You can claim your software to be a deployable one, when you are confident that all your user flows are working as expected!
Production-Ready software development is highly dependent on software testing!!
Automation is a must have!
With the rate a software grows, and the complications the domain enfolds, having myriads of test cases to be manually validated is nothing but next to impossible! Well this needs insane level of concentration and patience! Let me elaborate...
These repetitive tasks, on a longer run will make you loose interest and hence concentration and hence, pave way for mis-outs! and boom!! Your software testing results are not reliable... Something that none of us will want!
Even if you manage to do these manually with concentration 😇, the time you need to get it fully tested will be huge! The worst part is the feedback time! Say you start with your manual test suits... After 3 days you find a bug, and once that's fixed you start from Day 1! Imagine you adopting this testing technique after large scale refactoring... 😤
If you want to keep your pace high on enhancing you software capabilities, you need to save the time spent on manual testing! Well, all you need is 'automation'
By automating your repetitive tests and plugging them in your CI/CD pipeline, you no longer have to mindlessly follow click protocols in order to check if your software still works correctly!! All you need is wait for few minutes to ensure your new change didn’t create any bug!
Despite your love towards test automation, manual testing of some sorts is still a good idea! For example when usability is tested... when Exploratory tests are done! These cases are best owned by Manual tester!!
Defining the layers
Alright, you are ready to automate your tests... You convert all your manual test cases into automated user journey tests, very similar to how you login and click a button as a person, you have made scripts to automate the process...
Only to find out that these test suits are taking more time (Lesser than manual of-course) and consumes more system resources and hence more cost! 😒
Wait wait... You are doing automation but not in the right way!!
User journey tests are expected to be time consuming and costly. There are different types of tests that vary with respect to cost and time. To achieve automation, you need to test your software at different layers using these different types of tests.
You need to keep two things in mind.
Different layers consists of testing your application in different granularity.
The bottom most layer checks every single logic!
Whilst the top most checks for user clicksThe higher you go up the Pyramid, the lesser the number of tests it is.
When the bottom most layer has 1000X number of tests
the top most can have 10X number of tests
As a general practice, it is recommended to follow the below way of adding automation tests. Starting with a hefty number of unit tests to a fewer user journey tests, this Pyramid shaped test plan blesses your software a long and bug-free lifetime! 🥳
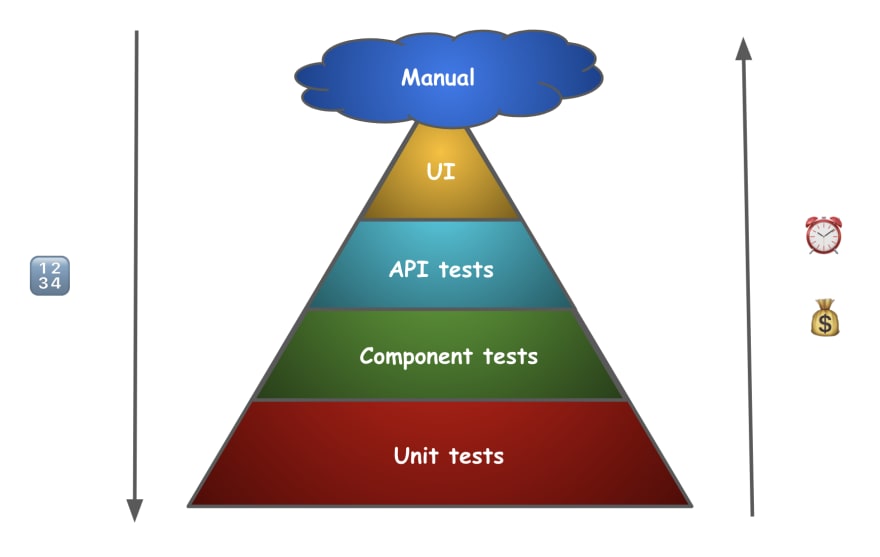
Let's see them one by one!
Unit Tests Layer
As the name suggests, all the tests testing every single unit resides here! The layer where largest number of tests is captured.
Unit tests needs to be fast to execute and consume less resources, in other words any external dependency to the unit under test can be mocked!
These tests should not be linked with the logic / implementation. They should look like a contract of how the unit tested is expected to work.
The most granular level of testing is done in this layer. Hence the fastest and accurate feedback is guaranteed by the tests captured over here.
Arrange Act Assert is a famous and easy-to-adapt way of writing unit tests.
- Set up the test data and mock dependencies.
- Invoke the method you are testing.
- Verify what is expected is same as the actual result returned.
For example, You are writing unit test for your controller.
Mock the application service class, stub the method you will be invoking to return the expected results.
Invoke your controller method
Verify if the returned result after applying the controller logic is the one you expected!
Do the same for all the cases or flows possible in that controller method. This results all the flows of the controller method to be fully tested in automated way.
So by doing this for all the units, they are thoroughly tested, we are all good! We can call the software to be fully tested in an automated fashion! Hurray!!
Well, what happens if the expected result you mocked to be returned from the application service layer to the controller changes?
All unit tests will still be green! But, you software will NOT WORK as expected!!
This doesn't indicate a problem or miss from your unit tests, Unit tests are scoped to test that unit's behaviour...
this is a problem at a wider picture, and this gets us to the need for the next layer...
Component Tests Layer
These can also be termed as Intra service testing. Here the integration between the individual units developed is tested.
This layer will hold comparatively less number of tests than Unit test layer.
Integration tests are written by using the actual units of the service under test. Say you are writing component tests for service A, all the units like Controller, validator, service repository, etc of that SERVICE-A will be the actual units - no mocking of your code!
Hence any contract breaks among the units of SERVICE-A will be got in this layer.
All possible test cases that covers the contracts between different units of the service under test is added here.
In this layer, other resources are mocked.
Say you are using a Postgres database engine. We can have one dedicated for component tests but it comes with it's own cost! Rather we can use in-memory databases offered by frameworks to save this cost for you. By this you end up mocking your database engine, but still the repository code you wrote is not mocked.
In the micro-service ecosystem, service to service interaction is a very common one! Say your SERVICE-A is calling SERVICE-B, and is dependent on the response for deriving it's end response, you need SERVICE-B to give a response to test SERVICE-A behaviour. In these cases, running actual SERVICE-B instance is costlier, you can either build a test double of SERVICE-B or mock it. Here you get to save the cost as well the actual time taken by SERVICE-B.
Hence costly or time consuming resources are mocked and the service under test is tested thoroughly. Thus this layer comes with little more time and cost. Any failures in this layer indicates contracts between your units needs to be checked!
So, using in-memory is cost friendly, but you are using a different data engine, postgres and in-memory postgres are not identical! what if some constraints work by different configs in the in-memory one?
What happens when the response your mocked from SERVICE-B changes?
As a baseline, the contracts between external resources needs to be validated! This paves way for the next layer...
API tests layer
You guessed it right!
The integration between services or external sources is tested in this layer. Here there is no mocking!
All the actual resources are used, and hence these tests ensure E2E working of an API.
SERVICE-A hits the actual SERVICE-B and hence the test cases should cover the contract between these two services.
The contract can be tested in another way too, by ensuring the request and response schema of the provider service is unchanged! or is same as the one expected by the consumer service. There are number of tools to help you write contract tests like PACT, SwaggerBuckle, etc... You need to ensure these contracts are maintained by both the Provider and Consumer service, else all lines of code is just vain!
But if you are interested to ensure the key data values of the other resource or service are working, then hitting the actual instance makes sense. But remember this comes with the cost. So all the tests in this layer should be intended to cover the uncovered interaction between resources.
Both the API and component tests can be written in Given When Then - BDD quote.
The number of tests should be very minimal, these are expected to take more time and consume more resources. Usually preferred to be ran in a test environment.
TidBit: Ensure you are not bloating the database with your test data.
While adding tests make sure you delete the record you created! Else, on a long run your API tests will become Performance tests! For example, Your GET endpoint might be intended to serve some 5K records, but as you kept on adding records you might end up fetching 25K records too... resulting in endpoint test failure / timeout, giving false alarm on the endpoint functionality.
UI tests
Most of the softwares will have UI support. The actual user journey is replicated and tested.
The E2E user flow is tested in this layer. The actual user clicks, navigation to pages and interactions with the system are verified.
You need not worry about backend logic here, testing the user behaviour or acceptance testing is done here. Your UI components interactions are tested.
There are tools available in the ecosystem, that you would be interested to plug-in with your pipeline. For example Selenium, Test-cafe, Cypress, etc...
You can write and run test cases using these tools in the pipeline in browser headless mode.
While developing or debugging you can turn off the headless mode, and see your scripts doing all these user clicks and navigations for you! You might feel like some guest is accessing your laptop 😅
These tools can be configured to open your application in different browsers, in different devices with different screens and run your test suit of user navigation.
They either take screenshots and compare with the previously take screenshot and let you know the difference if any or just mimic the user journey and fail if some expected behaviour couldn’t be accomplished.
For example,
Say clicking a button is expected to open a widget but this is broken... By using these tools either
the new or actual screenshoot will not have this widget, the tool compares it with the previous or expected screenshot and fails the test along with the screenshot missing widget.
Or, the test will fail claiming it couldn’t find the widget in the screen, very similar to how an user would mark the test case as failed!
This is the costliest and the most time consuming layer owing to the imitation that needs to be done. The user journey cases that could not be captured by tests up-till API test can be written here.
Manual ones!
As discussed in the beginning, manual testing is not completely replaced. For example, You need manual testing to accomplish exploratory testing! You set your mind to break the system with random clicks and weird inputs... these sort of testing can not be automated.
The good news is any short falls or bugs identified by these need not be remembered to do again for the next release.
You can see the root cause for the bug you found using manual testing and when you fix it, you can ensure there is test case for that fix in one of the layers! Hence your memory is saved! 😛
Wrapping up!
Alrighty!!
Those were the broad layers of test cases you can fit your software test cases into!
Ensuring your software abides the test pyramid takes some time and effort! But it will pay you back in the longer run and trust me, you will get a more peaceful life!! 😁
Happy learning!

Top comments (0)