
A WASM benchmark story
At Linkurious, we build Linkurious Enterprise, a Web platform that leverages the power of graphs and graph visualizations to help companies and governments around the globe fight financial crime.
One of the main features of Linkurious Enterprise is a user-friendly graph visualization interface aimed at non-technical users.
In 2015, unhappy with the state of JavaScript graph visualization libraries, we started developing our own: Ogma.
Ogma is a JavaScript library we built that is focused on network visualization, providing excellent rendering and computing performances. You may have seen networks visualized before in JavaScript with other tools like D3.js or Sigma.js, but for us it was very important to enable some specific feature and improve specific performance metrics not available on other libraries, hence the creation of the Ogma visualization library from the ground up.
The problem

Ogma has been designed to work with state-of-the-art algorithms to provide the best performance in the field of network visualizations, from a first-class WebGL rendering engine, to the adoption of WebWorkers to improve the interactivity of the library on long running tasks and finally with top-class graph layout algorithms implementations.
Since the first announcement, WebAssembly promised great performances – comparable to native ones – with very little effort from the developer himself other than developing the source code into a native performance language to get the best results on the Web.
After some time and many more announcements on the WebAssembly side, we decided to give it a try and run a thorough benchmark before jumping on the (performant) WASM bandwagon.
The perfect candidate for this kind of investigation are graph layouts: they are CPU intensive, crunching numbers over and over until a solution converges from it.
The promise of WASM is exactly to solve this kind of problem with better memory and CPU efficiency at a lower level compared to the JavaScript interpreter.
Our investigation
Our investigation focused first on finding a candidate to benchmark a typical graph layout algorithm, which can be easily ported to different languages using similar structures.
The choice landed on the n-body algorithm: this algorithm is often the baseline of many force-directed layout algorithms and the most expensive part in the layout pipeline. Solving this specific part of the pipeline would provide great value at the overall force-directed algorithms Ogma implements.
The benchmark
As Max De Marzi said on his blog last summer in 2019:
There are lies, damned lies, and benchmarks.
Building a fair benchmark is often not possible because it’s hard to reproduce real world scenarios: creating the right environment for a complex system to perform is always incredible hard because it’s easy to control external factors in a laboratory benchmarking, while in the real life many things concur to the final “perceived” performance.
In our case our benchmark will focus on a single, well defined, task: the n-body algorithm.
It is a clear and well-known defined algorithm used to benchmark languages by reputable organizations.
As any fair benchmark comparison, there are some rules we defined for the different languages:
- The code structure should be similar for the different implementations
- No multi-process, multi-thread concurrency allowed.
- No SIMD allowed
- Only stable versions of the compilers. No nightly, beta, alpha, pre-alpha versions allowed.
- Use only the latest versions of the compilers for each source language.
Once defined the rules, it is possible to move to the algorithm implementation. But first, it’s necessary to decide which other languages will be used for the benchmark:
The JS competitors
WASM is a compiled language, even if declared as “human readable” assembly code, it’s not a (mentally) sane choice for us to write plain WASM code. Therefore we ran a survey for the benchmark and we picked the following candidates:
The n-body algorithm has been implemented in the 3 languages above and tested against the JavaScript baseline implementation.
On each implementation, we kept the number of points at 1000 and ran the algorithm with different numbers of iterations. For each run, we measured how long it took to perform the computations.
The setup of the benchmark was the following:
- NodeJS v. 12.9.1
Chrome Version 79.0.3945.130 (Official Build) (64-bit)
clang version 10.0.0 - C language version
emcc 1.39.6 - Emscripten gcc/clang-like replacement + linker
cargo 1.40.0
wasm-pack 0.8.1
AssemblyScript v. 0.9.0
MacOS 10.15.2
Macbook Pro 2017 Retina
Intel Dual Core i5 2,3 GHz, 8GB DDR3 with 256GB SSD
Not top of the class machine for a benchmark, but we’re testing a WASM build which is going to be run in a browser context, which usually does not have access to all the cores and RAM memory anyway.
To put some spice on the benchmark, we produced several versions of each implementation: a version where each Point in the n-body system has a 64 bit numeric coordinate representation, and another version with a 32 bit representation.
Another note to consider is probably the “double” Rust implementation: originally in the benchmark a “raw” Rust “unsafe” implementation was written without using any particular toolchain for WASM. Later on, an additional “safe” Rust implementation was developed to leverage the “wasm-pack” toolchain, which promised easier JS integration and better memory management in WASM.
Crunching the numbers
To crunch the numbers, 2 main environments have been tested: Node.js and a browser environment (Chrome).
Both benchmarks run in a “warm” scenario: the Garbage Collector has not been reset before each benchmark suite. From our experiments running the GC after each suite had no particular effects on the numbers.
The AssemblyScript source was used to build the following artifact:
- The JS baseline implementation
- The AssemblyScript WASM module
- The AssemblyScript asm.js module1
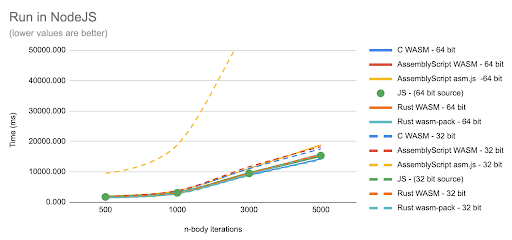
Crunching the numbers in Node.js shows the following scenario:
And then run the same suite in the browser:

The first thing we noted was how the AssemblyScript “asm.js” performs slower than other builds. This chart did not make it clear enough how well or bad other languages were doing compared to the JS implementation, so we created the following charts to clarify:


There is a distinction here between 32 and 64 bit, which may lead to the idea that JS numbers can have both representation: numbers in JS - our baseline - are always at 64 bits, but for the compilers to WASM it may make some difference.
In particular, it makes a huge difference for the AssemblyScript asm.js build at 32 bit. The 32 bits build has a big performance drop compared to the JS baseline, and compared to the 64 bit build.
It is hard to see how the other languages are performing compared to JS, as AssemblyScript is dominating the chart, therefore an extract of the charts was created without AssemblyScript:


The different numeric representation seems to affect other languages too, but with different outcomes: C becomes slower when using 32 bit (float) numbers compared to the 64 bits (double), while Rust becomes consistently faster with 32 bit (f32) numbers than with 64 bit (f64) alternative.
Poisoned implementations?
At this point one, question may come to mind: since all tested WASM builds are quite close to the JS implemented code, would it be possible that the native implementations are slower themselves and the WASM builds just mirror that?
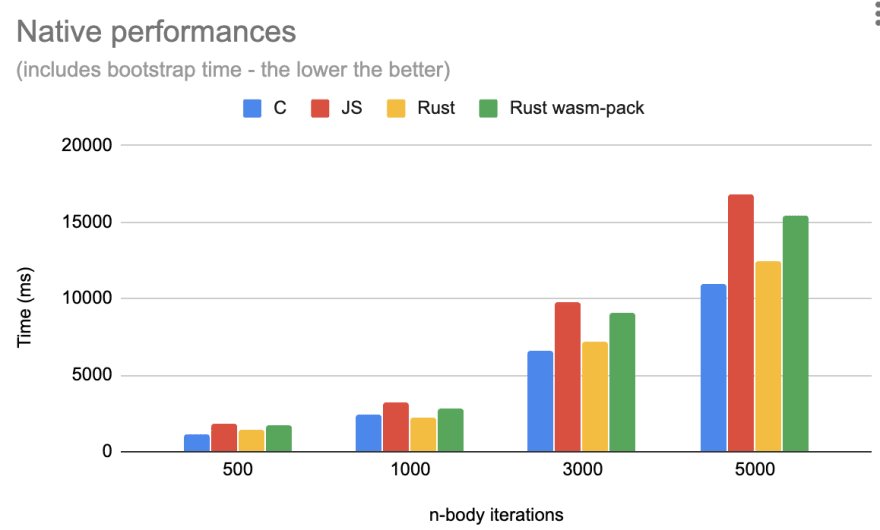
Native versions of the implementations were always faster than its JS counterpart.
What has been observed is that the WASM builds perform slower than their native counterpart, from a 20% up to a 50% performance penalty - performed on a reduced benchmark version with 1000 iterations:



In the measurements above, the native measures are counting also the bootstrap time, while on the WASM measurement that time has been taken out.
Conclusion
The performance gain we measured with Rust (both implementations) is up to 20% compared to the baseline JavaScript implementation - measured on average.
This may sound like a win for Rust, but is actually a very small gain compared to the efforts required.
What did we learn from that? We concluded that writing JavaScript code carefully leads to high performance without the need to jump to new languages.
Learning new languages is always a good thing, but it should be for the right reason: performances are many times the “wrong” reason, as they are more affected by whole design decisions rather than compiler or micro-benchmark optimizations.
As a field experience, we did change language from JavaScript to TypeScript to write our own force-layout algorithm: what we improved was the quality of the codebase, rather than performances, which we measured during the porting and brought a marginal 5% gain, probably due a refactoring of the algorithm - we’ll cover that in a future blog post.
If you’re interested in performances, and JavaScript, you may also find this talk from the DotJS 2019 conference quite interesting, bringing similar results to ours.
Footnotes
1: Interesting to note how the “AssemblyScript asm.js module” was not actually fully asm.js compliant. We tried to add the “use asm” comment on top of the module, but the browser refused the optimization. Later on, we discovered how the binaryen compiler we used does not actually target full asm.js compliance, but rather some sort of efficient JS version of WASM. ↑





Top comments (8)
Why avoid SIMD and concurrency?
cause it's hard :) We would still have to switch language to GLSL and re-implement the n-body simulation. Here we were fishing for easy gains - there are none, unfortunately.
We don't have that steady 20% in the actual WASM results. There could have been a potential gain in slower older browsers, but then they don't support WASM.
To rewrite we would've needed 35-40%, probably. And even then, it would make more sense to go for parallel and take it to a different level
Hello! Great article! Glad you were able to up and running with Wasm to try it out!
One thing I noticed is that you have the sentence: "with very little effort from the developer himself" in the second paragraph. Could you perhaps use a gender neutral pronoun, or remove the pronoun? I think it implies that developers are men and not other genders. I'm sure it was unintentional, no worries at all :)
Also, I wrote a similar benchmark here: medium.com/@torch2424/webassembly-... And got similar results! I saw that you decided to stay with JS, but if you are still looking for performance increases in JS, I think something interesting to try on your end is using closure compiler on your codebase, as I saw some nice improvements from adding that to my rollup config.
Thanks! :)
That is very interesting. To undertake the re-write project, what kind of benchmark benefits were you looking for? A 20% uplift isn't to be knocked if you don't constantly have to rework that part of the code, but I figure you considered the massive overhead of rewriting everything to be just not worth it compared to the ability to forward develop?
Honestly, I got the impression that AssemblyScript was only discredited due to slow asm.js version only? But why couldn't just leave AssemblyScript wasm and compare it with others? AssemblyScript wasm have similar performace to Rust and C btw in this benchmark.
Hi Nice 😄, So
WASMis faster thanJS?This is an interesting article. I really loved the concept.