
Each ML/AI project stakeholder requires specialized tools that efficiently enable them to manage the various stages of an ML/AI project, from data preparation and model development to deployment and monitoring. They tend to use specialized open source tools because of their contribution as a significant catalyst to the advancement, development, and ease of AI projects. As a result, numerous open source AI tools have emerged over the years, making it challenging to pick from the available options.
This article highlights some factors to consider when picking open source tools and introduces you to 25 open-source options that you can use for your AI project.
Picking open source tools for AI project
The open source tooling model has allowed companies to develop diverse ML tools to help you handle particular problems in an AI project. The AI tooling landscape is already quite saturated with tools, and the abundance of options makes tool selection difficult. Some of these tools even provide similar solutions. You may be tempted to lean toward adopting tools just because of the enticing features they present. However, there are other crucial factors that you should consider before selecting a tool, which include:
- Popularity
- Impact
- Innovation
- Community engagement
- Relevance to emerging AI trends.
Popularity
Widely adopted tools often indicate active development, regular updates, and strong community support, ensuring reliability and longevity.
Impact
A tool with a track record of addressing pain points, delivering measurable improvements, providing long-term project sustainability, and adapting to evolving needs of the problems of an AI project is a good measure of an impactful tool that stakeholders are interested in leveraging.
Innovation
Tools that embrace more modern technologies and offer unique features demonstrate a commitment to continuous improvement and have the potential to drive advancements and unlock new possibilities.
Community engagement
Active community engagement fosters collaboration, provides support, and ensures a tool's continued relevance and improvement.
Relevance to emerging AI trends
Tools aligned with emerging trends like LLMs enable organizations to leverage the latest capabilities, ensuring their projects remain at the forefront of innovation.
25 Open Source Tools for Your AI Project
Based on these factors, here are 25 tools that you and the different stakeholders on your team can use for various stages in your AI project.
1. KitOps
Multiple stakeholders are involved in the machine learning development lifecycle which requires different MLOps tools and environments at various stages of the AI project., which makes it hard to guarantee an organized, portable, transparent, and secure model development pipeline.
This introduces opportunities for model lineage breaks and accidental or malicious model tampering or modifications during model development. Since the contents of a model are a "black box”—without efficient storage and lineage—it is impossible to know if a model's or model artifact's content has been tampered with between model development, staging, deployment, and retirement pipelines.

KitOps provides AI project stakeholders with a secure package called ModelKit that they can use to share and manage models, code, metadata, and artifacts throughout the ML development lifecycle.
The ModelKit is an immutable OCI-standard artifact that leverages normal container-native technologies (similar to Docker and Kubernetes), making them seamlessly interoperable and portable across various stakeholders using common software tools and environments. As an immutable package, ModelKit is tamper-proof. This tamper-proof property provides stakeholders with a versioning system that tracks every single update to any of its content (i.e., models, code, metadata, and artifacts) throughout the ML development and deployment pipelines.
2. LangChain
LangChain is a machine learning framework that enables ML engineers and software developers to build end-to-end LLM applications quickly. Its modular architecture allows them to easily mix and match its extensive suite of components to create custom LLM applications.
LangChain simplifies the LLM application's development and deployment stages with its ecosystem of interconnected parts, consisting of LangSmith, LangServe, and LangGraph. Together, they enable ML engineers and software developers to build robust, diverse, and scaleable LLM applications efficiently.
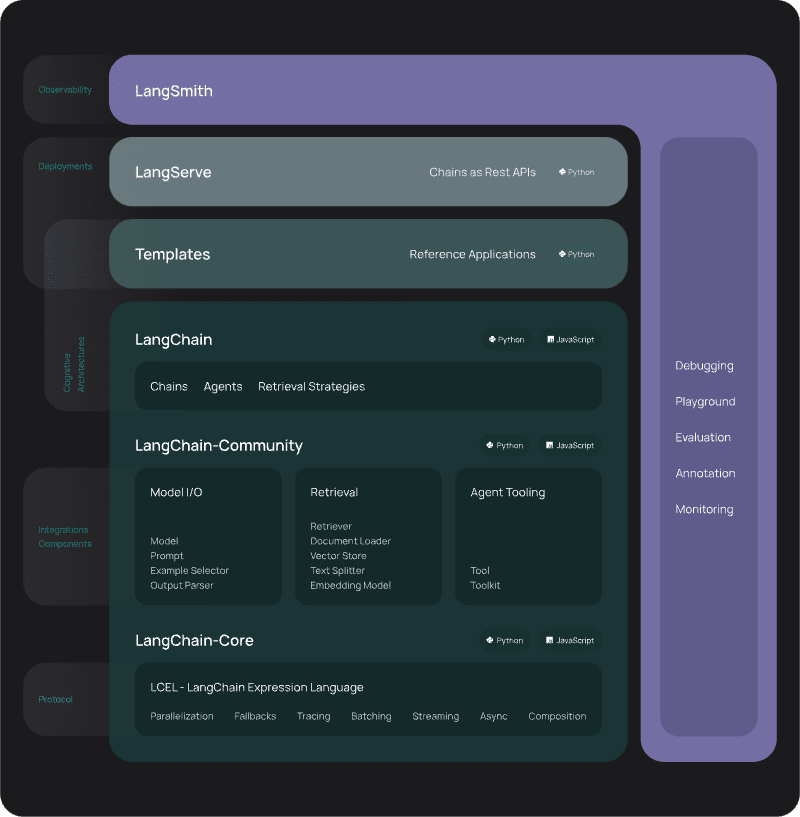
LangChain enables professionals without a strong AI background to easily build an application with large language models (LLMs).
3. Pachyderm
Pachyderm is a data versioning and management platform that enables engineers to automate complex data transformations. It uses a data infrastructure that provides data lineage via a data-driven versioning pipeline. The version-controlled pipelines are automatically triggered based on changes in the data. It tracks every modification to the data, making it simple to duplicate previous results and test with various pipeline versions.

Pachyderm's data infrastructure provides "data-aware" pipelines with versioning and lineage.
4. ZenML
ZenML is a structured MLOps framework that abstracts the creation of MLOps pipelines, allowing data scientists and ML engineers to focus on the core steps of data preprocessing, model training, evaluation, and deployment without getting bogged down in infrastructure details.

ZenML framework abstracts MLOps infrastructure complexities and simplifies the adoption of MLOps, making the AI project components accessible, reusable, and reproducible.
5. Prefect
Prefect is an MLOps orchestration framework for machine learning pipelines. It uses the concepts of tasks (individual units of work) and flows (sequences of tasks) to construct an ML pipeline for running different steps of an ML code, such as feature engineering and training. This modular structure enables ML engineers to simplify creating and managing complex ML workflows.

Prefect simplifies data workflow management, robust error handling, state management, and extensive monitoring.
6. Ray
Ray is a distributed computing framework that makes it easy for data scientists and ML engineers to scale machine learning workloads during model development. It simplifies scaling computationally intensive workloads, like loading and processing extensive data or deep learning model training, from a single machine to large clusters.
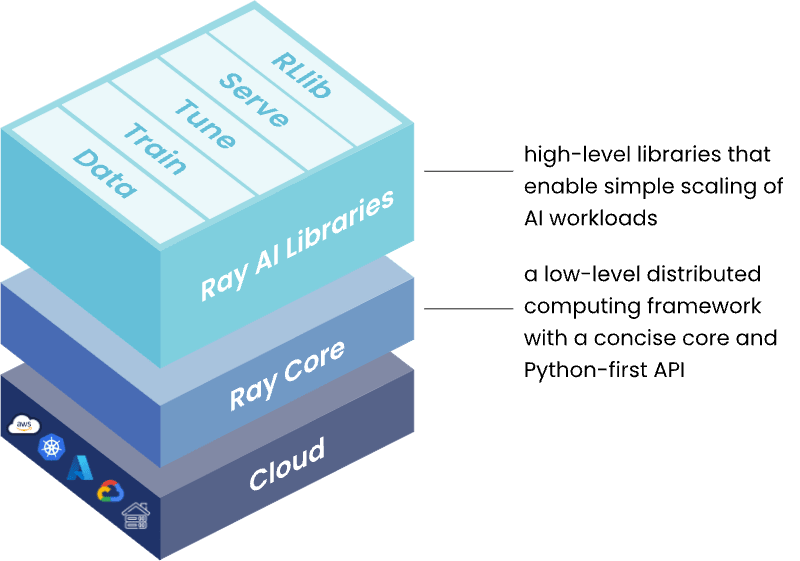
Ray's core distributed runtime, making it easy to scale ML workloads.
7. Metaflow
Metaflow is an MLOps tool that enhances the productivity of data scientists and ML engineers with a unified API. The API offers a code-first approach to building data science workflows, and it contains the whole infrastructure stack that data scientists and ML engineers need to execute AI projects from prototype to production.
8. MLflow
MLflow allows data scientists and engineers to manage model development and experiments. It streamlines your entire model development lifecycle, from experimentation to deployment.
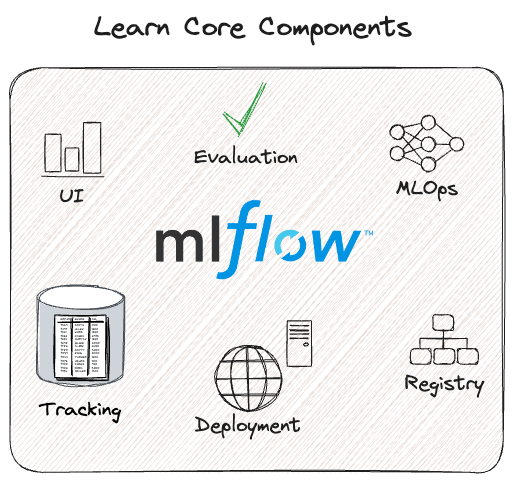
MLflow’s key features include:
MLflow tracking: It provides an API and UI to record and query your experiment, parameters, code versions, metrics, and output files when training your machine learning model. You can then compare several runs after logging the results.
MLflow projects: It provides a standard reusable format to package data science code and includes API and CLI to run projects to chain into workflows. Any Git repository / local directory can be treated as an MLflow project.
MLflow models: It offers a standard format to deploy ML models in diverse serving environments.
MLflow model registry: It provides you with a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of a model. It also enables model lineage (from your model experiments and runs), model versioning, and development stage transitions (i.e., moving a model from staging to production).
9. Kubeflow
Kubeflow is an MLOps toolkit for Kubernetes. It is designed to simplify the orchestration and deployment of ML workflows on Kubernetes clusters. Its primary purpose is to make scaling and managing complex ML systems easier, portable, and scalable across different infrastructures.

Kubeflow is a key player in the MLOps landscape, and it introduced a robust and flexible platform for building, deploying, and managing machine learning systems on Kubernetes. This unified platform for developing, deploying, and managing ML models enables collaboration among data scientists, ML engineers, and DevOps teams.
10. Seldon core
Seldon core is an MLOps platform that simplifies the deployment, serving, and management of machine learning models by converting ML models (TensorFlow, PyTorch, H2o, etc.) or language wrappers (Python, Java, etc.) into production-ready REST/GRPC microservices. Think of them as pre-packaged inference servers or custom servers. Seldon core also enables the containerization of these servers and offers out-of-the-box features like advanced metrics, request logging, explainers, outlier detectors, A/B tests, and canaries.
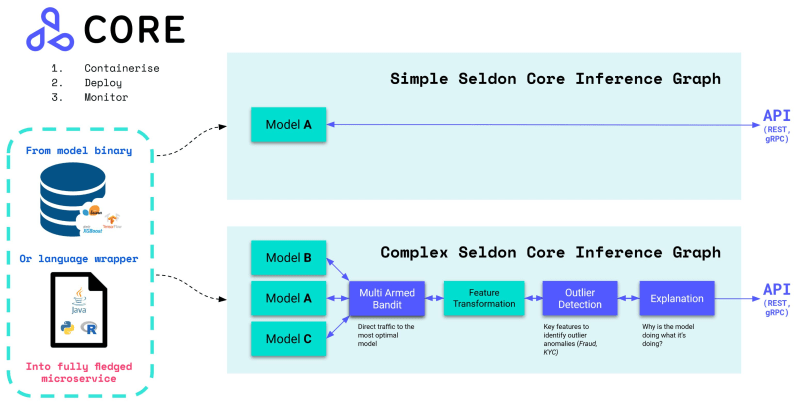
Seldon Core's solution focuses on model management and governance. Its adoption is geared toward ML and DevOps engineers, specifically for model deployment and monitoring, instead of small data science teams.
11. DVC (Data Version Control)
Implementing version control for machine learning projects entails managing both code and the datasets, ML models, performance metrics, and other development-related artifacts. Its purpose is to bring the best practices from software engineering, like version control and reproducibility, to the world of data science and machine learning. DVC enables data scientists and ML engineers to track changes to data and models like Git does for code, making it able to run on top of any Git repository. It enables the management of model experiments.

DVC's integration with Git makes it easier to apply software engineering principles to data science workflows.
12. Evidently AI
EvidentlyAI is an observability platform designed to analyze and monitor production machine learning (ML) models. Its primary purpose is to help ML practitioners understand and maintain the performance of their deployed models over time. Evidently provides a comprehensive set of tools for tracking key model performance metrics, such as accuracy, precision, recall, and drift detection. It also enables stakeholders to generate interactive reports and visualizations that make it easy to identify issues and trends.

13. Mage AI
Mage AI is a data transforming and integrating framework that allows data scientists and ML engineers to build and automate data pipelines without extensive coding. Data scientists can easily connect to their data sources, ingest data, and build production-ready data pipelines within Mage notebooks.

14. ML Run
ML Run provides a serverless technology for orchestrating end-to-end MLOps systems. The serverless platform converts the ML code into scalable and managed microservices. This streamlines the development and management pipelines of the data scientists, ML, software, and DevOps/MLOps engineers throughout the entire machine learning (ML) lifecycle, across their various environments.
15. Kedro
Kedro is an ML development framework for creating reproducible, maintainable, modular data science code. Kedro improves AI project development experience via data abstraction and code organization. Using lightweight data connectors, it provides a centralized data catalog to manage and track datasets throughout a project. This enables data scientists to focus on building production level code through Kedro's data pipelines, enabling other stakeholders to use the same pipelines in different parts of the system.

Kedro focuses on data pipeline development by enforcing SWE best practices for data scientists.
16. WhyLogs
WhyLogs by WhyLabs is an open-source data logging library designed for machine learning (ML) models and data pipelines. Its primary purpose is to provide visibility into data quality and model performance over time.
With WhyLogs, MLOps engineers can efficiently generate compact summaries of datasets (called profiles) that capture essential statistical properties and characteristics. These profiles track changes in datasets over time, helping detect data drift – a common cause of model performance degradation. It also provides tools for visualizing key summary statistics from dataset profiles, making it easy to understand data distributions and identify anomalies.

17. Feast
Defining, storing, and accessing features for model training and online inference in silos (i.e., from different locations) can lead to inconsistent feature definitions, data duplication, complex data access and retrieval, etc. Feast solves the challenge of stakeholders managing and serving machine learning (ML) features in development and production environments.
Feast is a feature store that bridges the gap between data and machine learning models. It provides a centralized repository for defining feature schemas, ensuring consistency across different teams and projects. This can ensure that the feature values used for model inference are consistent with the state of the feature at the time of the request, even for historical data.
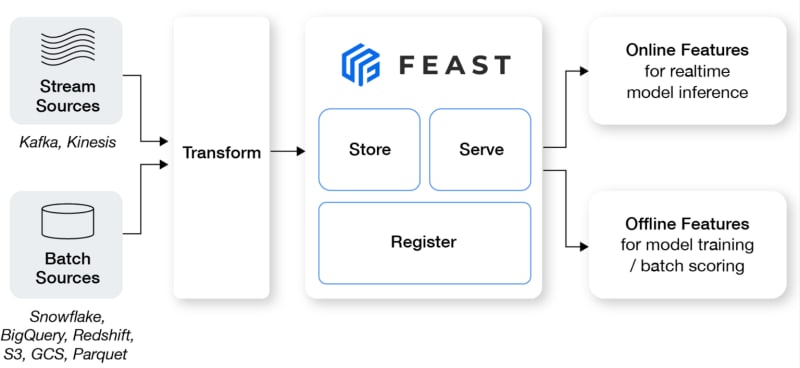
Feast is a centralized repository for managing, storing, and serving features, ensuring consistency and reliability across training and serving environments.
18. Flyte
Data scientists and data and analytics pipeline engineers typically rely on ML and platform engineers to transform models and training pipelines into production-ready systems.
Flyte empowers data scientists and data and analytics engineers with the autonomy to work independently. It provides them with a Python SDK for building workflows, which can then be effortlessly deployed to the Flyte backend. This simplifies the development, deployment, and management of complex ML and data workflows by building and executing reliable and reproducible pipelines at scale.

19. Featureform
The ad-hoc practice of data scientists developing features for model development in isolation makes it difficult for other AI project stakeholders to understand, reuse, or build upon existing work. This leads to duplicated effort, inconsistencies in feature definitions, and difficulties in reproducing results.
Featureform is a virtual feature store that streamlines data scientists' ability to manage and serve features for machine learning models. It acts as a "virtual" layer over existing data infrastructure like Databricks and Snowflake. This allows data scientists to engineer and deploy features directly to the data infrastructure for other stakeholders. Its structured, centralized feature repository and metadata management approach empower data scientists to seamlessly transition their work from experimentation to production, ensuring reproducibility, collaboration, and governance throughout the ML lifecycle.
20. Deepchecks
Deepchecks is an ML monitoring tool for continuously testing and validating machine learning models and data from an AI project's experimentation to the deployment stage. It provides a wide range of built-in checks to validate model performance, data integrity, and data distribution. These checks help identify issues like model bias, data drift, concept drift, and leakage.
21. Argo
Argo provides a Kubernetes-native workflow engine for orchestrating parallel jobs on Kubernetes. Its primary purpose is to streamline the execution of complex, multi-step workflows, making it particularly well-suited for machine learning (ML) and data processing tasks. It enables ML engineers to define each step of the ML workflow (data preprocessing, model training, evaluation, deployment) as individual containers, making it easier to manage dependencies and ensure reproducibility.
Argo workflows are defined using DAGs, where each node represents a step in the workflow (typically a containerized task), and edges represent dependencies between steps. Workflows can be defined as a sequence of tasks (steps) or as a Directed Acyclic Graph (DAG) to capture dependencies between tasks.

22. Deep Lake
Deep Lake (formerly Activeloop Hub) is an ML-specific database tool designed to act as a data lake for deep learning and a vector store for RAG applications. Its primary purpose is accelerating model training by providing fast and efficient access to large-scale datasets, regardless of format or location.

23. Hopsworks feature store
Advanced MLOps pipelines with at least an MLOps maturity level 1 architecture require a centralized feature store. Hopsworks is a perfect feature store for such architecture. It provides an end-to-end solution for managing ML feature lifecycle, from data ingestion and feature engineering to model training, deployment, and monitoring. This facilitates feature reuse, consistency, and faster model development.

24. NannyML
NannyML is a Python library specialized in post-deployment monitoring and maintenance of machine learning (ML) models. It enables data scientists to detect and address silent model failure, estimate model performance without immediate ground truth data, and identify data drift that might be responsible for performance degradation.
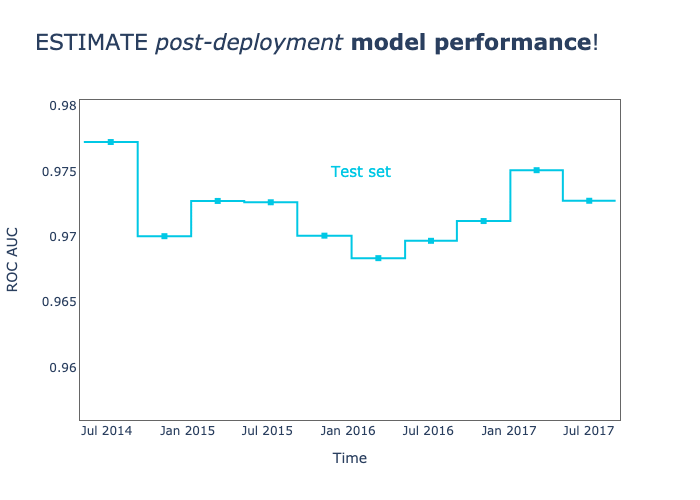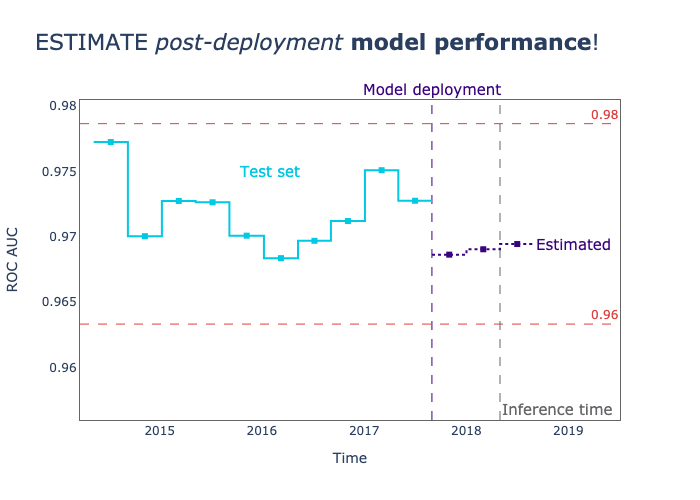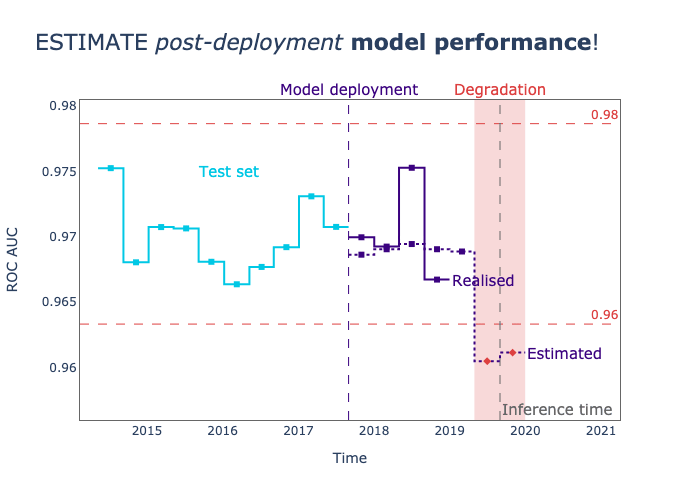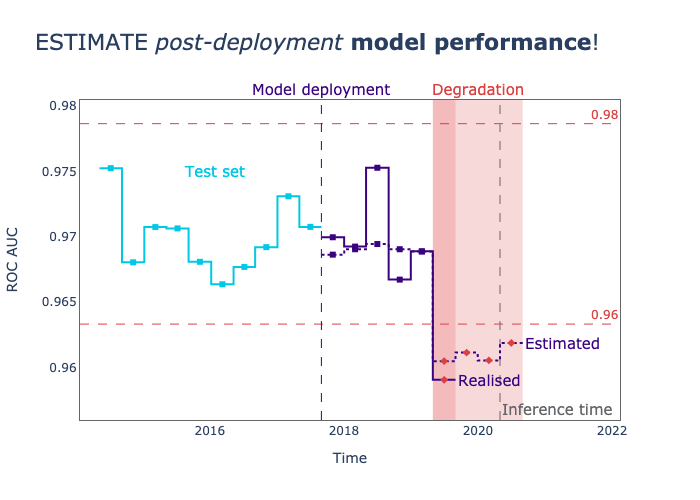
25. Delta Lake
Delta Lake is a storage layer framework that provides reliability to data lakes. It addresses the challenges of managing large-scale data in lakehouse architectures, where data is stored in an open format and used for various purposes, like machine learning (ML). Data engineers can build real-time pipelines or ML applications using Delta Lake because it supports both batch and streaming data processing. It also brings ACID (atomicity, consistency, isolation, durability) transactions to data lakes, ensuring data integrity even with concurrent reads and writes from multiple pipelines.

Considering factors like popularity, impact, innovation, community engagement, and relevance to emerging AI trends can help guide your decision when picking open source AI/ML tools, especially for those offering the same value proposition. In some cases, such tools may have different ways of providing solutions for the same use case or possess unique features that make them perfect for a specific project use case.
For instance, some model development, deployment, and management tools like MLRun or Kubeflow provide a platform or API for easy development of an AI project. This usually dictates the stakeholder's use of the platform's environment, infrastructure, and workflows. KitOps provides its solution as a package that allows stakeholders in an AI project to version and share their work while using their existing tools, environment, and development practices. To try out the KitOps solution, follow this guide to get started.





Top comments (10)
If I calculated correctly, if I use 25 tools and each cuts my dev time in half, my dev time will be (0.5^25)% of what it used to be.
That is 0.00000298%. That means these tools make my job at least 50,000 times faster. 😱
That's one way to look at it LOL
It's kinda like the SaaS platforms that all increase sales and revenue by X%. Why even have a sales team when you can just buy 30 SaaS products and increase your ARR by 30% MoM to infinity.
Haha 😂
But really, nice job on your article.
Thanks a ton!
LOL
😊
Thank you very much for sharing!
Nicely done! I sent a link for KitOps to my manager after reading your article, and he's enthused.
I'm going to post this whole article for the team to check out all the tools we could be using.
Awesome, thanks for that! Our team would be more than happy to have a call with you guys if it makes sense. jesse at jozu dot com
Great read!
What is your opinion on fine.dev?
Some comments may only be visible to logged-in visitors. Sign in to view all comments.