
Nowadays, AI resources are quite available, which makes it much easier to implement RAG (retrieval-augmented generation).
In order for me to keep writing programs and not to be out of sync with the technology for too long, I'm going to use LangChain to implement a Tarot bot.
I chose LangChain because it has an active ecosystem and supports multi-model design, so it's easy to modify it according to the needs. For example, I'll be using Gemini Pro as my LLM this time, but it's easy to switch to ChatGPT or even the free Ollama.
The whole process is very simple.
- Crawl through the web to retrieve a lot of Tarot knowledge and examples.
- Convert these data into vectors and write them to vector storage.
- Build a Web App that can draw cards and present them.
- Feed the drawn cards to AI for interpretation based on the big data.
The final result will be as follows.
https://rider-waite-tarot.streamlit.app/
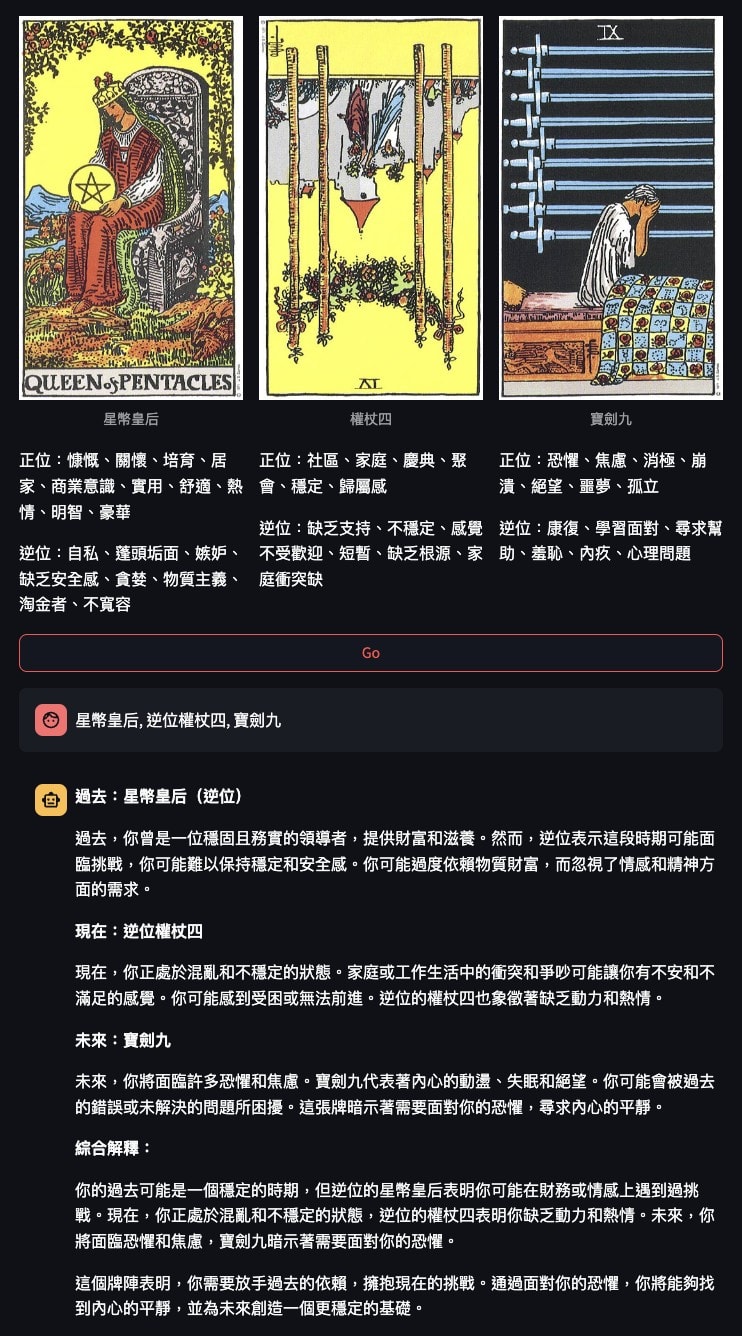
Apologies for the Chinese. I've been studying Tarot lately, so I'm more likely to get the meaning right if it is in Chinese.
This layout has a button to draw cards. When the button is pressed, three cards are turned over, each with an upright meaning and a reversed meaning. Finally Gemini will try to give a full explanation of the meaning of each card in context.
Let's get our hands dirty.
Preconditions
Let's start by installing the packages that will be used.
pip install langchain-google-genai langchain pymongo
Implementing a web crawler
Since web crawlers are not the focus of this article, and web crawlers involve finding targets and parsing web content, let me get directly to the heart of the RAG problem.
How to put the material into vector storage?
First, we make a basic declaration about which store we want to use and what kind of embedding we want to use to convert the text into vectors.
In this example, I've chosen to use Mongo Atlas, so let's get the settings right.
from pymongo import MongoClient
# MONGODB_ATLAS_CLUSTER_URI will contain credentials, please modify it accordingly.
client = MongoClient(MONGODB_ATLAS_CLUSTER_URI)
DB_NAME = "langchain_db"
COLLECTION_NAME = "test"
ATLAS_VECTOR_SEARCH_INDEX_NAME = "index_name"
MONGODB_COLLECTION = client[DB_NAME][COLLECTION_NAME]
Next is Gemini's own embedding.
import os
from langchain_google_genai import GoogleGenerativeAIEmbeddings
# # GEMINI_PRO_API_TOKEN is a credential, please modify it accordingly.
os.environ["GOOGLE_API_KEY"] = GEMINI_PRO_API_TOKEN
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
Before writing to storage, the data needs to be pre-processed. Assuming all the data is in JSON format, we need to split the JSON into smaller chunks to make it easier to use.
from langchain_text_splitters import RecursiveJsonSplitter
splitter = RecursiveJsonSplitter(max_chunk_size=300)
# json_data is the data source in JSON format
json_chunks = splitter.split_json(json_data=json_data)
# docs will be stored
docs = splitter.create_documents(texts=[json_data])
Once everything is ready, it's just time to convert the data into vectors and write them to MongoDB.
from langchain_community.vectorstores import MongoDBAtlasVectorSearch
# insert the documents in MongoDB Atlas with their embedding
vector_orig = MongoDBAtlasVectorSearch.from_documents(
documents=docs,
embedding=embeddings,
collection=MONGODB_COLLECTION,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)
Depending on the state of the crawler and the results, this phase can take a lot of time, both for retrieving data and for writing to storage.
Web App implementation
It's not difficult to build a Web App quickly, as I've introduced in my previous article about Streamlit.
Therefore, I will only talk about two key points this time.
There are many spreads in Tarot, each spread has different layouts and corresponding Gemini prompts, so we need to prepare a detailed explanation of the spreads for Gemini to know how to interpret them.
if spread_type == 'Time Flow':
spread = init_time_flow_spread()
sys_prompt = '''
This is a Time Flow Tarot spread where three cards are drawn to represent the past, present and future.
Based on the user's question, the meaning of the three cards drawn by the user, and the following {context}, a reasonable explanation is given.
'''
The tarot cards are drawn in upright and reversed positions, so we can't just use the file paths in st.image, we need to read out the files and process them and use numpy.ndarray as the parameter.
def open_image(fp):
from PIL import Image
import numpy as np
image = Image.open(fp)
image_array = np.array(image)
flipped_image = image.transpose(Image.ROTATE_180)
flipped_image_array = np.array(flipped_image)
return image_array, flipped_image_array
Integrate with Gemini Pro
For Gemini to learn about Tarot, the results of the previous crawler are required, so the first step is to make Gemini able to retrieve the vectors we have stored, i.e. the R of the RAG.
We'll use the mentioned embedding and the MongoDB settings.
vector_search = MongoDBAtlasVectorSearch.from_connection_string(
MONGODB_ATLAS_CLUSTER_URI,
DB_NAME + "." + COLLECTION_NAME,
embeddings,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
)
retriever = vector_search.as_retriever()
Next we need to build the LLM using Gemini Pro.
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(model="gemini-pro", convert_system_message_to_human=True)
Finally, the whole chain is connected.
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain_core.prompts import ChatPromptTemplate
# sys_promopt is based on Tarot's Spreads.
prompt = ChatPromptTemplate.from_messages([
('system', sys_prompt),
('user', 'Question: {input}'),
])
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
With the whole chain, we can ask Gemini to start his show.
# input_text is the three cards drawn by the user.
response = retrieval_chain.invoke({
'input': input_text,
'context': []
})
Conclusion
This is the simplest example of a RAG implementation, applying all RAG elements, and each piece can actually be modified as needed. The core of domain knowledge is the crawlers, and this application just uses the information to answer questions.
At the moment, I don't intend Gemini to act like a real soothsayer with the user. For me, Tarot is a mechanism for dialog with the heart, not for seeking magic.
The whole project is on Github.
https://github.com/wirelessr/streamlit-tarot/blob/master/streamlit_app.py
Although this application has both UI and AI integration, the total number of code lines is only 150. I have to say, both Streamlit and LangChain are really great at packaging complex implementations in abstract and sophisticated interfaces, so that users can easily write functionality instead of dealing with miscellaneous things.
Here are some of the LangChain materials I have references to.
- gemini-pro: https://python.langchain.com/docs/integrations/chat/google_generative_ai
- gemini-embedding: https://python.langchain.com/docs/integrations/text_embedding/google_generative_ai
- mongo-atlas-vector: https://python.langchain.com/docs/integrations/vectorstores/mongodb_atlas
- json-splitter: https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_json_splitter

Top comments (0)