
Flaky tests are insidious. Fighting flakiness can sometimes feel like trying to fight entropy; you know it’s a losing battle, and it’s a battle you must engage in again and again and again.
We define a “flaky” test result as a test that exhibits both a passing and a failing result with the same code.
At Undefined Labs, we’ve had a chance to talk to dozens of engineering organizations of all different sizes, ranging from 3 person startups to Fortune 500 companies. We listen and gather feedback around all things “test.”
When we talk about the frustrations and major issues organizations encounter with testing, inevitably, flaky tests will always come up. And when we get to this part of the discussion, the people we’re talking to will have a visible shift in demeanor, wearing the expression of someone trying to put out more fires than they have water.
We, too, once wore this same expression. While we were at Docker, the co-founders of Undefined Labs and I were spread across and working on different products, from enterprise on-premise solutions, CLI developer tools, to various SaaS (Software as a Service) solutions. We also got to see the work of our co-workers on various open-source projects like Docker Engine, Docker Swarm, and Docker Compose.
It was this experience and the frustrations with testing in general that led to the creation of Undefined Labs and our first product, Scope.
Throughout our talks with these various engineering organizations, we’ve heard about all kinds of different solutions to tackle flakiness, with varying success. We noticed that the organizations that were best able to cope with flakiness had dedicated teams ready to create best practices, custom tools, and workflows to deal with flakiness.
But not all teams had such lavish resources to throw at the problem, without having to worry about efficiency. We saw some of these teams hack together workflows through existing tooling and scripts. And some teams did nothing at all. They threw their hands up and succumbed to the torrent of flaky tests.
I think it’s paramount to have a plan in place to address flaky tests. Flaky tests are bad, but they’re even worse than you think.
Why flaky tests are even worse than you think (is that even possible?)
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--h1wWZ5tJ--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/4512/0%2Ao9MuWmXo7Xj-8kjK)
Testing plays a significant role in the productivity of engineers.
Google on developer productivity:
“Productivity for developers at Google relies on the ability of the tests to find real problems with the code being changed or developed in a timely and reliable fashion.”
The keywords here are “real problems,” “timely,” and “reliable fashion,” all of which seem to point a big fat finger directly at the consequences of flaky tests.
When tests behave as expected, they’re a boon to productivity. But as soon as tests can’t find real problems, their results arrive too slowly or can’t be trusted, it turns into one of the most miserable time-sucks known to modern humanity.
Flaky tests love collateral damage
Not only do flaky tests hurt your own productivity, but there is cascading loss of productivity experienced by everyone upstream.
When master is broken, everything comes to a screeching halt.
We’ve seen some of the highest performing engineering organizations implement various strategies to mitigate this collateral damage. They gate and prevent flaky tests from ever making it to master and/or have a zero-tolerance policy for flaky tests; once they’ve been identified, they’re quarantined until fixed.
Other tests, and even the entire test suite, can also be collateral damage. Test flakiness left unabated can completely ruin the value of an entire test suite.
There are even greater implications of flaky tests; the second and third-order consequences of having flaky tests is that it spreads apathy if unchecked. We’ve talked to some organizations that reached 50%+ flaky tests in their codebase, and now developers hardly ever write any tests and don’t bother looking at the results. Testing is no longer a useful tool to improve code quality within that organization.
Ultimately, it will be the end-users of your product that bear the brunt of this cost. You’ve essentially outsourced all testing to your users and have accepted the consequences of adopting the most expensive testing strategy as your only strategy.
Increases Costs
As mentioned by Fernando, our CTO, in his blog post Testing in the Cloud Native Era, tests have an associated cost attached to them. And when it comes to flaky tests, there are hidden costs, and the cost is generally increased across the board: creation cost, execution cost, fixing cost, business cost, and psychological cost.
Creation cost: this includes both the time and effort needed to write the test, as well as making the system testable. A flaky test requires you to re-visit this step more often than you would like, to either fix the test or make the system more testable.
Execution cost: if you’re interested in trying to generate signal from your flaky tests without necessarily fixing it, you can execute the test more than once.
Additional executions can be manual — we’ve all hit the “retry build” button, with the hope that this time, things will be different. We’ve also seen some teams leverage testing frameworks that allow for automatic retries for failing tests.
Execution cost can also potentially manifest itself as requiring a platform team to help keep the pipeline unblocked and moving at a fast enough pace to service the entire organization. Your team needs both infrastructure and scaling expertise if you want to reach high levels of execution.
There’s also the cost of the infrastructure required to run your tests, and perhaps the most valuable resource of all, your time. Increased executions mean more time.
Fixing cost: debugging and fixing flaky tests can potentially take hours of your workweek. Some of the most frustrating parts about flaky tests are reproducing them and determining the cause for flakiness.
Fixing a flaky test also demands expertise and familiarity with the code and/or test. Junior developers brought in to work on a legacy code base with many flaky tests, will certainly require the oversight of a more senior developer that has spent enough time to build up sufficient context to fix these tests.
This is all made worse if you have dependencies (it’s another team’s fault), run tests in parallel (good luck finding only your specific test’s logs), or have long feedback cycles (builds that take hours with results only available after the entire build is finished).
And in the worst cases, you lack the information and visibility into your systems necessary to fix the test, or the fixing cost can be too high to be worth paying.
Business cost: Flakiness consumes the time of developers investigating them, and developers represent one of the most expensive and scarce resources for any business. Fixing flaky tests adds accidental complexity, which ultimately leads to more of the developer’s time being taken away from working on new features.
Other parts of the business will also be impacted due to potential delays in project releases. If the same number of development cycles are required to release a new product, but now every development cycle takes longer, products will be released late, impacting marketing, sales, customer success, and business development.
Psychological cost: responsibility without the knowledge, tooling, and systems in place to actually carry out that responsibility is a great way to set someone up for failure and cause psychological stress to your developers.
And what’s more, flaky tests will force you to undergo this cost cycle of a test more than just once while trying to remove or mitigate the flakiness. A great test can have just one up-front creation cost, minimal execution cost (because you trust the first signal it gives you), and very little maintenance cost. Every time a test flakes, it will require you to re-absorb the costs of the test.
Reduces Trust, Leads to an Unhealthy Culture, and Hurts Job Satisfaction

When it comes to job satisfaction for engineers, I think it’s safe to say we all prefer working in an organization with a healthy culture. While we may each have our own definition of what a healthy culture looks like, having trust is a major factor. If you don’t trust your organization, your team, or your co-workers, you’ll most likely be looking for the exit sometime soon.
If your tests seemingly pass and fail on a whim, it’s only a matter of time before trust is eroded. And once trust is eroded, it’s very difficult to build back up. I also think that trust works from the bottom up. You need a solid foundation in which trust can begin to gain traction.
Organizations that try to increase trust among co-workers from the top-down, usually sow even more distrust. If management is telling me I need to trust my co-workers, then they must be untrustworthy, otherwise, why would they even bring this up?
When it comes to engineering organizations, a major factor in that foundational level of trust often starts with testing. The testing strategy and general attitude towards testing speak volumes about an engineering organization’s culture.
If you can’t trust your tests and testing processes, then everything else built on top of tests will slowly crumble. It may not happen quickly, but cracks will begin to form, and morale will suffer.
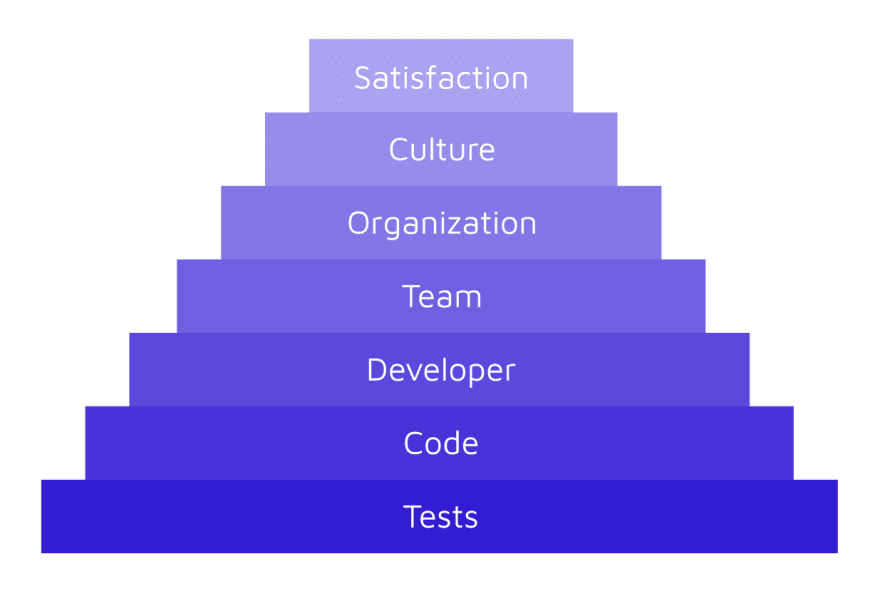
This is why the prevalence of flaky tests and what you do when they occur matters so much. Flakiness left unguarded, will destroy the trust people have in their tests.
If there is rampant, inadequately addressed flakiness in your tests, then you can’t trust the tests.
If you can’t trust the tests, then you can’t trust the code.
If you can’t trust the code, then you can’t trust developers.
If you can’t trust developers, then you can’t trust your team.
If you can’t trust your team, then you can’t trust the organization.
If you can’t trust your organization, then there’s obviously a lack of trust in the culture, which means you work at a company with an unhealthy culture.
If your company has an unhealthy culture, your job satisfaction will steadily decline.
There will be a tipping point where you transition from thinking about your organization as an organization that has flaky tests, to the kind of organization that has flaky tests. Once you make the mental shift and believe it’s because of the organization that there are so many flaky tests, trust in the organization has been eroded.
With job satisfaction continuing to plummet, it’s at this time that your top engineering talent will begin looking elsewhere, actively searching, or maybe just a little more willing to open the emails and messages from recruiters that they had been previously ignoring.
The saving grace of this situation is that this degradation happens over time. With the right strategies and tools, you can mitigate and even reverse the damage. But it’s not easy, and you can’t do it alone.
Flaky tests aren’t going away
Flakiness is only getting worse, not better. As your codebase and test suites grow, so too will the number of flaky tests and results. As you transition, or if you’re already using a microservice architecture, you can have many dependencies. As dependencies increase, flakiness is magnified.
For example, even if all of your microservices have 99.9% stability, if you have 20+ dependencies each with the same stability, you actually end up having a non-trivial amount of flakiness:
98.01% stability for 20 dependencies
97.04% stability for 30 dependencies
95.12% stability for 50 dependencies
As your engineering organization scales, how it addresses flakiness will be one of the most important factors impacting overall productivity.
A presentation was released by Google, The State of Continuous Integration Testing @Google, where they collected a large sample of internal test results over a one month time period and uncovered some interesting insights:
84% of test transitions from Pass -> Fail were from flaky tests
Only 1.23% of tests ever found a breakage
Almost 16% of their 4.2 million tests have some level of flakiness
Flaky failures frequently block and delay releases
They spend between 2–16% of their compute resources re-running flaky tests
Google concluded:
Testing systems must be able to deal with a certain level of flakiness
In order to address flaky tests, you need systems thinking
In google’s conclusion, they mentioned testing systems must be able to deal with a certain level of flakiness, not teams or engineers. Looking from the bottom up, from the perspective of an individual, will blind you to the larger universal patterns at work and how they must change.
To understand why no one person can do it alone, I like to turn towards systems thinking. The power of systems thinking comes when you shift your perspective of the world away from a linear one, and towards a circular one. This reveals a world in which there is a much richer and complex interconnectedness between seemingly everything.
While seeing things as they truly are can be eye-opening, it can also be a little daunting. Most of the common ways we know to affect change have little leverage.
Donella Meadows in her book Thinking in Systems: A Primer, described the different ways one could influence a system. Here’s a great graphic that shows them all stack-ranked:

What’s important to take away from this graphic is that the capacity of an individual is limited to the least powerful system interventions. This is why teams or organizations with notoriously high turnover rates continue to have high turnover rates, even as new individuals are placed within the system. By and large, teams don’t hire bad employees who turnover quickly; there are only bad teams with high turnover rates.
If you want to have a high performing culture and have an organization that attracts the best engineers, you’re going to need to have a system in place that reinforces best practices, rewards behavior you want to be repeated, has all of the right feedback loops, to the right people, in the right context, in the right time frame, and has redundancy built in to ensure the system is resilient.
A CI/CD pipeline, the team that manages it, the various development teams that are dependent on it - they’re all part of a greater system. Whether the system was designed or grew organically, they are a system.
So when it comes to handling flakiness effectively and with resilience, what are the common system patterns implemented by the best engineering organizations?
Common patterns found in systems successfully addressing flaky tests
There were a handful of clear patterns that seemed to crop up in every instance of teams that successfully handled flaky tests:
Identification of flaky tests
Critical workflow ignores flaky tests
Timely flaky test alerts routed to the right team or individual
Flaky tests are fixed fast
A public report of the flaky tests
Dashboard to track progress
Advanced: stability/reliability engine
Advanced: quarantine workflow
Let’s go over each of these a little bit more in-depth…
Identification of flaky tests
The first step in dealing with flaky tests is knowing which tests are flaky and how flaky they are.
It also helps to have your tests exist as a first-class citizen, which will allow you to keep track and identify flaky tests over time/commits. This will enable tagging tests as flaky, which will kick off all of the other patterns listed below.
When working with flaky tests, it can also be very useful to have test flakiness propagate throughout your system, so you can filter your test list or results by “flaky”, manually mark tests as “flaky” or remove the “flaky” tag if no longer appropriate.
We’ve also seen different organizations have particular dimensions of flakiness that were important to them: test flakiness per commit, flakiness across commits, test flakiness agnostic to the commit and only tied to the test, and flakiness across devices & configurations.
Test flakiness per commit:
Re-run failing tests multiple times using a test framework or by initiating multiple builds
If the test shows both a passing and failing status, then this “test & commit” pairing is deemed flaky
Test flakiness agnostic to the commit and only tied to the test
A test is tagged as flaky as soon as it exhibits flaky behavior
Exhibiting flaky behavior may occur in a single commit, or aggregated across multiple commits (e.g. you never rebuild or rerun tests but still want to identify flaky tests)
The test will stay tagged as flaky until it has been deemed fixed
The prior history and instances of flakiness will stay as metadata of the test
This can help with the verification of a test failure, to determine if it’s broken or likely a flake, i.e. if this test was previously flaky but hasn’t exhibited flakiness in the past two builds, this recent failure means it’s still likely flaky and was never fixed
Test flakiness across devices & configurations
Re-run a single test multiple times across many device types and/or whatever configurations are most important to you i.e. iPhone 11 Pro vs iPhone XS, iOS 12 vs iOS 13, or Python 2.7 vs Python 3.0
A test can be flaky for a specific device or configuration, i.e. the test both passes and fails on the same device
A test can be flaky across devices and configurations, i.e. a test passes on one device, but fails on another device
The most common pattern we saw, were teams rerunning failed tests anywhere from 3 to 200 times. A test was then labeled as flaky in either a binary fashion (e.g. at least one fail and at least one pass) or there was a threshold and flakiness score given (e.g. test must fail more than 5 out of 100 retries).
Identifying flaky tests based on a single execution
There are techniques and tools available (including the product I work on, Scope) that can help identify flaky tests, only requiring a single execution. Here’s a brief summary of how it works if you’ve just recently pushed a new commit and a test fails:
You need access to the source code and the commit diff
You need access to the test path, which is the code covered by the test that failed
You can then cross-reference the two, to identify if the commit introduced a change to the code covered in this particular tests’ test path
If there was a change to the code in the test path, it’s likely that this is a test failure. And the reason for the test failure is likely at the intersection of the commit diff and the test path
If there was no change to the code in the test path, it’s a likely sign the test is flaky
Critical workflow ignores flaky tests
Once the test is identified as flaky, the results from this test are ignored when it comes to your critical workflow. We oftentimes see organizations set up multiple workflows, one dedicated to the initial testing of PRs and one dedicated to master.
By catching flaky tests before they make it to master, you can then choose to ignore the test results of flaky tests or quarantine these flaky tests and only allowing them to run in specific pipelines if any.
Timely flaky test alerts routed to the right team or individual
In order for a system to properly function and remain resilient, it needs feedback loops. Not just any feedback loop; these loops need to be timely, convey the right information and context, be delivered to the right actor, and this actor must be able to take the right action using the information and context delivered.
The pieces when assembled:
Notification once the flaky behavior is identified (through email, Slack, JIRA ticket, GitHub issue, etc.)
Notification must be sent to the party who will be responsible for fixing this flaky test (test author, commit author, service owner, service team, etc.)
The notification must contain or point to the relevant information required to begin fixing the test
Flaky tests are fixed fast
Most of these organizations place a high priority on fixing flaky tests. Most of the teams we saw, usually fixed flaky tests within the week. The longest we came across that still proved to be fairly effective was a month.
The most important takeaway though, is that whenever the time elapsed to fix a flaky test surpassed the explicit or implicit organizational threshold, the test was almost always forgotten and never fixed.
In order to fix these tests, varying levels of tools and workflows were set up for developers to begin debugging. These systems always had some smattering of the following: traces, logs, exceptions, historical data points, diff analysis between the current failing and last passing execution, build info, commit info, commit diff, test path, prior trends & analysis).
Essentially, the more visibility and the more context you can provide to your developers for the specific test in question, while at the same time removing any noise from irrelevant tests, the better.
A public report of the flaky tests
This can take many different forms, but the gist of this pattern is to make public the status of the flaky tests identified and the flaky tests fixed, with an emphasis on the flaky tests identified but that have not yet been fixed.
Some teams had this information available via a slackbot along with the “time since identified”, or would post this list weekly every Monday in the team channel. A couple of organizations even surface these flaky tests within the dashboards used to display metrics for team performance.
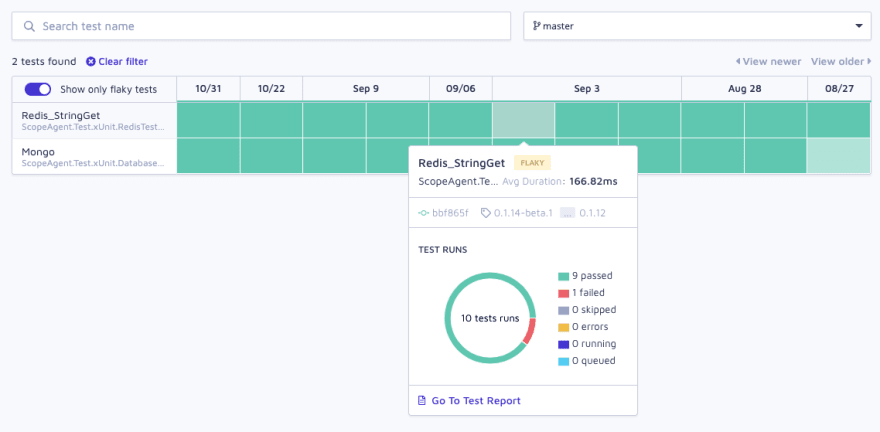
Dashboard to track progress
In addition to seeing the current state of flaky tests in your system, most organizations have a way to track progress over time. If your goal is to reduce flakiness, how will you know if you’ve actually hit your goal? How do you know if things are getting better and not worse?
This high-level system feedback is necessary to make adjustments to the overall system and help identify patterns that aren’t working, or are broken and need fixing.
At its most basic, this is just a timeline of your builds and the build statuses.
In more advanced versions, you might get every test execution from every test, the ability to filter by flaky tests, multiple builds & commits worth of information, and the date each of these results were captured.
Here’s a screenshot of Scope, viewing the Insights for a particular service:
Advanced: stability/reliability engine
This is an advanced use case, which we’ve only seen versions being used at some of the biggest tech companies (Netflix, Dropbox, Microsoft, & Google), but we think could be useful for any organization trying to deal with flaky tests.
The general idea is to have two different testing workflows, one for the critical path, and one for the non-critical path. The primary objective of the stability engine is to keep the critical path green. This is done by creating a gating mechanism with specific rules around the definition of “stable tests” and “unstable tests”.
A test is deemed “unstable” until proven “stable.” So every new test or “fixed” test is submitted to the stability engine, exercises the test in different ways depending on your definition of flaky, and ultimately determines if the test is stable or not, and if unstable, how unstable.
Unstable tests are either quarantined and never run in your critical path, or the test results of these unstable tests are just ignored.
All stable tests are now included in your “stable” tests list and will run in your critical path.
Any test deemed “unstable” must be remediated, and once fixed, re-submitted to the stability engine.
For example, this may be as simple as:
For any new PR, for all new and fixed tests (tests that were previously unstable), execute each test 20 times
If the test passes more than once, but less than 20 times, the test is marked as unstable
Fixed tests that are still unstable remain quarantined and their test results are ignored
If there are any new unstable tests in the PR, the PR is prevented from being merged
Advanced: quarantine workflow
The most basic version of the quarantine workflow is to simply mark the test results of flaky tests as “ignored” in your critical path.
However, we’ve seen some interesting workflows implemented by savvy companies. A quarantine workflow makes it easy for developers to follow all of the patterns listed above and helps keep your critical path green.
For example, this is the workflow we’re currently working on for Scope (each of these steps are optional):
Flaky test identified
The flaky test is added to the Quarantine List and skipped during testing
JIRA/GitHub issue is created
Automatically remove the test from Quarantine List when the issue is closed
Ping commit author on Slack
Remind author of their Quarantined test(s), every week
Ability to view Quarantine List
Ability to manually remove tests from the Quarantine List
With a proper quarantine workflow implemented, it really helps ensure the collateral damage of a flaky test is minimized, and the responsible party for fixing the test is properly notified.
Conclusion
One of the best techniques to ensure high code quality is to use tests. Unfortunately, as applications become more complex and codebases grow larger, test flakiness will begin to rear its ugly head more often. How your organization handles flakiness will be a major factor in defining your engineering culture.
Ultimately, no single person can fix flakiness as just a single actor within a larger system. Systems thinking should be used and there are useful patterns that are already being implemented by many of the highest performing organizations.
A peaceful co-existence with flaky tests is available to anyone willing to invest in the tools and processes necessary.
Further reading

Testing is a core competency to build great software. But testing has failed to keep up with the fundamental shift in how we build applications. Scope gives engineering teams production-level visibility on every test for every app — spanning mobile, monoliths, and microservices.
Your journey to better engineering through better testing starts with Scope.

Top comments (0)