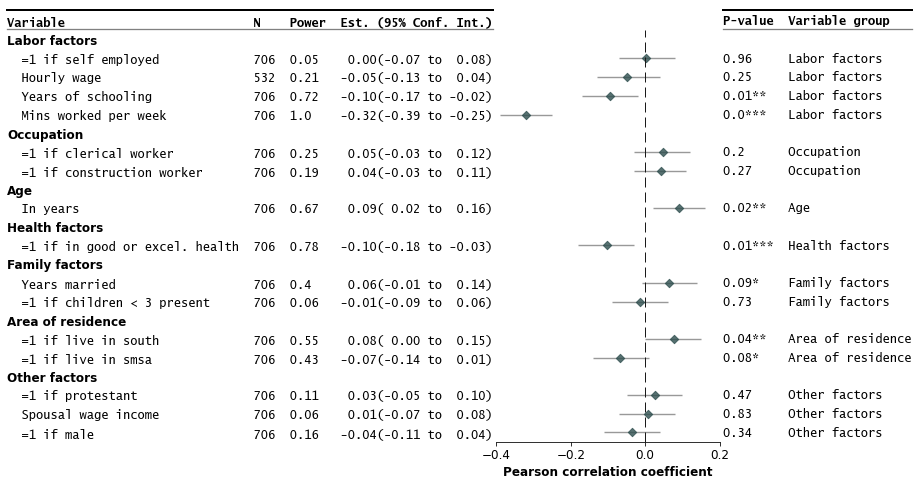
You can also add more annotations to the plot, such as the sample size (e.g. N and formatted_pval) and add table lines:
fp.forestplot(df, # the dataframe with results data
estimate="r", # col containing estimated effect size
ll="ll", hl="hl", # lower & higher limits of conf. int.
varlabel="label", # column containing the varlabels to be printed on far left
pval="p-val", # column containing p-values to be formatted
annote=["n", "power", "est_ci"], # columns to report on left of plot
annoteheaders=["N", "Power", "Est. (95% Conf. Int.)"], # ^corresponding headers
rightannote=["formatted_pval", "group"], # columns to report on right of plot
right_annoteheaders=["P-value", "Variable group"], # ^corresponding headers
groupvar="group", # column containing group labels
group_order=["labor factors", "occupation", "age", "health factors",
"family factors", "area of residence", "other factors"],
xlabel="Pearson correlation coefficient", # x-label title
xticks=[-.4,-.2,0, .2], # x-ticks to be printed
sort=True, # sort estimates in ascending order
table=True, # Format as a table
# Additional kwargs for customizations
**{"marker": "D", # set maker symbol as diamond
"markersize": 35, # adjust marker size
"xlinestyle": (0, (10, 5)), # long dash for x-reference line
"xlinecolor": ".1", # gray color for x-reference line
"xtick_size": 12, # adjust x-ticker fontsize
}
)

Final remarks
Planned future enhancements include allowing for multiple estimates per row in the plot.
Forest plots have many aliases. Other names include coefplots, coefficient plots, meta-analysis plots, dot plots, dot-and-whisker plots, blobbograms, margins plots, regression plots, and ropeladder plots.
This posts hopefully gives my forestplot package some visibility. At the the same time, happy to hear comments about the API's ease of use and features. plot. See the GitHub repo readme for a more substantial documentation.
 LSYS
/
forestplot
LSYS
/
forestplot
A Python package to make publication-ready but customizable coefficient plots.
Forestplot

Easy API for forest plots.
A Python package to make publication-ready but customizable forest plots
This package makes publication-ready forest plots easy to make out-of-the-box. Users provide a dataframe (e.g. from a spreadsheet) where rows correspond to a variable/study with columns including estimates, variable labels, and lower and upper confidence interval limits.
Additional options allow easy addition of columns in the dataframe as annotations in the plot.
| Release |
  
|
| Status |
|
| Coverage |  |
| Python |  |
| Docs |
 |
| Meta |
 |
| Binder |
Table of Contents
show/hide
Installation
Install from PyPI
pip install forestplot
Install from conda-forge
conda install forestplot
Install from source
git clone https://github.com/LSYS/forestplot.git
cd forestplot
pip install .
Developer installation
git clone https://github.com/LSYS/forestplot.git
cd forestplot
pip install -r requirements_dev.txt
make lint
make test
Quick Start
import forestplot as fp
df =…
Top comments (0)