
Written by Guido Lena Cota
A glimpse into our Search Assessment offering for Amazon OpenSearch and Elasticsearch
Building and managing a production-grade Amazon OpenSearch cluster takes work. Striking the right balance between relevance, performance, scalability, and costs requires expertise and experience. If you have been following us for some time, you know kreuzwerker offers both.
This blog post draws inspiration from a real project to showcase how our Search Assessment offering helped one of our customers validate and improve their Amazon OpenSearch solution for big data analytics. Let me give a brief overview of our offering before delving into the technical part.
Our assessments are a three-phase process built around a workshop facilitated by two kreuzwerker search consultants (colorful diagram below). The goal is to address a prioritized list of pain points provided by the customer and deliver an actionable remediation plan within a week.
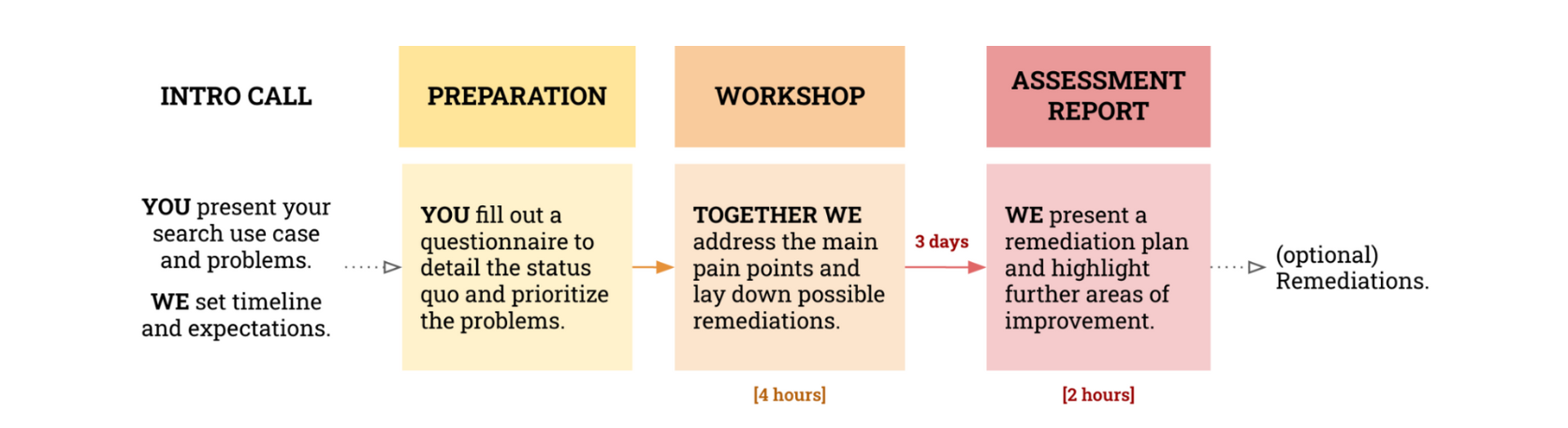
But talk is cheap. Let me tell you how we were able to cut over 60% of Amazon OpenSearch monthly costs for one of our customers.
It always starts with an “It’s too expensive”
The customer is a global Digital Marketing leader. At the kick-off meeting, the team described the setup of their Amazon OpenSearch cluster, crunching 150 million new documents a day to populate marketing campaign KPI dashboards in near real-time. After several attempts to fine-tune the cluster for stability and performance, they resorted to meeting their SLAs by throwing hardware at it, which inevitably took its toll.
Our task as Amazon OpenSearch experts was to validate their current setup and discover opportunities to reduce costs. We ended up doing much more than that, but let’s focus on the financial aspect.
Understanding the problem: Numbers that matter
Amazon OpenSearch charges you for the resources you use: the number of nodes and their hardware profile. Therefore, the first step to help our customer achieve cost efficiency was to review the cluster architecture and identify unnecessary resource utilization.
As illustrated in the diagram below, the cluster had three dedicated master nodes and 12 hot data nodes of type r5.4xlarge.search (16 vCPU, 128GiB memory, and 1TB EBS volume). Daily data were directly ingested by Spring Boot microservices running on the customer’s private cloud and regularly aggregated by custom Spark jobs deployed on the same environment.
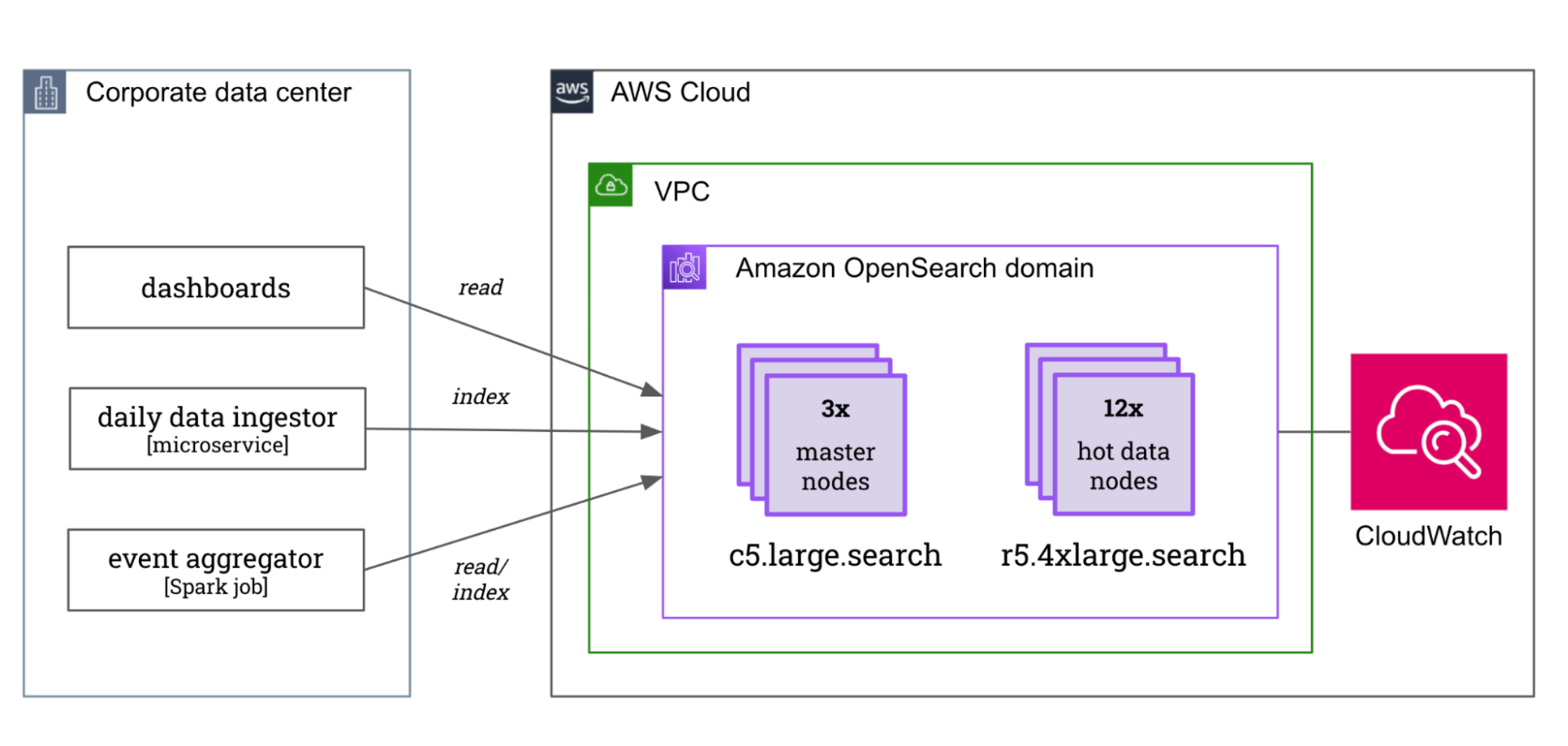
Remember the use case was big data analytics, which means high indexing throughput, memory-bound searches due to the large dataset, and high storage demands. Every minute the cluster ingested 100K documents with time-stamped structured data on clicks, impressions, and conversion rates. To stay lean on disk space, a custom script rolled up documents regularly and moved them into another index, while another script deleted data older than five years.
On the performance side, the cluster was keeping up well with the ingestion workload with an average indexing latency of just 0.04ms (0.3ms max) and empty rejected request queues. The search and analytics latency was also acceptable with an average of 2.04ms for roughly 5K requests per minute. So performance was ok, but efficiency?
Not ok. The production cluster was clearly overprovisioned with a significant amount of unused disk capacity (75%), stable low CPU usage (3%), and hardly half of the heap used. This information doesn’t translate directly into action items. For example, you cannot just recommend reserving 75% less disk space or choosing an instance type with - say - half the number of CPUs. A new capacity planning was in order.
We also recognized that there was a big potential for improvement in the data allocation strategy: indices were partitioned into too many tiny shards with a median of 12 primary shards of only half a GB in size. While higher shard numbers can boost the indexing throughput of active indices by leveraging parallel ingestion across multiple nodes, it can negatively impact read-only indices. Amazon OpenSearch requires one vCPU per shard to process search requests, and each shard adds to memory and disk overhead. Therefore, a more frugal sharding strategy could substantially reduce the resources needed by the cluster.
Estimate, optimize, verify, repeat
Capacity planning of an Amazon OpenSearch cluster is an iterative process based on educated estimates, empirical validations, and adjustments. In the scope of our Search Assessment service, we create the first estimates and share best practices on how to validate them. Let’s get back to our story.
We always start with the storage requirements. Here’s a handy formula:
index_storage = GB_ingested_daily * retention_days * (number_of_replicas + 1) * 1.45,
where the constant factor 1.45 is recommended by AWS to account for the disk space reserved by Amazon OpenSearch and indexing overhead. Based on these calculations and factoring in growth, we determined that the cluster required a minimum of 3 TB in total, while 12 TB were currently allocated. We maintained this number as a benchmark for capacity planning purposes, despite knowing we could reduce it further - for example, by fine-tuning the index mappings or introducing warm data tiers.
Once we estimated the minimum storage requirement for each index, we could move on and answer the immortal question “How many primary shards?” For an analytics use case, best practices say shard sizes ranging from 10 GB to 30 GB are optimal with active indices on the lower end to maximize indexing throughput and read-only indices on the higher end to limit overhead. To accomplish this, we defined Index State Management (ISM) policies that automatically rotate and optimize indices based on retention requirements and usage patterns. Let’s consider, for example, clicks data. Raw clicks data were ingested into the cluster daily and retained for four days before being rolled up and stored into another index. The ISM policy we designed (1) ingested new data into a read/write hot index (e.g., clicks_day_2023-04-29) with one primary shard and two replicas; then (2) moved data older than a day into a read-only index (e.g., clicks_day_2023-04-28) with more replicas to increase query throughput; finally (3) deleted any index older than three days. This and another sample ISM policy are illustrated below.
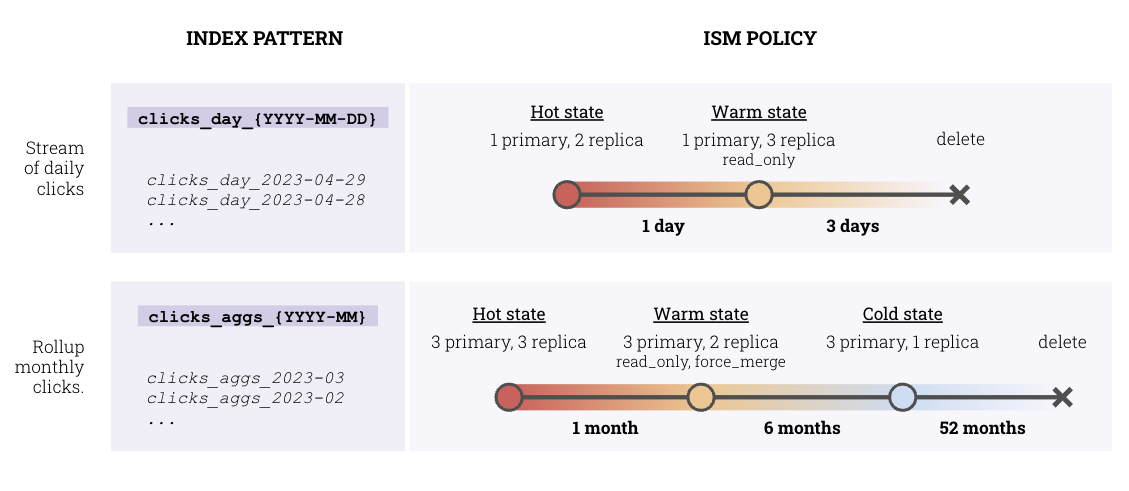
The new indexing design could reduce the number of active shards in the cluster from over 140 to 33, reducing the vCPU requirements as well. With the lowered requirements for storage, compute, and memory, we could outline a plan to explore less expensive cluster configurations iteratively:
- Apply the new indexing strategy to reduce the cluster’s resource requirements.
- Decrease the cluster size, removing three hot nodes. Potential cost saving: 25%.
-
Run benchmarking experiments to evaluate the performance of the following cluster configurations with two smaller instance types:
a. Nine data nodes of type i3.2xlarge.search, more optimised for indexing throughput. Potential cost saving: ~50%.
b. Nine data nodes of type r5.2xlarge.search, more optimised for search performance. Potential cost saving: ~62%. (Note: the r6g instance family was not released yet, or r6g.2xlarge.search nodes would have resulted in 66% cost savings).
Apply the best-performing configuration between 3a and 3b.
To further decrease costs, we recommended reserving four data nodes and the three master nodes for one year with no upfront payment, leading to an additional potential saving of 15%. We also suggested introducing a warm data tier for the infrequently accessed data, accounting for almost half of the total data. Our calculations showed that replacing three hot data nodes with one ultrawarm1.medium.search, could have resulted in a monthly savings of $1,000.
It’s not all about money
The assessment report we provided to our customer not only focused on their main concern of cost savings but also uncovered other improvement opportunities. We proposed ideas for optimizing the ingestion strategy, brainstorming more efficient processes for scheduling and executing rollups. We identified quick wins to enhance data and operational security. We shared best practices for index mappings and configurations (data types, refresh intervals) to lower compute and disk requirements. Finally, we provided a Terraform template to simplify cluster operation and revamped the benchmarking runbook to make it more effective.
Search Assessment is just the beginning
This Search Assessment concluded with a final meeting in which we walked our customer through the proposed remediation plan to cut their monthly Amazon OpenSearch costs. This meeting aimed to ensure that the plan met their expectations (it did) and was understood well enough for them to implement. Of course, kreuzwerker was also ready to provide support during the remediation phase when needed - that’s the real fun part!
Here is where this story ends and many others start. I hope this blog post was informative, but I totally understand that it could be too basic or overwhelming for some readers, depending on their experience with OpenSearch or Elasticsearch. That’s ok. So, then let’s talk about your challenges!! Are you facing similar issues? Are you facing different challenges? Come talk to us , we are easy to find.

Top comments (0)