What is the best way to share huge NumPy arrays between python processes?

A situation I’ve come across multiple times is the need to keep one or multiple NumPy arrays in memory that serve as the “database” for specific computations (e.g. doing collaborative or content-based filtering recommendations).
For a scenario where you want to be able to have a web server using those arrays, you need to use multiprocessing in order to use more than one CPU, as I’ve discussed in this previous article.
Having to use multiple processes means we have some limitations when it comes to sharing those NumPy arrays, but fortunately, we have many options to choose from and that’s exactly what we’ll see in this article.
We’ll see how to use NumPy with different multiprocessing options and benchmark each one of them, using ~1.5 GB array with random values.
For the examples, I’ll mostly use a ProcessPoolExecutor, but these methods are applicable to any multi process environment (even Gunicorn).
Strategies that we’ll explore and benchmark in this article
IPC with pickle
This is the easiest (and most inefficient) way of sharing data between python processes. The data you pass as a parameter will automatically be pickled so it can be sent from one process to the other.
Copy-on-write pattern
As I explained in a previous article, when you use fork() in UNIX compatible systems, each process will point to the same memory address and will be able to read from the same address space until they need to write to it.
This makes it easy to emulate “thread-like” behaviour. The only issue is that you need to keep that data immutable after the fork() and only works for data created before the fork().
Shared array
One of the oldest ways to share data in python is by using sharedctypes. This module provides multiple data structures for the effect.
I’ll be using the RawArray since I don’t care about locks for this use case. If you need a structure that can support locks out of the box,Array is a better option.
Memory-mapped file (mmap)
Memory-mapped files are considered by many as the most efficient way to handle and share big data structures.
NumPy supports it out of the box and we’ll make use of that. We’ll also explore the difference between mapping it to disk and memory (with tmpfs).
SharedMemory (Python 3.8+)
SharedMemory is a module that makes it much easier to share data structures between python processes. Like many other shared memory strategies, it relies on mmap under the hood.
It makes it extremely easy to share NumPy arrays between processes as we’ll see in this article.
Ray
Ray is an open-source project that makes it simple to scale any compute-intensive Python workload.
It has been growing a lot in popularity, especially with the current need to process huge amounts of data and serve models on a large scale.
In this article, we’ll be using just 0.001% of its awesome features.
Benchmarks
All benchmarks use the same randomly generated NumPy array that is ~1.5GB.
I’m running everything with Docker and 4 dedicated CPU cores.
The computation is always the same, numpy.sum().
The final runtime for each benchmark is the average runtime in milliseconds between 30 runs with all the outliers removed.
IPC with pickle
In this approach, a slice of the array is pickled and sent to each process to be processed.
Total Runtime: 4137.79ms
Copy-on-write pattern
As expected, we get really good performance with this approach.
The major downside to this approach is that you can’t change data (well, you can, but that will create a copy inside the process that tried to change it).
The other major downside is that every new object that was created after the fork() will only exist inside the process that is creating it.
If you’re using Gunicorn to scale your web application, for example, it’s very likely that you’ll need to update that shared data from time to time, making this approach more restrictive.
Total Runtime: 80.30ms
Shared Array
This approach will create an array in a shared memory block that allows you to freely read and write from any process.
If you’re expecting concurrent writes, you might want to use Array instead of RawArray since it allows using locks out of the box.
Total Runtime: 102.24ms
Memory-mapped file (mmap)
Here, the location of your backing file will matter a lot.
Ideally, always use a memory mounted folder (backed by tmpfs). In Linux, that usually means the /tmp folder.
But when using Docker, you need to use the /dev/shm since the /tmp folder is not mounted in memory.
Total Runtime with /tmp: 159.62ms
Total Runtime with /dev/shm: 108.68ms
SharedMemory (Python 3.8+)
SharedMemory was introduced with Python 3.8, it’s backed by mmap(2) and makes sharing Numpy arrays across processes really simple and efficient.
It’s usually my recommendation if you don’t want to use any external libraries.
Total Runtime: 99.96ms
Ray
Ray is an awesome collection of tools/libraries that allow you to tackle many different large scale problems.
Modern workloads like deep learning and hyperparameter tuning are compute-intensive, and require distributed or parallel execution. Ray makes it effortless to parallelize single machine code — go from a single CPU to multi-core, multi-GPU or multi-node with minimal code changes.
— https://www.ray.io
Here we’ll just explore two different ways to share NumPy arrays using Ray. Soon I’ll showcase better and more detailed use cases for Ray.
One thing to take note of is that I’m not counting ray.init() in the total runtime. That line of code can take around 3 seconds but you only need to call it once, so it shouldn’t be a problem in production scenarios.
It does make these benchmarks a bit unfair since, for all the other scenarios, the Process Pool initialization is being counter for the total runtime.
Because of this, in the final results, I’m also excluding that pool initialization from the runtime.
Using a naive approach, where Ray will need to serialize/deserialize data like the first scenario that uses pickle, we can still see a big improvement in total runtime where comparing to pickle.
Total Runtime: 252.08ms
A better approach for this use case is to use Ray Object Store.
We can even have it backed by Redis, but in this example, it will just use shared memory.
We can see a high improvement with this small change.
Total Runtime: 70.65ms
One thing I really like about Ray is that it allows you to start “small” with very simple and efficient code and then scale your project as your needs get bigger (from a single machine to multi-node cluster).
Final Results
For the final results, and to make a fair comparison with Ray, I’m excluding the time taken to init the processes inside theProcessPoolExecutor since I also excluded the ray.init() from the Ray benchmark.
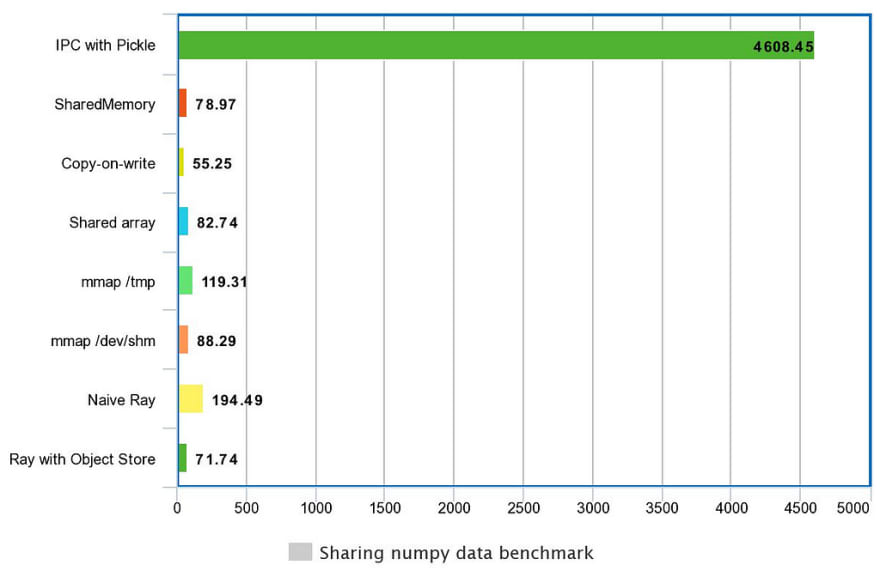
Communicating through pickle is so slow that it’s even hard to understand the other benchmarks, let’s remove it for clarity.

Conclusions
Sharing a global variable before forking (copy-on-write) seems to be the fastest, although also the most limited option.
When using mmap, always make sure to map to a path that is in memory (tmpfs mount).
SharedMemory has a really good performance and a simple and easy to use API.
Ray with the its Object Store seems to be the winner if you need performance and flexibility. It’s also a good framework to grow your project into a bigger scope.
Want to learn more about python? Check these out!
- Gunicorn vs Python GIL
- Gunicorn Worker Types: You’re Probably Using Them Wrong
- Understanding and optimizing python multi-process memory management
- Creating the Perfect Python Dockerfile
How does this all sound? Is there anything you’d like me to expand on? Let me know your thoughts in the comments section below (and hit the clap if this was useful)!
Stay tuned for the next post. Follow so you won’t miss it!

Top comments (0)