Written by Adrián López Calvo

Nowadays it is quite uncommon to have dedicated Database Admins (DBAs) on application development teams. Whether it’s the adoption of microservices architectures, cloud, or DevOps processes that is to blame, more and more development teams are now responsible for their databases. Now more than ever, solid database skills are indispensable on your path to becoming a proficient programmer.
Response-time is a key indicator of the performance of any application,. Database optimization can be one of the fastest ways to give a speed boost to your application, website or API. Learning the basics of profiling and optimizing SQL queries is actually not as hard as it might seem, and you should not feel intimidated by it. In this post, I will explain the general steps I followed with a real-world scenario I ran into recently while working on Scope. Armed with the skills described in this post, you’ll be optimizing your own database queries in no time!
Note: our main database is PostgreSQL and most of our backend stack is written in Python. While the concepts I cover should also be applicable to MySQL or other SQL databases, please bear in mind that all practical examples in this article will be for PostgreSQL. There will also be some recommendations or examples specific to Python.
Finding slow queries to profile
First things first, before jumping to profile any random query, we need to find a good candidate database query to profile. Slow queries are usually the best ones to start with, but profiling can be used for much more than speeding up slow queries. If there are queries that appear to be behaving erratically, or otherwise returning unexpected data, profiling will help you determine the reason for these abnormal behaviors.
There are many ways to find slow queries. From client-side instrumentation to server-side configuration, through automatic application-level monitoring or through server logs. Each has its pros and cons. Let’s take a look at some of our options:
Database Slow Query Log
Most SQL databases provide a Slow Query Log, a log where the database server registers all queries that exceed a given threshold of execution time. With it enabled and configured, the database will automatically output warning messages and query information for all slow queries.
There is no prescriptive way to access these logs, and most of the usual suspects will work here. You could use grep, for example. But you can also get more sophisticated, and have a simple script that parses the contents of the file and notifies you via Slack.
The Slow Query Log method, while somewhat rudimentary, does have an advantage. With this method you’re getting the information directly from the source of truth, thus eliminating the need for any third-party system or component. The downside? You may experience a small performance hit, originating from the database server having to time every query. Furthermore, keep in mind that enabling this feature does require admin privileges in the database.
Middleware and Application Logs
Other alternatives are application-side middlewares and application-level logging. There are many ready-made solutions for this approach. For example, a popular choice for Python and Django is the django-debug-toolbar. Alternatively, there also exists the option to enable logging directly from the ORM. But even simpler than this is to just add logging to the code interacting directly with the database to print or log the latency of each query. You can even mimic the behavior of the Slow Query Log, and only log the queries exceeding a given threshold of execution time.
Since these are client-side solutions, latencies include networking times. This can be advantageous. Oftentimes a slow query isn’t due to the database taking too long to resolve the given query, but instead, the slowness is due to the size of the payload. With large payloads, the bottleneck may actually be on the data transfer between the database and the application server. This is more likely to occur while using an ORM, as it may default to fetching all the columns from the database table, even when they’re all not required.

APM and Distributed Tracing
Last on this list is APM (Application Performance Management) and Distributed Tracing. While they aren’t one and the same, for the purpose of this article, and the value they provide in profiling database queries, I’ve decided to put them in the same category.
The way most APMs work is through a library or agent that is installed alongside your application and automatically instruments its client libraries, like http, grpc, sql, etc. to monitor and log transactions and queries.
If you are up to speed with the latest advancements in observability and distributed tracing, and already have instrumentation for your application’s database queries, there are open-source distributed trace visualization tools, like Jaeger, that can help you easily identify slow queries.
Let’s see an example of a request containing one such slow database query:

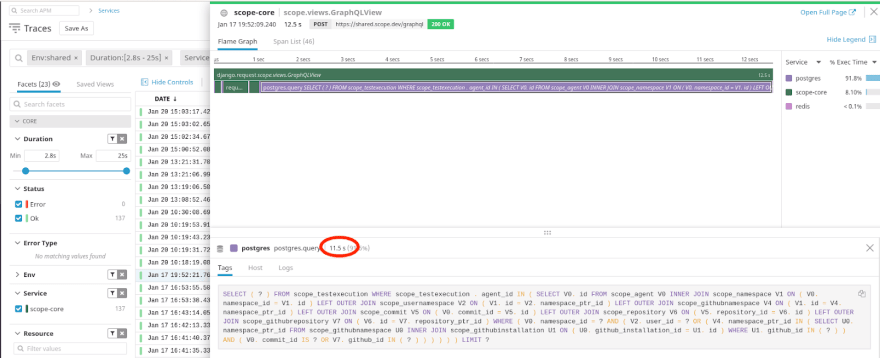
As you can see, with APM or tracing data, and a good service or tool for visualization, finding slow database queries to profile is actually quite easy.
In any case, no matter which method you choose, as long as you have a way to time your queries, you’re likely to find a slow query that is worth optimizing!
Profiling a SQL Query
Now that we’ve identified our slow query, the next step is profiling. Profiling, in the context of a SQL database generally means, explaining our query. The EXPLAIN command outputs details from the query planner, and gives us additional information and visibility to better understand what the database is actually doing to resolve the query.
You can execute this command directly from a command line shell in your database, but if you would rather avoid terminals, most database clients with a GUI also include EXPLAIN capabilities. Following along with the earlier example of our slow query, let’s now profile it. To do this, we simply need to pre-append the original slow query with EXPLAIN ANALYZE.
Attention! It’s important to understand the difference between EXPLAIN and EXPLAIN ANALYZE. While EXPLAIN will only give details about the plan, without executing the query, EXPLAIN ANALYZE actually executes the query, providing you with exact timing information under the current server load. But you need to be very careful with this, particularly on production databases. Not only could it impact performance, you could potentially modify or delete data if you are profiling an UPDATE or DELETE operation.
](https://res.cloudinary.com/practicaldev/image/fetch/s--xDE7qvhC--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2688/1%2AghHXc44RHPN2_ticWCZmFg.png)
After running the EXPLAIN ANALYZE query on a PostgreSQL shell, you’ll get an output similar to this:
](https://res.cloudinary.com/practicaldev/image/fetch/s--z-YudX3Q--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/3398/1%2AnhpoTo7lBBhoAFDPAFGkjQ.png)
As you can see, the output for this is quite cryptic! What does all of this mean? PostgreSQL’s EXPLAIN is very thorough, it really shows us everything the database knows and plans to do with our queries. As such, it is to be expected that we will not understand most things. While explaining all of the output is beyond the scope of this article, we can still learn quite a few things from it.
The first tip is that, if we want to think about the steps the database would follow with our query sequentially, it helps to read from the bottom upwards. This is because the output is like a break-down of operations, so the last ones are actually the first step for each parallelized block of the execution.
Also, if you are obtaining your EXPLAIN output from the shell, I highly recommend using an EXPLAIN visualization tool, I personally like this one. It provides syntax highlighting and table formatting to help with legibility. You can also easily share the report with other teammates! Here’s a link to an example query.
.](https://res.cloudinary.com/practicaldev/image/fetch/s--3NAe-85N--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/3200/0%2AI_VqbN9x3_nAiyiA)
This site is also a great source to learn about what most of the operations on SQL plans are. But for this practical example, we’ll just be taking a look at two operations, Seq Scan and Index Scan:
Seq Scan is a full search on the table with the given conditions. These are usually bad because they will become slower as the data in your tables grow.
Index Scan is using one of the indexes that exist on your table. These are usually better since the database has a shortcut to the rows that match the conditions.
Most often optimizing your queries will be a matter of replacing a Seq Scan that is too big with an Index Scan by creating an index on the columns that are involved in the conditions. Thought you should know that adding indexes to your tables is not always appropriate. When adding a new index we are trading off writing performance for query speed, due to the database having to update the index when writing to the table. So you should try to have the lowest number of indexes that you can afford and only create the ones that you find unavoidable.
As we continue to debug our slow query, we can see in the visualization above that a single step in the plan is the culprit for most of the time spent resolving the query. So we should focus on these lines:
](https://res.cloudinary.com/practicaldev/image/fetch/s--KJYVtWqg--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2876/1%2A__brbXGG2K9yjUx5krZU2Q.png)
This step in the plan is finding rows in the table scope_testexecution with a column agent_id that matches the primary key on the table scope_agent through the index called scope_teste_agent_i_f352da_idx. It is resolving a foreign key from one table to another. Unfortunately, it is already using an index, so that is not the issue for this specific query.
You can check what kind of index is being used on PostgreSQL. To do that we use the command \d+ scope_testexecution, resulting in:
Indexes:
…
“scope_teste_agent_i_f352da_idx” btree (agent_id, fqn)
This is not how we usually index foreign keys. The database is using a compound index on 2 columns, agent_id and fqn and we do not have a single column index on agent_id!
Furthermore, the fqn column is a varchar(1000) with very high cardinality (a lot of different values per agent) and the EXPLAIN is actually telling us that this step involves 83967 heap fetches. On the Index Only Scan operation, PostgreSQL scans through the index but it stills needs access to the table storage. This area in storage where the table is stored is called the heap, so the number of heap fetches is the number of read operations from the table. In summary, the query is requiring a lot of I/O access to fetch these values from the table, and that is probably the cause for low performance.
We could decrease the size of the data that PostgreSQL needs to resolve this condition if we had a single column index on agent_id. Having a dedicated index for each foreign key is the standard set up, usually autogenerated by ORMs or framework tooling, but in this case, it’s missing.
Testing an optimization
Now that we have an idea of what to change, we can experiment and see if the query performs better. It is better to do this on a testing or staging database when possible since it will involve altering our indexes and there’s always the chance we’re wrong, potentially affecting our production database.
It’s likely that you have a mechanism in place to change your database schema; these are usually called database or schema migrations. Schema changes should involve code reviews, as well as be part of a continuous integration process to be tested and validated.
While this isn’t the best way to debug, unfortunately, we cannot test this kind of change on a development machine, since we need data resembling the actual size of the production database. With this in mind, a trick I’ve used to get past this limitation is to make our changes within a transaction itself. PostgreSQL allows transactional changes to indexes and table structures, which comes in handy for our use case:
](https://res.cloudinary.com/practicaldev/image/fetch/s--XuQkJcuz--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2660/1%2AfsUR7FQKwbp4koO6J8GDdw.png)
With this change, we can actually test a different plan for our query without affecting how it currently works for other transactions, and if we were to be wrong, nothing is affected; we can simply undo the index through a quick ROLLBACK!
Let’s try this out. The next step is to profile the query again, and to use our visualizer to see the report and compare to the previous results we obtained:
.](https://res.cloudinary.com/practicaldev/image/fetch/s--oaahwcD1--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/3200/0%2AdkJLzAD6wbzEu05y)
As you can see in the screenshot above, the same query now takes just over a second. Remember it initially took over 10 seconds! Our optimization, creating a separate index for agent_id, has been successful!
You may be curious as to why we did not have the standard index for the foreign key on the agent_id column. It turns out that in previous iterations of our product, the table scope_testexecution was being used on several queries that aggregated results. Because of this, we had more queries with GROUP BY on agent_id, fqn than we did directly accessing it. That index was necessary at the time. Fortunately, things have changed since then and we can now revert back to using the standard index.
Conclusion
Optimization of SQL queries may be daunting at first, but it is fascinating and within every developer’s reach. Hopefully, this post has helped demonstrate that there are easy optimizations you can do today, such as proposing the addition of a missing index.
But even if you’re just getting started with databases, you can already help your team by identifying slow queries and providing the output of EXPLAIN to help debug issues — they will surely appreciate it!
Scope can help you identify slow SQL queries in testing before they ever make it to production!

Testing is a core competency to build great software. But testing has failed to keep up with the fundamental shift in how we build applications. Scope gives engineering teams production-level visibility on every test for every app — spanning mobile, monoliths, and microservices.
Your journey to better applications through better testing starts with Scope.

Top comments (2)
Beautiful analysis. I use django debug toolbar and its actually helpful. What tool can you recommend for profiling mysql queries .
Hello Micheal, I'm glad you liked it!
Mysql EXPLAINs are simpler than Postgres' so they are easier to follow, even without additional tools. But I know that Mysql Workbench has a pretty good Visual Explain, if you are interested:
dev.mysql.com/doc/workbench/en/wb-...