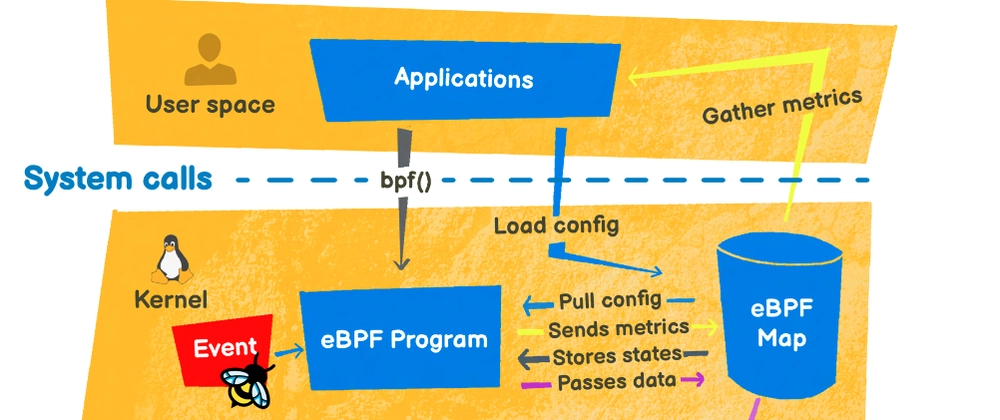
I'm getting started with eBPF programming with Aya. The idea behind this series of articles is to get you started too.
This section is dedicated to eBPF maps. We'll learn how to create, use and differentiate them. As this is the most important concept in eBPF, it's well worth devoting a whole section to it.
We will first fix a bug in the Aya program from the previous section by introducing an eBPF map. This will explain what an eBPF map is. Then we'll improve the program with another map.
FYI, this is the English version of an article originally published in French.

My first eBPF map
We'll pick up where we left off in Part 2. If you want to skip it or start again cleanly, you can clone the dedicated repo and go to the tracepoint-binary directory:
git clone https://github.com/littlejo/aya-examples
cd aya-examples/tracepoint-binary
Check that it compiles correctly:
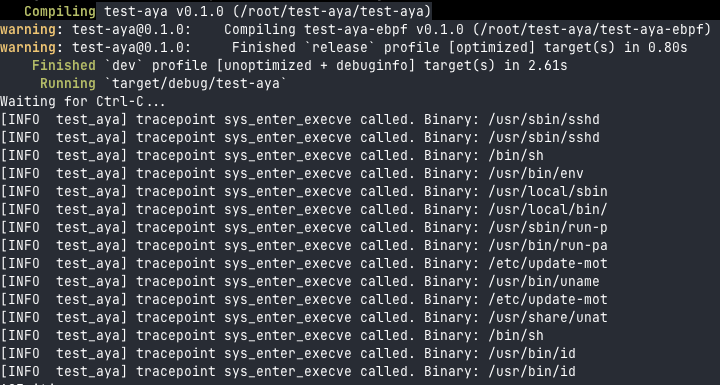
RUST_LOG=info cargo run #We're seeing binaries executed on the computer
You can also do the Killercoda lab, which follows step-by-step the creation and use of eBPF map :
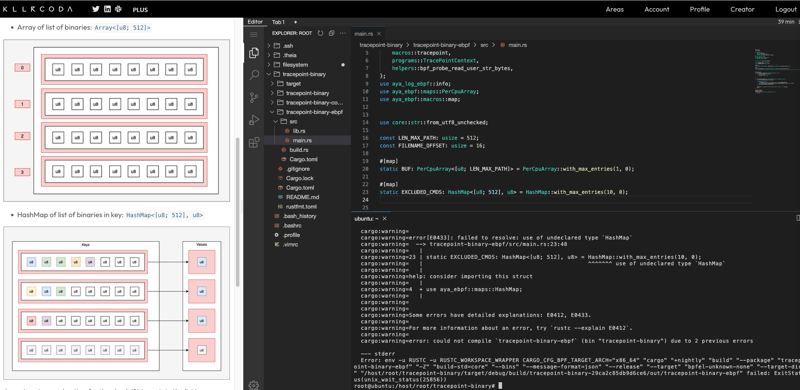
What's wrong with it?
As we saw in Part 2, the program that allows you to see which binaries are being executed works well. But we notice that the display is truncated:
Why? The answer can be found in these lines from the tracepoint-binary-ebpf/src/main.rs file:
const LEN_MAX_PATH: usize = 16;
[...]
let mut buf = [0u8; LEN_MAX_PATH];
This creates an array of bytes with 16 entries. Remember that we're in UTF-8. For ASCII characters: a character is encoded on one byte. This is not always true, for example, for smileys (like this one: 🦀 or 🐝), which are encoded on 4 bytes. So, at best, you're limited to 16 characters (actually, it's 15 to be precise, as there's an end-of-string character \0).
Your first limit
The first intuition is to increase this array. For example, we're going to go wide, we're going to try: 512 bytes.
const LEN_MAX_PATH: usize = 512; //from 16 to 512
Compiled, we have a big failure:
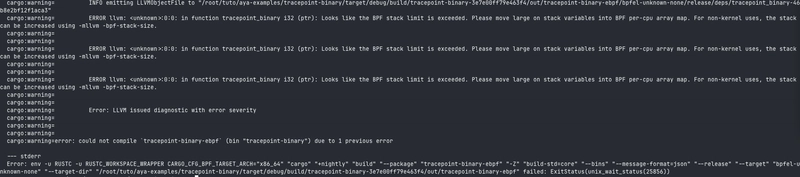
Image is probably too small. So:
Looks like the BPF stack limit is exceeded. Please move large on stack variables into BPF per-cpu array map. For non-kernel uses, the stack can be increased using -mllvm -bpf-stack-size.
In fact, the memory stack for eBPF is limited to 512 bytes. In other words, the sum of all variables cannot exceed 512 bytes. As I mentioned in Part 2, variables with predefined sizes are stored in a stack at memory level, and dynamic data cannot be stored in kernel space.
One solution, of course, is to reduce the number of entries in the array. But as the program grows, it will eventually reach this limit again. So we need to find a long-term solution: the eBPF map.
How to create an eBPF map?
As the error message suggests, you need to create a “per-cpu array” eBPF map. How do I do this?
Let's see the documentation:
- You can click on maps link and you see eBPF maps:
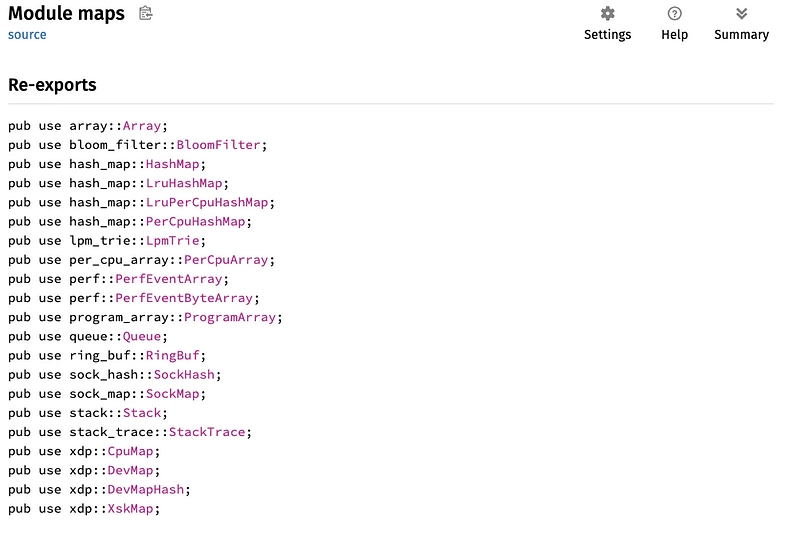
- We choose PerCpuArray:
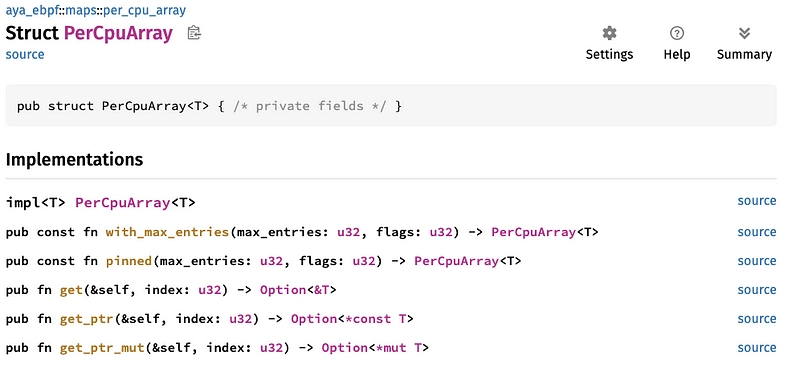
This map is not very well documented. We don't know what with_max_entries() or pinned() are used for, for example. All we can see is that it creates a map of type PerCpuArray. We've got a 50/50 chance 😃
Let's look at another map that's better documented: CpuMap.
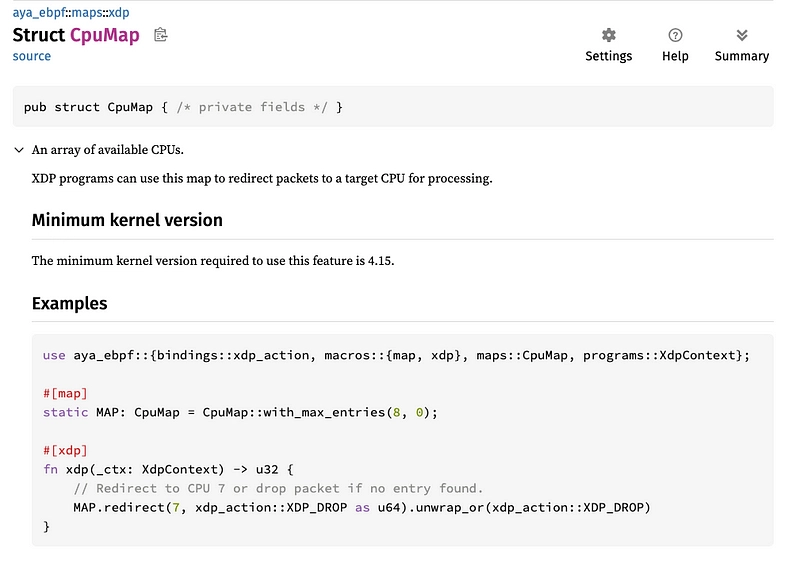
This shows the difference between the two functions:
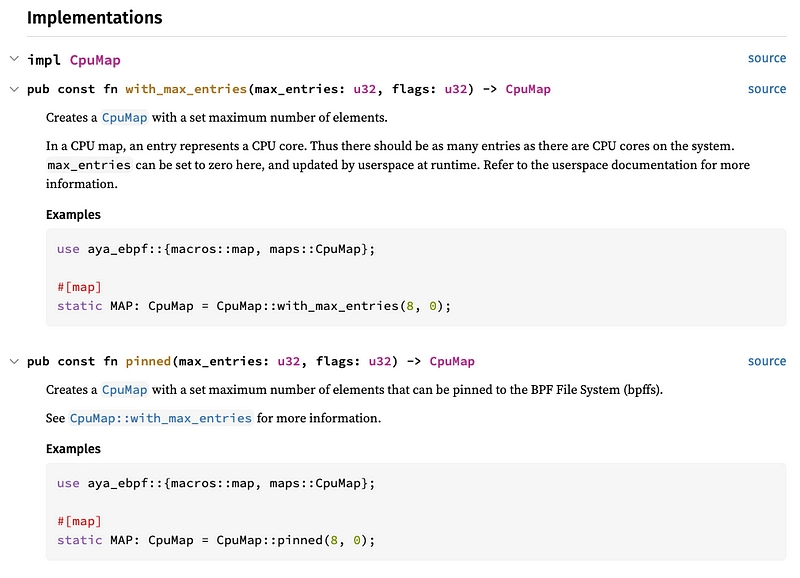
As we don't really want to store this map, I think the with_max_entries() function will suffice.
The aim is to replace a list of 512 bytes, so we'll create a list of integers (of type u8) of length 512:
#[map]
static BUF: PerCpuArray<u8> = PerCpuArray::with_max_entries(512, 0);
- The first line is a macro for creating a map (fortunately, there was an example in the documentation - you can't make it up yourself!)
- we want a static variable (we haven't really seen this notion, it's a variable that remains until the end of the program; see the Rust Book for more information, but it's not fundamental to the rest of the program)
-
BUFis the name of the variable and has the structurePerCpuArray<u8>. - the
with_max_entries()method has two arguments: the number of inputs per CPU and a flag (set to 0, to be discussed later)
Schematically, we have this:
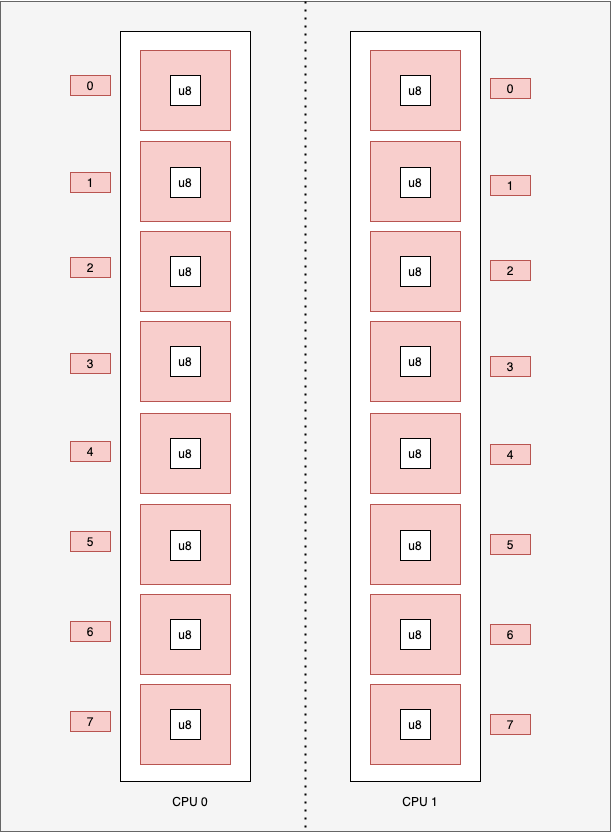
How to modify an eBPF map?
We've just created a map. But how do we replace this line :
let mut buf = [0u8; LEN_MAX_PATH];
So that the buf variable can be used here :
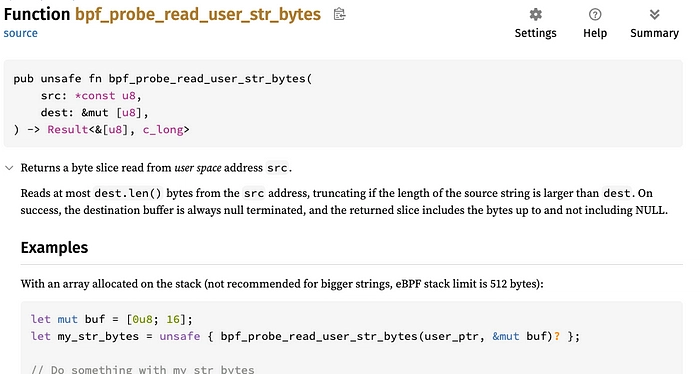
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut buf)?;

The methods available for the map are fairly limited:

So for example to access to the second entry:
There is no conversion to a list. So we're on the wrong track. The map we've created is not good. There is no spoon!
Let's see again the documentation:
How about changing <T>? With methods, you can have just one value. But if <T> is a list instead of an integer, we'll get the value of the list!
So instead of <T> = u8 we would have <T> =[u8; 512].
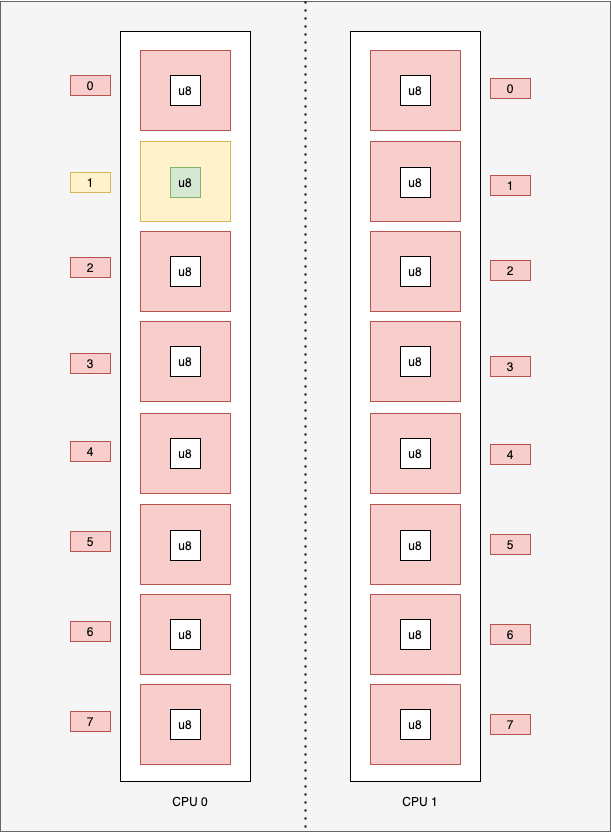
If we have only one entry, schematically, we have this:
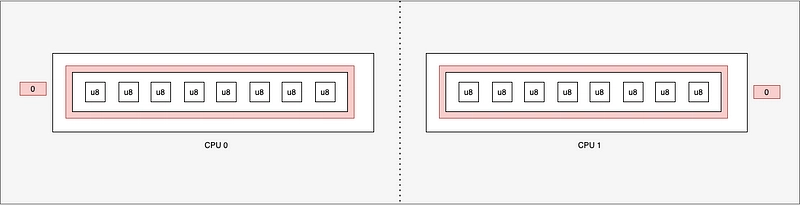
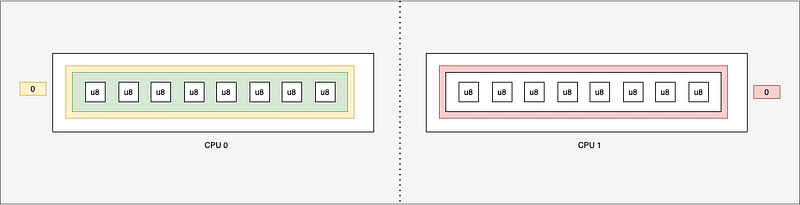
In place of the other map, we'll replace it with the following line:
static BUF: PerCpuArray<[u8; LEN_MAX_PATH]> = PerCpuArray::with_max_entries(1, 0);
- We only set one entry as we only have one list.
Don't forget to add libraries at the beginning of the code:
use aya_ebpf::maps::PerCpuArray; // To retrieve the structure map
use aya_ebpf::macros::map; //to be able to use map macros
Now that we've created this map, how do we use it in the main function code? Let's take a look at the different methods:

-
get()will provide the reference to the contents of a map index. This will give us the read-only value of the list. -
get_ptr()provides the pointer to the contents of a map index. This will give the value of the list as a constant -
get_ptr_mut()allows you to obtain the pointer to the contents of an index in the map, and modify its contents.
So we need get_ptr_mut() because buf is mutable.
In the main function, we will replace the variable buf :
let mut buf = [0u8; MAX_SMALL_PATH];
By:
let buf = BUF.get_ptr_mut(0).ok_or(0)?;
-
BUF.get_ptr_mut(0). Retrieves the first input (we only have one). -
ok_or(0): converts anOptioninto aResult(remember this?).
buf is now of type *mut[u8;MAX_SMALL_PATH] . Whereas before it was of type mut[u8;MAX_SMALL_PATH]. We're not far off. We need to do something to remove this *.
To do this, you need to dereference the raw pointer. Simply add an asterisk on unsafe mode, i.e. instead of :
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut buf)?;
We get:
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut *buf)?;
To dereference a raw pointer, you must be in unsafe mode. For more information, see the Rust Book.
We end up with the following code:
#![no_std]
#![no_main]
use aya_ebpf::{
macros::tracepoint,
programs::TracePointContext,
helpers::bpf_probe_read_user_str_bytes,
};
use aya_log_ebpf::info;
use core::str::from_utf8_unchecked;
use aya_ebpf::maps::PerCpuArray; //library for the map
use aya_ebpf::macros::map; //library for the macro
const LEN_MAX_PATH: usize = 512; //We set a size of 512 to show that we can use more than 512 bytes
const FILENAME_OFFSET: usize = 16;
#[map] //The macro
static BUF: PerCpuArray<[u8; LEN_MAX_PATH]> = PerCpuArray::with_max_entries(1, 0); //Declare the map
#[tracepoint]
pub fn tracepoint_binary(ctx: TracePointContext) -> u32 {
match try_tracepoint_binary(ctx) {
Ok(ret) => ret,
Err(ret) => ret as u32,
}
}
fn try_tracepoint_binary(ctx: TracePointContext) -> Result<u32, i64> {
let buf = BUF.get_ptr_mut(0).ok_or(0)?; //Retrieve the map value
let filename = unsafe {
let filename_src_addr = ctx.read_at::<*const u8>(FILENAME_OFFSET)?;
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut *buf)?; // filled the map
from_utf8_unchecked(filename_bytes)
};
info!(&ctx, "tracepoint sys_enter_execve called. Binary: {}", filename);
Ok(0)
}
#[cfg(not(test))]
#[panic_handler]
fn panic(_info: &core::panic::PanicInfo) -> ! {
loop {}
}
I've put comments where we've made changes. There's not that much to change in the end!
And it works:
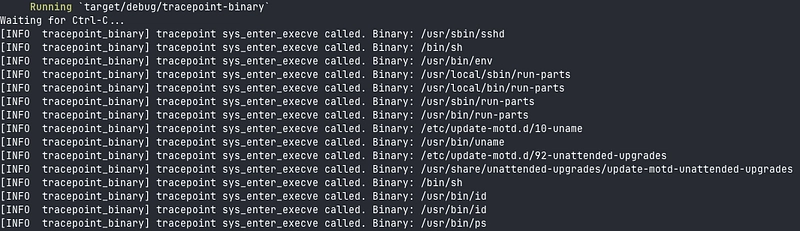
Now that we've seen a practical example of an eBPF map. Let's explain eBPF maps in a little more detail.
eBPF maps: benefits and limitations
Definition
An eBPF map is data that is accessible in both user space and kernel space. It is persistent until the end of the eBPF program, or until the machine is restarted in the event of pinning. Its main uses are :
- go beyond the limits of kernel programs
- communication between user space and kernel space
- communication between eBPF kernel programs
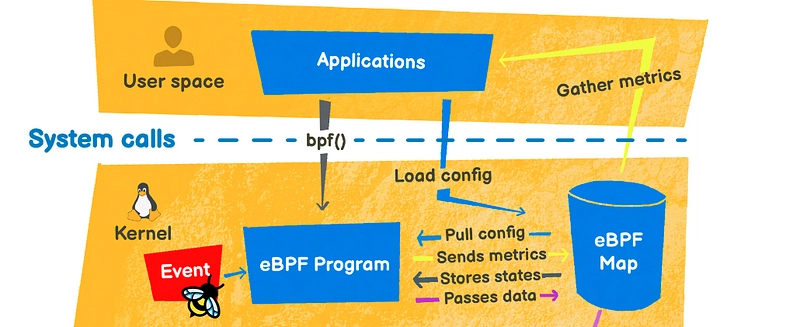
Go beyond 512 bytes
In the previous example, we saw a use for the eBPF map: it allows you to go beyond the eBPF limitation and virtually have a variable stack of more than 512 bytes.
Input
To configure a program, we use, for example, a configuration file, or we put it as an argument to the command. An eBPF program cannot read a file directly. It has to go through an eBPF map. In this way, there is communication from user space to kernel space.
Output
To retrieve data processed in kernel space and make it available in user space via a file, an eBPF map must also be used. In this way, communication takes place in the other direction, from kernel space to user space.
Communication between eBPF programs
As you can imagine, kernel-space eBPF programs have certain limitations. For large-scale projects, however, it is possible to create several eBPF programs and have them communicate with each other via eBPF maps. This is known as tail calls. This will be the subject of the next part of the introduction.
What can you put in these maps?
As we saw when creating our first map, you can put integers and static arrays. But can you put anything else?
What can you replace by <T> ?
It's not magic: these variables cannot be dynamic arrays. Their size must be decided before compilation, as they are available in kernel space. Nor can strings. So that already limits things quite a bit 😃
However, aligned structures can also be used. Example:
#[repr(C)]
struct ProgramState {
timestamp: u64,
duration: u64,
ret: i64,
}
#[map]
static TIME: PerCpuArray<ProgramState> = PerCpuArray::with_max_entries(1, 0);
As memory management in Rust is different for C structures, you must add #[repr(C)] before the structure to tell the Rust compiler to convert it to a C structure.
The different types of eBPF maps
Just as there are different types of eBPF program, there are also different types of eBPF map. All these maps are listed here. The map types have appeared with each Linux kernel release, and there will probably be new ones in future versions. Moreover, Aya does not yet support all these types. At the time of writing, about twenty are available. There's already plenty to play with.

Why are there different types? In fact, I think we need to draw an analogy with databases. There are different types of database, depending on the use case. For example, a redis database has nothing to do with the use case of an SQL database. So each type of map will have its own use cases. The wrong choice of type can lead to performance problems.
A little eBPF map sorting
When you look at the list of eBPF map types, you might feel lost, because there are so many of them. Which one to choose? Difficult to answer without knowing your needs.
Let's list the most common ones:
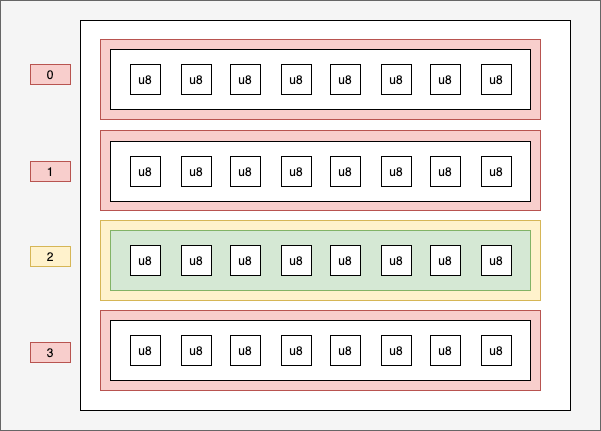
- Array: list structure (fixed, limited size). Accessed and modified via an index.
- Hashmap: dictionary structure (dynamic but limited size). Access and delete via key. An element can be added or updated via key/value.
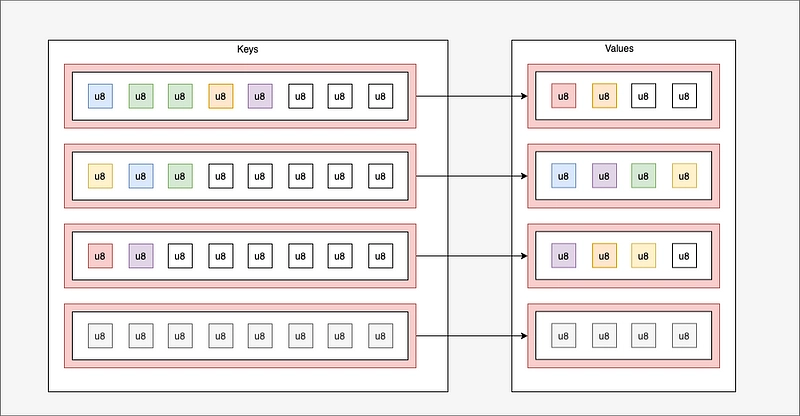
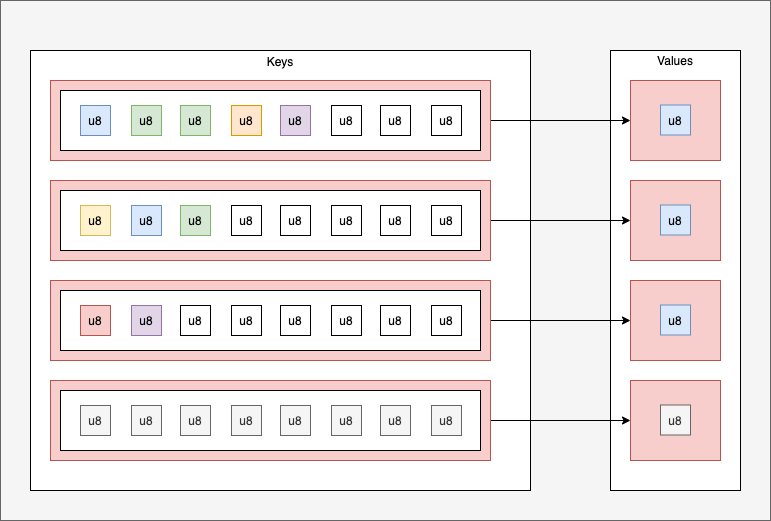
Example of dictionary: max. 4 entries (including one not taken), keys are arrays of 8 entries and values are arrays of 4 values.
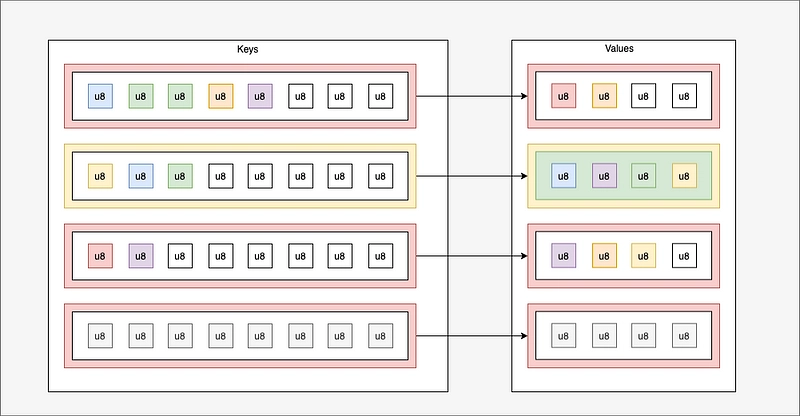
- If I request the key selected in yellow, I get the list in green.
They may suffice, but if several CPUs are trying to modify the same map at the same time, this can cause problems. These maps are more suitable for data that doesn't move very often, such as configuration data. For more dynamic data, we'll opt for these maps instead:
- PerCpuArray : list structure per CPU
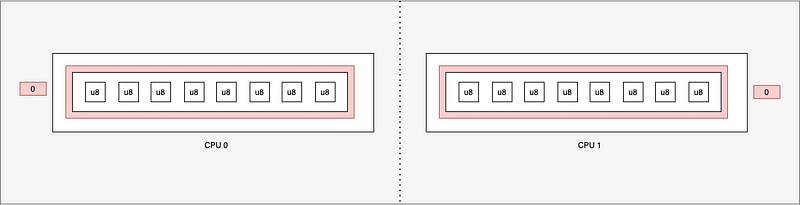
- PerCpuHashmap: dictionary structure per CPU
This creates one structure per CPU. When an eBPF program is started, only one CPU will be running, so it will be on a single structure. If two eBPF programs are started at the same time, one eBPF program will be on the first CPU and the other on the second. We chose this type of map for the buffer at the beginning of the article because it can be subject to joint writes.
Maps with dictionary structures have a limited size. What happens if the maximum size is reached and we try to add a new key to the dictionary? You won't be able to add any more without removing keys manually. These maps solve this problem:
- LruHashMap: Least Recently Used
- LruPerCpuHashMap: the same but per CPU
When the map is full, an algorithm will delete the least recently used key.
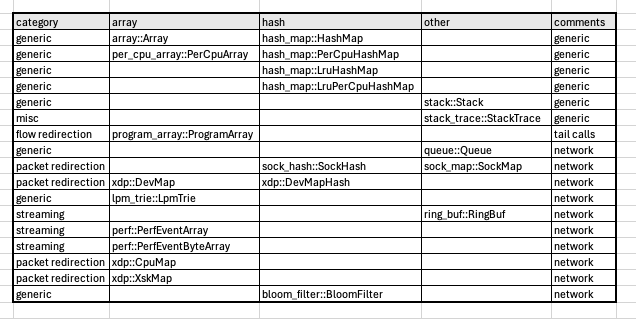
We've already seen 6 types of eBPF map. The others are a little more specialized, notably in networking.
I've tried to sort the different maps available in Aya into a table to give you an idea:
Flag on an exam
As we saw in the previous example, you can define a flag. We set it to zero because that's what the example said. This is the default behavior. These flags may differ according to the type of map.

This can be used, for example, to add security to the map. Thus, the BPF_F_RDONLY flag prevents user-space programs from writing. eBPF programs in kernel space, on the other hand, can do as they please. To use these flags in Rust, there's the aya_ebpf_bindings library. BPF_F_RDONLY has this constant.

Another slice of Rust?
Introduction
Before improving the program, we'll concentrate on Rust slices. They're very useful for eBPF programs. We've already used them in the previous section (without realizing it?).
Fixed-size array reference
As we've already seen, to avoid memory leakage problems for dynamic variables, Rust has the concept of possession. Because of this constraint, we use references to avoid dispossession.
For non-dynamic types such as fixed-size arrays, there's no such problem. Why use references at all? References mean you don't have to duplicate an object. For example, a slice, as its name suggests, allows you to retrieve part of an array, but is also a reference to that array: nothing is taken from memory.
Exercise
Write a function that retrieves the first 3 elements of an array.
Without slice or reference, how to do it?
fn retrieve_3(array: [i32; 5]) -> [i32; 3] {
let sub_array: [i32; 3] = [array[1], array[2], array[3]];
sub_tableau
}
fn main() {
let array = [1, 3, 5, 56, 78];
let sub_tableau = retrieve_3(array);
println!("origin array : {:?}", array);
println!("Sub array : {:?}", sub_array);
}
This function has a number of shortcomings. It will be difficult to reuse...
How do you use a slice?
fn retrieve_slice(len: usize, array: &[i32]) -> &[i32] {
&array[..len]
}
fn main() {
let array = [1, 3, 5, 56, 78];
let slice = retrieve_slice(3, &array);
println!("array original : {:?}", array);
println!("Sub-array (slice) : {:?}", slice);
}
-
&array[..len]is equivalent to&array[0..len].
So with a slice, you don't need to create a second array. To manipulate an array, it's best to use a slice in eBPF.
Example with Aya
Let's take an interesting case for Aya. Let's go back to the previous code:
#[map]
static BUF: PerCpuArray<[u8; LEN_MAX_PATH]> = PerCpuArray::with_max_entries(1, 0);
fn try_tracepoint_binary(ctx: TracePointContext) -> Result<u32, i64> {
let buf = BUF.get_ptr_mut(0).ok_or(0)?;
let filename = unsafe {
let filename_src_addr = ctx.read_at::<*const u8>(FILENAME_OFFSET)?;
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut *buf)?; // Remplissage du contenu de la map
from_utf8_unchecked(filename_bytes)
};
info!(&ctx, "tracepoint sys_enter_execve called. Binary: {}", filename);
Ok(0)
}
I'd like to display the contents of the BUF map. How do I do this? We use the get() method:

To retrieve the content, add :
let buf_content = BUF.get(0).ok_or(0)?;
- I created another name of variable to avoid conflict with
buf. - To retrieve the first elements of this array:
info!(&ctx, "buf_0: {}", buf_content[0]);
info!(&ctx, "buf_1: {}", buf_content[1]);
info!(&ctx, "buf_2: {}", buf_content[2]);
info!(&ctx, "buf_3: {}", buf_content[3]);
But how do you get all the elements at once?
Let's try:
let buf_content = BUF.get(0).ok_or(0)?;
info!(&ctx, "buf_content: {}", buf_content);
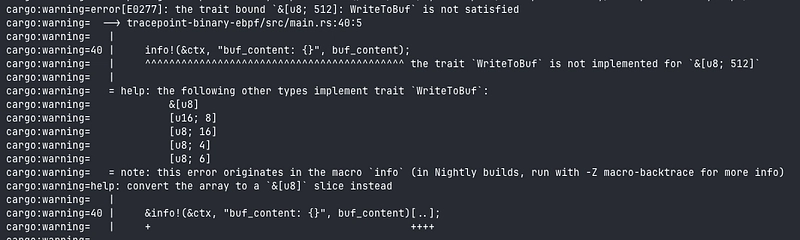
- You have to convert this array into slice:
let buf_content = BUF.get(0).ok_or(0)?;
info!(&ctx, "buf_content: {:x}", &buf_content[..]);
![]()
I prefer this version of code:
let buf_content = &BUF.get(0).ok_or(0)?[..];
info!(&ctx, "buf_new: {:x}", buf_content);
-
{:x}: to convert a slice into hexadecimal - It doesn't work with
{}. To find{:x}I haven't found any documentation yet, so I had to look in the code 😝
If you want to display fewer zeros, you can reduce the slice:
let buf_content = &BUF.get(0).ok_or(0)?[..16];
info!(&ctx, "buf_content: {:x}", buf_content);
What if I want to convert my map into a string?
Do you remember ?

You need to add some code like that:
unsafe {
info!(&ctx, "buf_str: {}", from_utf8_unchecked(buf_content));
}

Instead of using info!, it might be a good idea to use debug! 😜
Let's add a feature
Option to filter commands
At the beginning of this article, we saw a map that is only used in kernel space. We're going to create a configuration map that will be initialized in user space and used in kernel space. We'll filter out the names of binaries we don't want to be displayed. For example, we can imagine that a command like man, which allows you to read the documentation for a command, is not very useful for logging. This will give us a list of commands that we no longer wish to display in the user area.
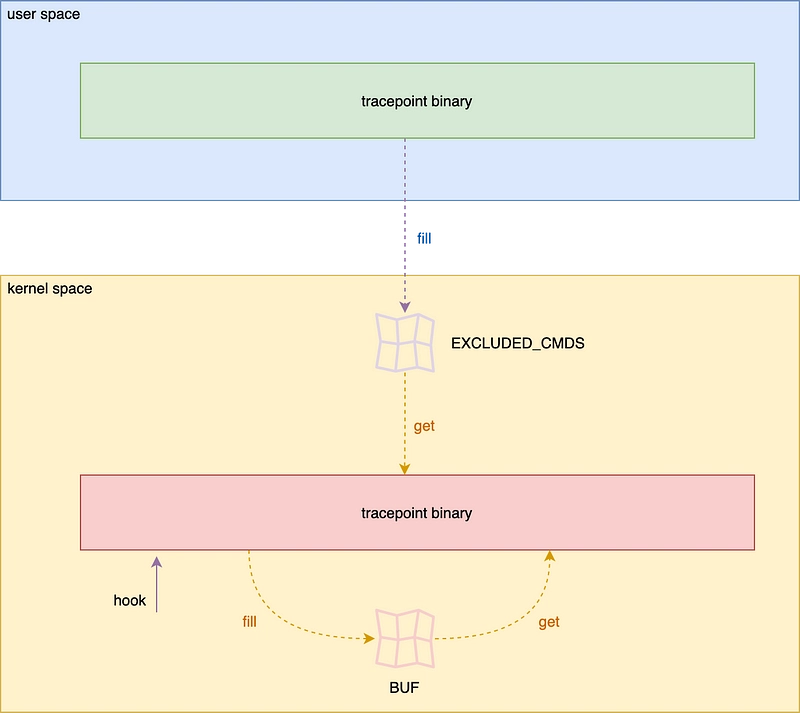
How do we get organized?
As we're starting with the user area, it would be intuitive to create this map in the user area. Unfortunately, this is not yet possible. All maps must be created in kernel space with Aya.
When the user-space program loads the eBPF program, the maps are created. You will then need to retrieve it and fill it with this list of commands.
Once this has been done, all the work will be done at kernel level, checking that the file name is in the list and, if necessary, not logging.
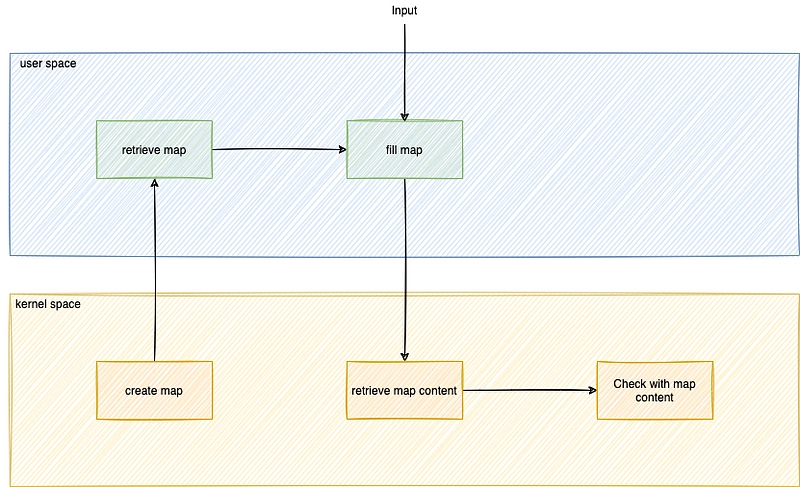
Which type of map?
We've been talking about command lists all along. So we're going to make an Array?
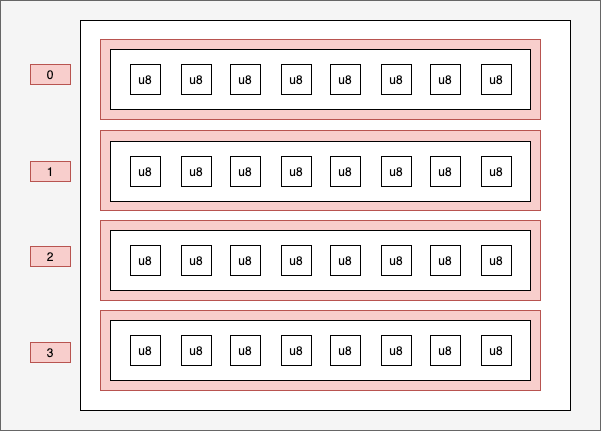
This is obviously possible. However, you'll need to create a function (or find one) to check whether a file name is included. This function will necessarily have a loop to go through each element and check if it's included. The complexity will be in O(n). I haven't talked too much about loops in Rust for a good reason: it's best to avoid them in kernel-side eBPF programs, as the verifier doesn't like them. To find out more about loops, you can read the documentation. Anyway, there are better ways than O(n), you'll see!
So let's create a Hash. But how are we going to structure it? If we were in a “traditional” program, manipulating Strings as a key and any value, we'd have a map like : Map<&str, u8>.
And we'd check whether the command has the key: we'd then move on to O(1) complexity.
However, in eBPF, it's not possible to use Strings in maps. You have to use u8 integer arrays. So the map will be of the form : Map<[u8; 512], u8>.
Its key will be a list of bytes representing the name of the command, and its value will be an integer u8, which will serve only as a witness. All that's left is to choose the type of Hash. I've chosen a generic map: the HashMap, as it will never be modified except at the start of the program.

Schematically, it works like this:
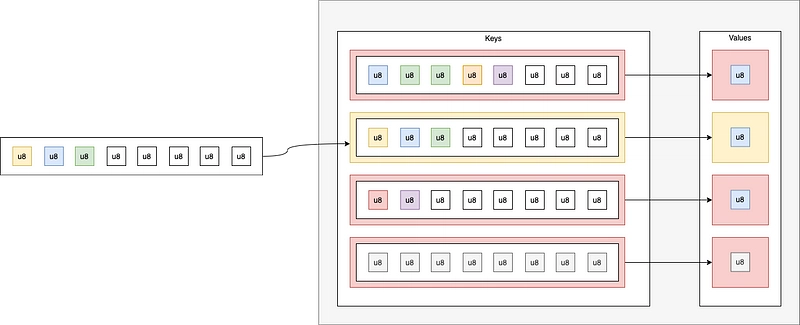
There are certainly more optimal ways, but the aim of this exercise is to show how to transfer a map from user space to kernel space.
Creation of the map
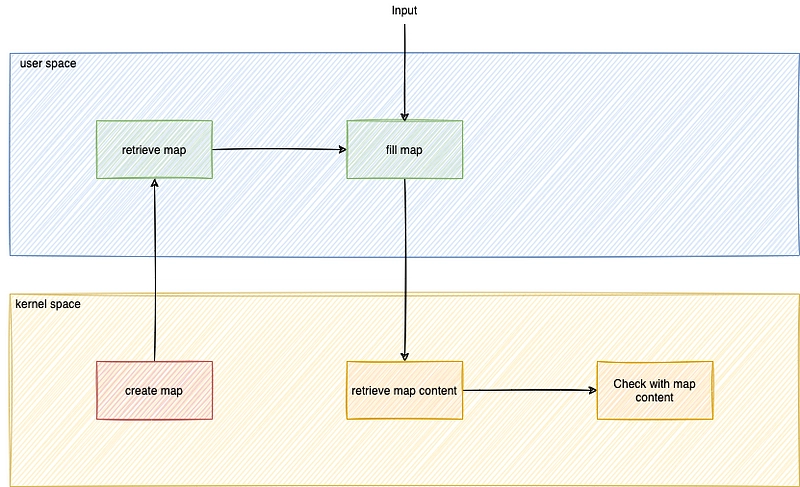
As we've already seen, the map is declared in a very similar way to the previous one. We therefore need to add these lines to the tracepoint-binary-ebpf/src/main.rs file:
#[map]
static EXCLUDED_CMDS: HashMap<[u8; 512], u8> = HashMap::with_max_entries(10, 0);
We limit the Hash to 10 entries, so we can only exclude 10 commands.
Don't forget HashMap library at the beginning of the file:
use aya_ebpf::maps::{PerCpuArray, HashMap};
Input
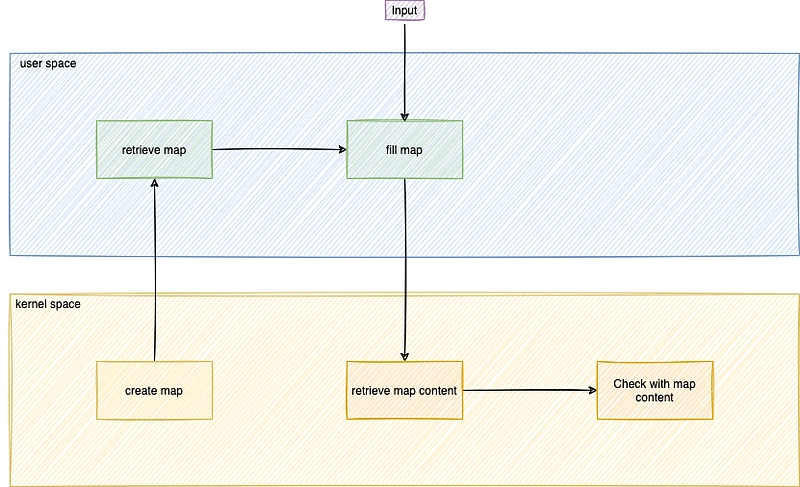
To add values to this map, we're going to do it on the user side. We could imagine that we had a configuration file and that this program would retrieve the various filenames from this configuration file dynamically, but we'll keep it simple: we'll hard-code the whole thing. This is just a demonstration, the aim being to understand the transfer from user space to kernel space.
Once the kernel code is loaded, the eBPF maps will be automatically created. This is when you need to work on the tracepoint-binary/src/main.rs file:
let mut ebpf = aya::Ebpf::load(aya::include_bytes_aligned!(concat!(
env!("OUT_DIR"),
"/tracepoint-binary"
)))?;
[...]
let program: &mut TracePoint = ebpf.program_mut("tracepoint_binary").unwrap().try_into()?;
program.load()?;
program.attach("syscalls", "sys_enter_execve")?;
//It's here where you have to code
We'll add a list of commands that should not be logged. For example:
let exclude_list = ["/usr/bin/ls", "/usr/bin/top"];
Let's simplify: we've retrieved the absolute path of the command
No need to bother with a dictionary for input values.
Retrieve the map
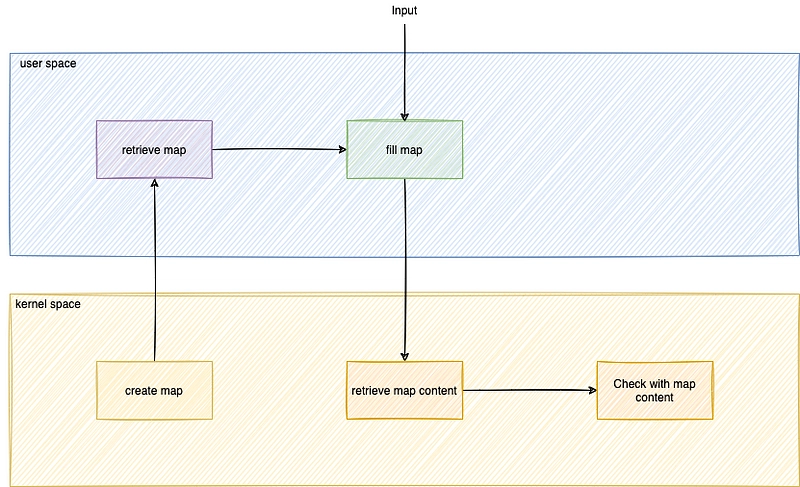
To retrieve the map, look at the user-side documentation:
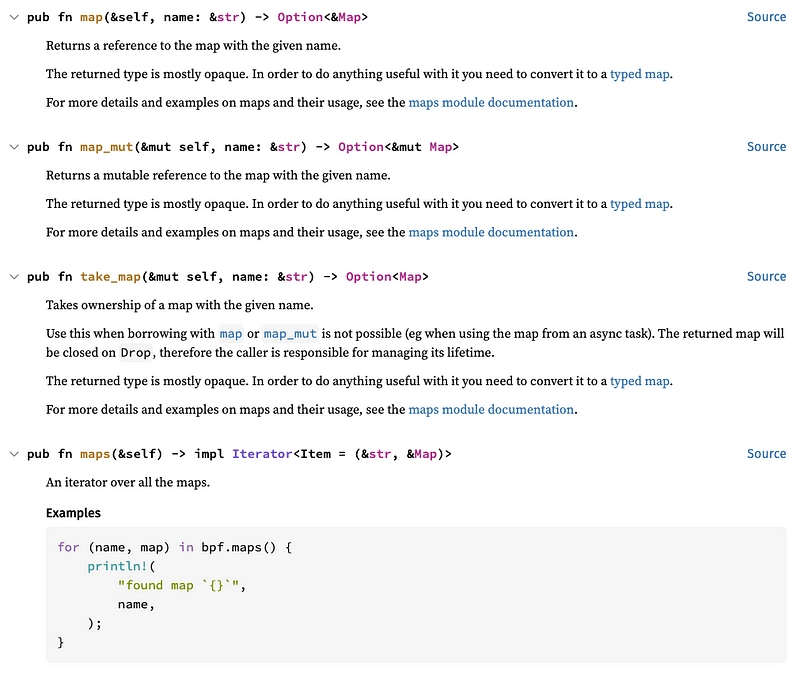
A priori, the map_mut() function should suffice:
let map = ebpf.map_mut("EXCLUDED_CMDS").unwrap();
This is the name of the map defined on the kernel side: EXCLUDED_CMDS.
Remember that since the map_mut() method returns the Option enumeration, and since we're on the user side, we can use the unwrap() method: we'll take advantage of this.
The map variable is then of type &mut Map. In fact, Map is a kind of interface structure. It needs to be converted into a more specific HashMap type.
Let's take a look at the documentation for this:
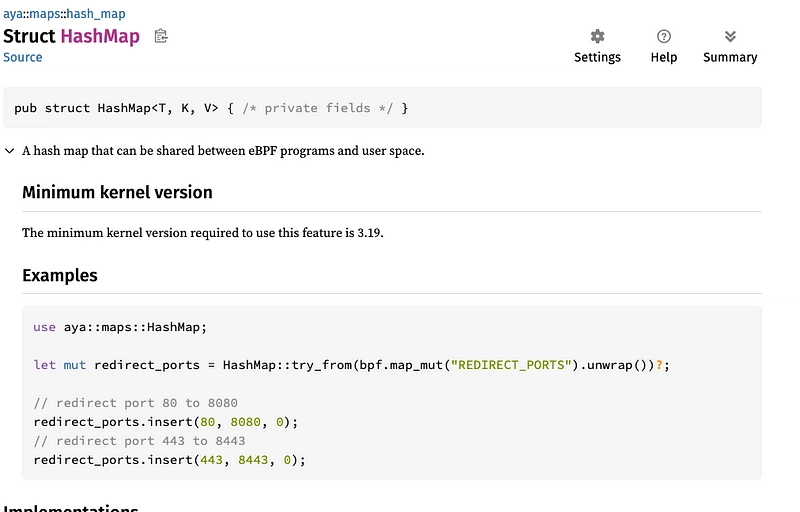
So i'm trying:
let mut excluded_cmds = HashMap::try_from(map)?;
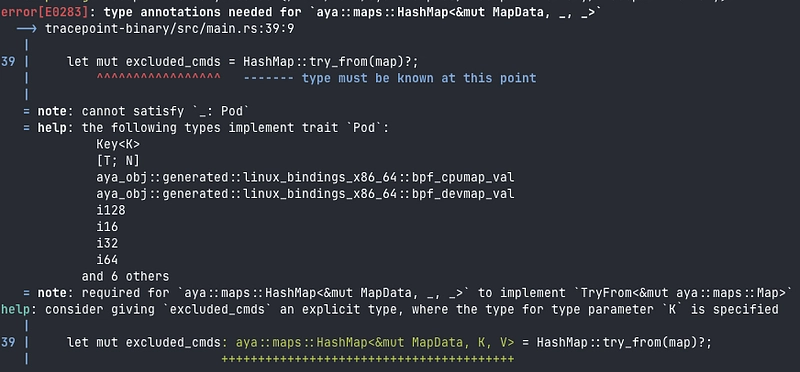
So :
let mut excluded_cmds :HashMap<&mut MapData, [u8; 512], u8> = HashMap::try_from(map)?;
Don't forget to import HashMap et MapData library at the beginning of the file:
use aya::maps::{HashMap, MapData};
Filling the map
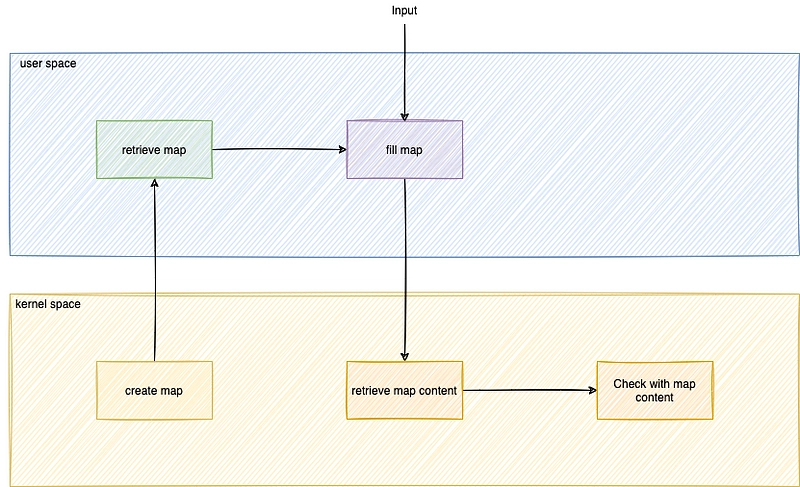
Now we have the right map. Now we need to fill it with shell commands.
First, we need to convert all strings into a fixed byte list, i.e. fill the end with zeros.
![]()
This function is designed to do just that:
fn cmd_to_bytes(cmd: &str) -> [u8; 512] {
let mut cmd_zero = [0u8; 512];
let cmd_bytes = cmd.as_bytes();
let len = cmd_bytes.len();
cmd_zero[..len].copy_from_slice(cmd_bytes);
cmd_zero
}
Let's take a look at each step...
- we create an array of 512 integers (type u8) all equal to 0. This is the function's output variable:
let mut cmd_zero = [0u8; 512]; - We convert commands (
&str) into byte slice (&[8]):let cmd_bytes = cmd.as_bytes();

we take the length of the sliced command:
let len = cmd_bytes.len();-
The last instruction is hard to understand:
-
cmd_zero[..len]: we create a slice of the same length as the command (as this is a prerequisite forcopy_from_slice()) -
cmd_zero[..len].copy_from_slice(cmd_bytes): we inject the sliced command intocmd_zero.
-

Here you can see the benefits of slices 😆
To add to the dictionary, use the insert function:

What is flags used for? The main purpose of flags is to tell the map what to do if the key already exists:
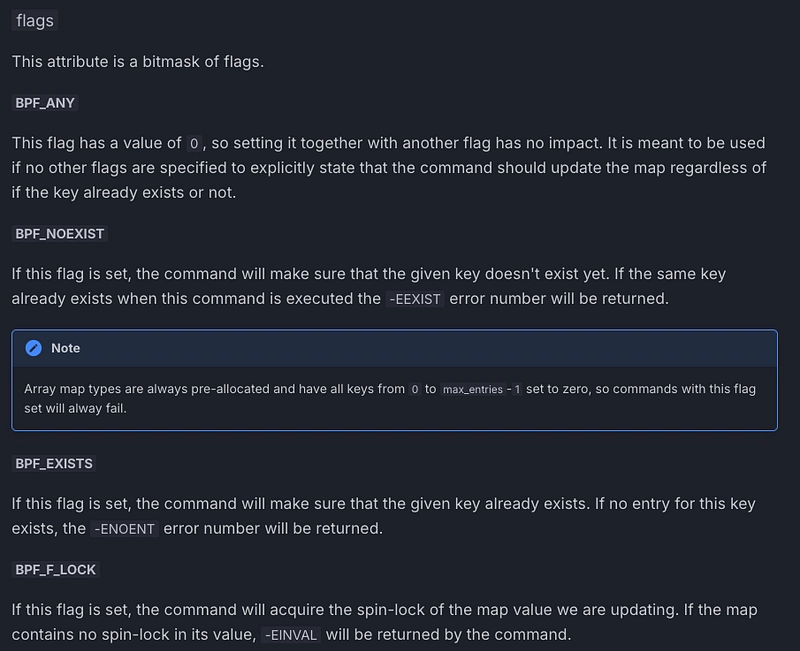
By looping over each command (we have the right here), we obtain:
for cmd in exclude_list.iter() {
let cmd_zero = cmd_to_bytes(cmd);
excluded_cmds.insert(cmd_zero, 1, 0)?;
}
-
cmd_zerorepresents the fixed byte array -
valuehas been replaced by 1, a random number -
flagsis set to zero: default behavior
We've filled in the filename map: the user side is finished.
If you haven't been following along, I'll summarize what's been added:
#[rustfmt::skip]
use log::{debug, warn};
use tokio::signal;
+use aya::maps::{HashMap, MapData};
#[tokio::main]
async fn main() -> anyhow::Result<()> {
@@ -33,6 +34,13 @@ async fn main() -> anyhow::Result<()> {
let program: &mut TracePoint = ebpf.program_mut("tracepoint_binary").unwrap().try_into()?;
program.load()?;
program.attach("syscalls", "sys_enter_execve")?;
+ let exclude_list = ["/usr/bin/ls", "/usr/bin/top"];
+ let map = ebpf.map_mut("EXCLUDED_CMDS").unwrap();
+ let mut excluded_cmds :HashMap<&mut MapData, [u8; 512], u8> = HashMap::try_from(map)?;
+ for cmd in exclude_list.iter() {
+ let cmd_zero = cmd_to_bytes(cmd);
+ excluded_cmds.insert(cmd_zero, 1, 0)?;
+ }
let ctrl_c = signal::ctrl_c();
println!("Waiting for Ctrl-C...");
@@ -41,3 +49,11 @@ async fn main() -> anyhow::Result<()> {
Ok(())
}
+
+fn cmd_to_bytes(cmd: &str) -> [u8; 512] {
+ let mut cmd_zero = [0u8; 512];
+ let cmd_bytes = cmd.as_bytes();
+ let len = cmd_bytes.len();
+ cmd_zero[..len].copy_from_slice(cmd_bytes);
+ cmd_zero
+}
You can test it: it compiles.
Let's test whether the file name is in this map
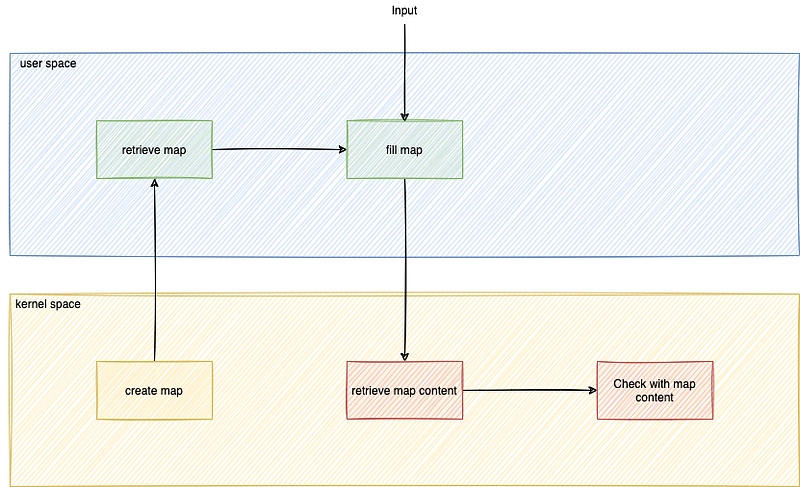
Now that we've filled in the map, we need to modify the kernel-side file: tracepoint-binary-ebpf/src/main.rs.
Let's recall the important parts of the eBPF program:
#[map]
static BUF: PerCpuArray<[u8; 512]> = PerCpuArray::with_max_entries(1, 0);
#[map]
static EXCLUDED_CMDS: HashMap<[u8; 512], u8> = HashMap::with_max_entries(10, 0);
fn try_tracepoint_binary(ctx: TracePointContext) -> Result<u32, i64> {
let buf = BUF.get_ptr_mut(0).ok_or(0)?;
let filename = unsafe {
let filename_src_addr = ctx.read_at::<*const u8>(FILENAME_OFFSET)?;
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut *buf)?;
from_utf8_unchecked(filename_bytes)
};
info!(&ctx, "tracepoint sys_enter_execve called. Binary: {}", filename);
Ok(0)
}
To retrieve the value of a map, we always have :

There's no need to modify it. So the get() method suffices. This method returns the Option enumeration: this is either Some() or None. There's a method for checking this:

Simply add the following code:
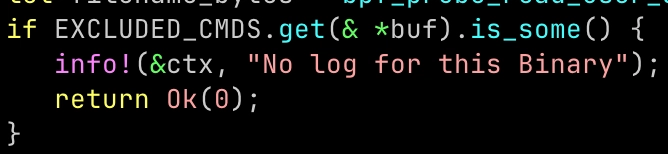
if EXCLUDED_CMDS.get(filename_bytes).is_some() {
info!(&ctx, "No log for this Binary");
return Ok(0);
}
Let's try:
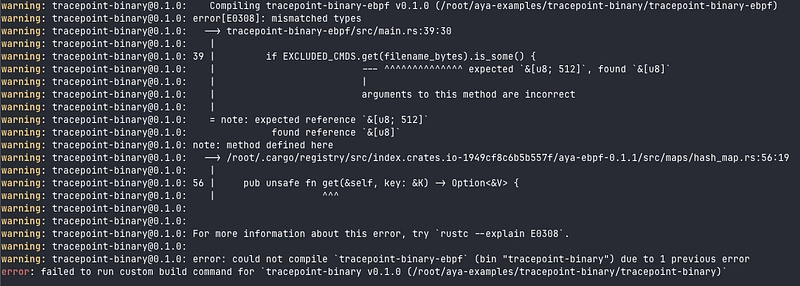
There's a type problem: filename_bytes is a bytes slice (&[u8]) and the get() method expects type <T>, i.e. &[u8; 512] in our case. It would be “enough” to convert filename_bytes to &[u8; 512]. Easy to say 😝
In truth, this is not possible (easily) in eBPF. We need to find another solution. buf is of type *mut[u8;512]. As we saw in the section on slices, it contains the command with lots of zeros.
- Simply dereference the variable by adding
*:*bufis then of type[u8;512]. - And add a reference:
&*bufis then of type&[u8; 512]. This makes :
if EXCLUDED_CMDS.get(&*buf).is_some() {
info!(&ctx, "No log for this Binary");
return Ok(0);
}
The important parts of the program are here:
#[map]
static BUF: PerCpuArray<[u8; 512]> = PerCpuArray::with_max_entries(1, 0);
#[map]
static EXCLUDED_CMDS: HashMap<[u8; 512], u8> = HashMap::with_max_entries(10, 0);
fn try_tracepoint_binary(ctx: TracePointContext) -> Result<u32, i64> {
let buf = BUF.get_ptr_mut(0).ok_or(0)?;
let filename = unsafe {
let filename_src_addr = ctx.read_at::<*const u8>(FILENAME_OFFSET)?;
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut *buf)?;
if EXCLUDED_CMDS.get(& *buf).is_some() {
info!(&ctx, "No log for this Binary");
return Ok(0);
}
from_utf8_unchecked(filename_bytes)
};
info!(&ctx, "tracepoint sys_enter_execve called. Binary: {}", filename);
Ok(0)
}
You can test it! This code works:
- Run the
lscommand :
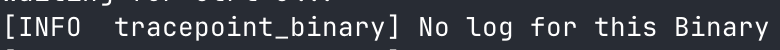
- Run the
topcommand :
![]()
- So for these two commands we go to the
ifcondition:
We created a filter.
Run another command :
![]()
All is for the best in the best of all possible worlds?

Oh no! It doesn't work sometimes...
Let's fix the bug
What's wrong with it?
The key point of the problem is that the map (BUF) originally created is not necessarily “equal” to a command. Let me explain.
At map creation, BUF is a list of 0 :
static BUF: PerCpuArray<[u8; 512]> = PerCpuArray::with_max_entries(1, 0);
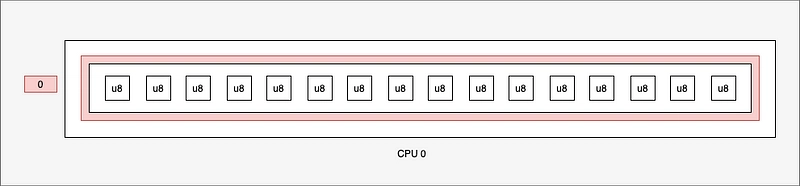
To be precise, a list of 0s per CPU. We'll assume for the sake of argument that there's only one CPU. More CPUs will only mask the problem without solving it.
At the first command run, the BUF map is the command and at the end of the zeros :
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut *buf)?;
It's what we want.
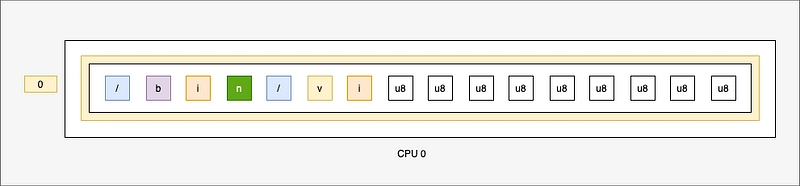
I've replaced the numbers with letters because otherwise it's hard to understand for a human.
But remember that the map is persistent. In other words, the second time the program is run, the BUF map is no longer a list of 0. But :
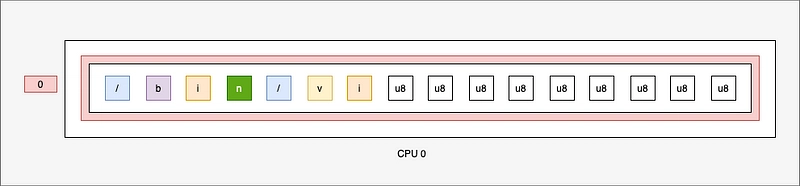
Now let's assume that this command contains a lot of characters:
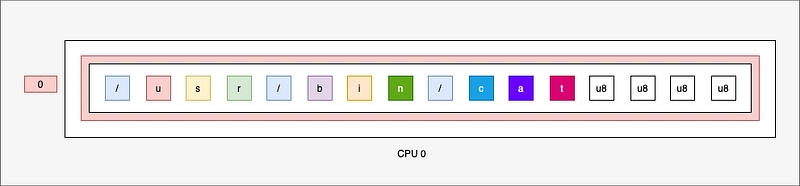
If we run another command with a smaller number of characters, the BUF map will contain :
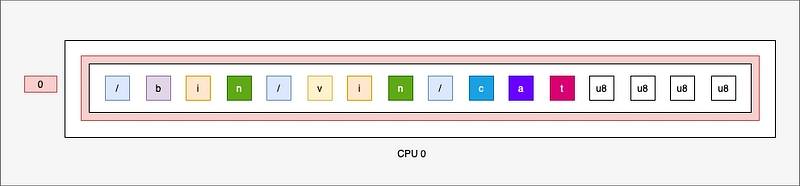
- The command + the end of the previous command + a lot of zeros
So we'll never get back into the condition:
if EXCLUDED_CMDS.get(& *buf).is_some() {
info!(&ctx, "No log for this Binary");
return Ok(0);
}
Reset the map!
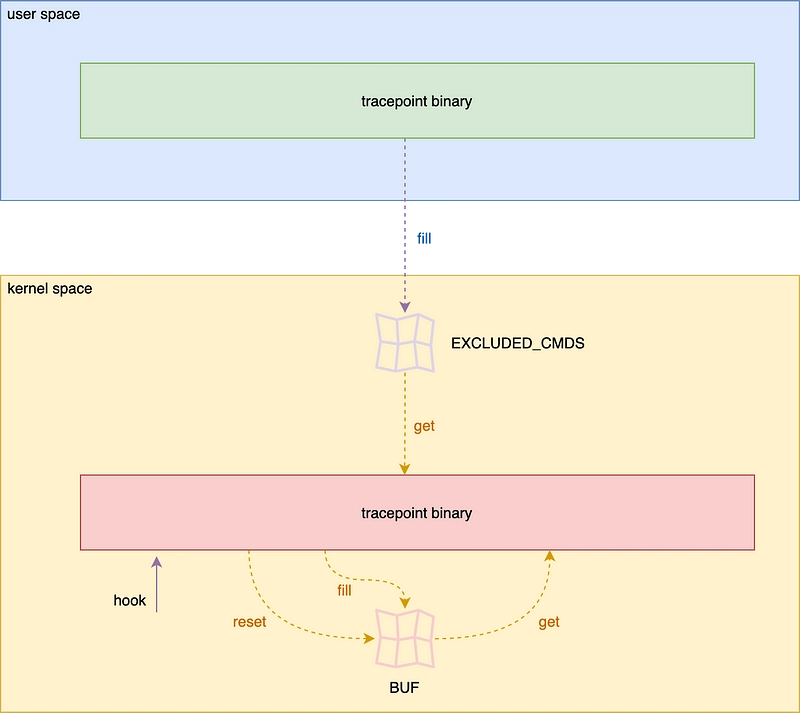
The solution is to reset the buffer map.
To do this, add : *buf = [0u8; 512]; just after the unsafe tag.
The code of the main function will then be :
fn try_tracepoint_binary(ctx: TracePointContext) -> Result<u32, i64> {
let buf = BUF.get_ptr_mut(0).ok_or(0)?;
let filename = unsafe {
*buf = [0u8; 512]; //we reset the buffer to array of zeros
let filename_src_addr = ctx.read_at::<*const u8>(FILENAME_OFFSET)?;
let filename_bytes = bpf_probe_read_user_str_bytes(filename_src_addr, &mut *buf)?;
if EXCLUDED_CMDS.get(&*buf).is_some() {
info!(&ctx, "No log for this Binary");
return Ok(0);
}
from_utf8_unchecked(filename_bytes)
};
info!(&ctx, "tracepoint sys_enter_execve called. Binary: {}", filename);
Ok(0)
}
Bug correction limited to one additional line. You can find the code a little cleaner in github.
For example, I've added a constant to tracepoint-binary-common/src/lib.rs :
pub const MAX_PATH_LEN: usize = 512;
This avoids hard-coding the maximum PATH size in kernel and user space.
That's all for this section. We've seen quite a lot in this section eBPF Map: two different maps with a hash and an array. One is used in user space and kernel space, the other only in kernel space. In the next section, we'll look at a rather special map that allows different kernel eBPF programs to work together.


Top comments (0)