Written by Fernando Mayo

As applications are being broken down into smaller interdependent pieces and shipped at ever faster rates, we need to update our definition of software testing. We need to make sure our testing methods keep pace with how we develop, to ensure we continue shipping reliable and performant software, in a cheap and fast way.
You are always testing
When you think about the “software development lifecycle”, you will probably picture something like this:
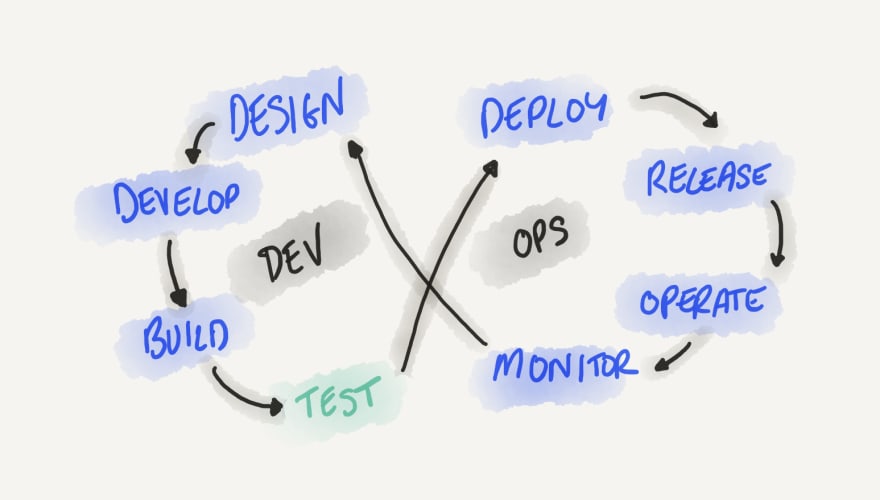
According to traditional wisdom, “testing” is something we do after we finish developing and before we start deploying. But in a world where monolithic applications are being broken down into smaller “services”, this traditional definition of testing no longer holds true. This is due to several factors: increasing complexity (number of deployable artifacts and APIs, independent release schedules, number of network calls, persistent stores, asynchronous communication, multiple programming languages…), higher consumption rates of third-party APIs of staggering variety, frequent deployments thanks to CI/CD pipelines, and a step-change in power when it comes to observability and monitoring tools.
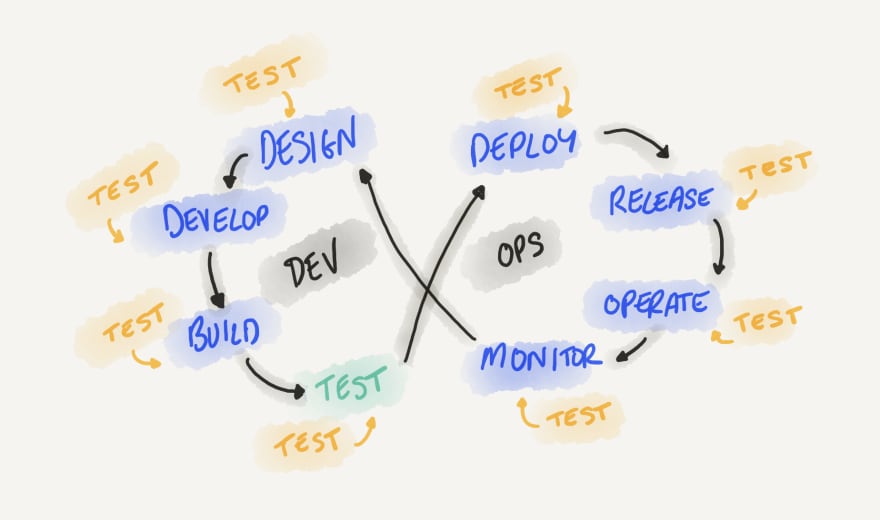
You test when you run a few unit tests before pushing your code, or when CI automatically runs a suite of integration tests every night. But you also test when a product manager uses your staging environment to try out a new feature, or when you gradually send traffic to a new version of your application that was just deployed and you’re continuously monitoring for errors. You also test when you run periodic checks that drive your UI automatically to perform a synthetic transaction on your production instance. And yes, when your customers are using your application, they are helping you test it as well.
What do we test for?
At a bare minimum, any service owner would want to ensure a certain level of quality of their service regarding these aspects:
Correctness: does it do what I want it to do without defects?
Performance: does it respond to its consumers with an acceptable delay?
Robustness: does it degrade gracefully when dependencies are unavailable?
There are many other non-functional aspects of your application you might want to test for depending on your application’s specific requirements (e.g. security, usability, accessibility). Any breach of expectations in any of these dimensions becomes something you want to be able to detect, troubleshoot, and fix as soon as possible, with the lowest possible effort, and have a way to prevent it from happening again in the future.
Correctness is the aspect we typically associate testing with. We immediately think of unit and integration test suites that ensure the application returns an expected response to a set of predefined inputs. There are also other very useful approaches to testing correctness, like property-based testing, fuzz testing, and mutation testing, that can help us detect a wider range of defects in an automated way. But we should not stop there.
Even with the most comprehensive test suite in the world, a user is still going to find a defect when it goes live. That’s why we should extend correctness testing to production as well, with techniques like canary deployments and feature flags. As we will discuss later, an efficient testing strategy will make use of multiple techniques across all environments in order to proactively prevent issues.
Performance is a very important quality aspect of any software application, yet we don’t actively test for it as much as we should, as it becomes a complex endeavor to figure out which combination of data, access patterns, and environment configuration will be the one most representative of “production”, which is what will eventually dictate the performance of our application as seen by the end user.
Benchmark testing is a good and cheap way to get early feedback about any performance regressions on part of our code, and we should definitely use it as part of our strategy. But again, there’s more we can do to test the performance of our application.
This is the perfect example of how expanding our definition of testing to the entire software lifecycle can help us increase software quality with less effort. Even if we invested in having pre-production load and stress tests to give us an idea of the throughput of our application and making sure we don’t introduce regressions, there’s nothing closer to production than production itself. That’s why a good performance testing strategy should also include adding the required instrumentation and tools to be able to detect and debug performance issues directly in production.
Robustness is very often overlooked, as we are biased towards testing for the “happy path”. This wasn’t much of an issue in the world of monoliths — failure modes were few and mostly well known. But in the brave new world of microservices, the number of ways our application can fail has exploded. This is also the aspect of our application that, if not properly and thoroughly tested, has the most direct impact on the end user experience.
Making sure our services tolerate issues and degrade gracefully when dependencies fail is very important, and we should make sure we test for that. In this case, testing emphasis should be put on pre-production testing: failure handling code, by its nature, will not be exercised very frequently in production (if things go well), so having automated tests that programmatically simulate failure is essential.
Investing in failure injection and chaos engineering in production is another option if we consider that there are possible failures that we cannot reproduce in a controlled environment and we need to resort to testing them directly in production.
The modern testing toolbox
Software engineers are gradually becoming service owners, where they are responsible for a specific part of an application all the way from development to production. This includes testing, but not just in the traditional sense — it starts with unit testing their code, and extends to adding telemetry to effectively test in production.
Just as the DevOps movement highlighted the importance of developers to understand and be involved in the deployment and ongoing monitoring of the service they own, it is also important for them to understand the different testing techniques available to them, and use them appropriately to increase the reliability of their application at the lowest possible cost.
As we have seen earlier, some of these new techniques enable safely testing in production, if done right. For example, canary deployments allow for testing an application in production for a small percentage of real user data. For it to work, the application must be developed in a way to support this kind of testing, for example, by adding appropriate metrics to detect when there is an issue, logs and/or traces to troubleshoot what went wrong in the case the test fails, and by making sure there are no side effects on any datastore should the deployment need to be rolled back. While there may be cases where these testing techniques can help us efficiently test, they are complex to setup and execute, and one must understand all the prerequisites and implications of performing such tests.
Including tools for testing in production in your toolbox will allow you to use it when it’s the most efficient (cheapest) for the feature or bug fix you want to test, since the cost of synthetically testing it earlier in the cycle might actually be more expensive (e.g. data requirements, or dependencies that cannot be mocked or replicated).
The value of testing
In order to make sure our application is correct, performant, and robust, we have to make sure we take a holistic approach to testing and explore all the different testing options at our disposal. But how do we decide which type of test to use? It comes down to reducing costs.
We also know that, at some point, our application will not perform as expected, no matter how much we test. There are simply way too many factors involved that we cannot anticipate: too many possible user inputs, too many states in which your application can find itself, too many dependencies that are outside of your control. So why testing if we cannot avoid failure completely? When should we stop? It comes down to managing risk.
Testing is about reducing the risk of your application performing unexpectedly, at the lowest possible cost.
The costs associated with catching issues in production
Let’s consider the cost of addressing issues in production. It comes in different forms:
Detection cost:
How and when do I get notified if it is not working as intended?
Does the user need to notify us of the problem?
What is the time delay between the issue being introduced in the application, and someone in the organization being alerted?
Do we have automated alerting, or do we have to actively monitor a dashboard?
Does the alerting work properly?
Do we have the right metrics?
How do we detect non-obvious issues that aren’t accompanied by a spike in latency or an increased error rate?
Troubleshooting cost:
Once I know there is an issue, how do I know what caused it?
Did I add the appropriate instrumentation (metrics, logs, traces, exceptions) to debug the issue?
Do the metrics have the right tags and resolution to aid with debugging?
Do we have the logs, or have they been deleted because of retention policies?
Have the relevant traces for troubleshooting been sampled?
What are the costs associated with processing and storing this information?
Do I have to reproduce the issue in another environment to find out more about it? How much time will that take?
Do I know who has the knowledge to debug it?
When was it introduced?
Fixing cost:
Who is the team responsible for fixing this?
Do they have the bandwidth to address the issue?
Can I rollback safely to temporarily fix the issue, or am I forced to come up with a hotfix ASAP and roll forward?
Did the issue affect any datastores or other services that now need cleaning up?
How long will the fix take to propagate through all affected environments?
Verification cost:
Can I automate verifying the fix, or does it need manual verification?
How much time and resources does verifying the fix take?
Do I have to rely on an affected user for verification?
Can I verify all possible permutations of the issue?
Can I verify the fix without side effects on the production instance?
User impact cost:
Are users impacted by the issue?
If they are, how many, and for how long?
Is the business losing money?
Is the company’s brand or reputation being negatively impacted?
How many support tickets have resulted from this issue?
What is the cost of processing and replying to these support tickets?
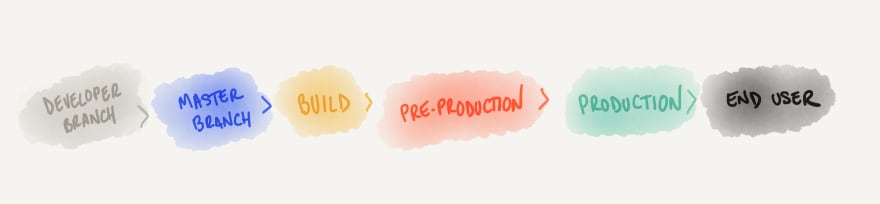
As issues approach the end user of the application, the more expensive it becomes to address them. A bug detected with a unit test that a developer ran locally while working on a feature branch, for example, is the cheapest to address: the bug has been detected immediately after the developer introduced it (detection cost); easy to debug as it pinpoints exactly where the problem is, along with rich debugging information (troubleshooting cost); the developer just introduced the issue, so they already have the proper context to quickly fix the problem (fixing cost), can immediately verify the fix by re-running the test (verification cost), and the issue has resulted in zero user impact.
On the other hand, an issue that comes up weeks after a new version has been released to users is arguably the most expensive one. Costs for detection, troubleshooting, fixing, verification, and user impact will all be at their highest.
Note that I have separated production from end user. By using canary deployments or feature flags, the issue can reach production, while we control which end users are exposed if any at all. In this case, an issue detected after deployment to production (the new code is running in production infrastructure) but before releasing it to all users (no users or only a small fraction of users are being served by the new code), helps to mitigate the user impact cost, but all of the other costs still apply.
Also, we should note that engineering teams that are constantly interrupted to address issues, especially ones that have been detected late in the cycle, incur variable costs of stress, which can ultimately lead to burnout. Regardless of whether engineers are on-call or not for the services they own, adding unplanned work to debug and fix production issues, which requires context switching from their already planned and full sprints, has a negative effect that becomes readily apparent over time.
Testing can be cheap, but it’s never free
Addressing issues in production is expensive. Ideally, we want to utilize tests to catch them as cheaply and as early in the cycle as possible. But while tests can be cheap, they’re never free. Some of the associated costs include:
Creation cost: how much time and effort is needed to write the test, and make the system testable?
Execution cost: how long does it take to actually run the test to get feedback? How many computing resources does it consume?
Maintenance cost: if I change my application (refactoring, new feature, etc.), how much time and effort does it take to update the test accordingly?
Any software development team must be on top of their testing costs and actively manage them, like any other aspect of the code they write. Reducing execution cost can be done in many ways: removing overlapping tests, making sure tests run quickly (by doing I/O only if absolutely necessary, and using mocks where possible), running only tests that cover the code that has changed (like go test, jest or bazel do), or by “failing fast” and getting feedback before all tests finish running.
Flaky tests (defined as tests that both pass and fail with the same codebase) are especially costly, as they don’t just introduce noise and distraction, and the need for retries — they decrease developer confidence in the system, and will either slow down the workflow (the build needs to be green to continue), or increase risk (we know the tests failing are flaky — so let’s continue anyway). Flakiness should be measured and reduced to a minimum. Some tests will need to perform I/O operations and will inherently have some degree of flakiness — in these cases, adding retries to the test or making the I/O operations more resilient to transient failures, can be the most efficient way to tackle them, as rewriting them to completely remove flakiness might be much more expensive, or even impossible. Techniques like mocking dependencies by recording and replaying HTTP traffic (a kind of snapshot testing but for integration tests), can also help reduce flakiness and speed up testing.
Strategies to reduce testing cost
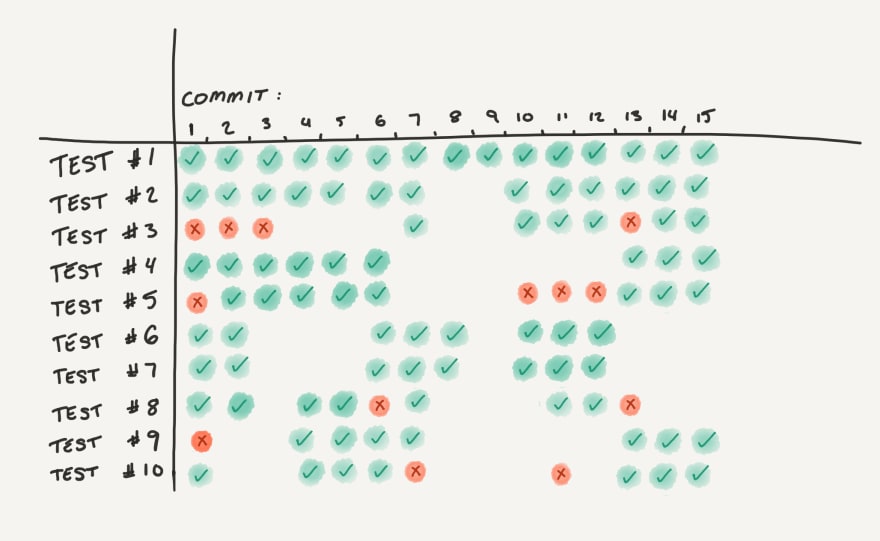
The execution cost of tests can be reduced by having an effective strategy when running them. For example, by running only fast unit and integration tests locally when working on a bug fix or new feature, we reduce the time to feedback from the developer. Then, after pushing the code to the central repository, CI can kick off a round of more in-depth integration tests. The master branch can have a nightly run of longer and more expensive system or end-to-end tests, etc.
The idea is to balance execution cost with the time to receive feedback; for example, by reducing the execution cost, we increase the troubleshooting/verification cost: by running tests less often, we will create “gaps” in the history of test executions that, in the case of a broken test, will introduce a larger search space for the actual culprit of the failure; the less frequent the test executions, the wider the gaps in history, as depicted in the above graph.
Because testing is all about reducing risk, one must balance risk appetite with the cost of testing. Even within the same application, not all parts of the application will need the same amount of testing. For every scenario you want to test (e.g. a new feature, a bug fix, or a new dependency failure handler), try to think about how you can test it at the lowest cost possible. Would a simple unit test be sufficient? Do I need to test it against a real instance of a dependency? Or is the most efficient way to test it to add proper instrumentation and alerting, and do a canary deployment in production?
This is something that must be evaluated by the developer and potentially the greater team, on a case by case basis. It highlights the importance of the developer being familiar with the entire range of testing methodologies available to them in order to choose the most cost-effective one.
How do we test what we don’t know can fail?
As we have seen, testing allows us to detect, debug and fix issues in a cheaper manner than waiting for them to be surfaced by a user. But, how do we test for things that we are not aware of that can fail? How do we test for the unknown unknowns?
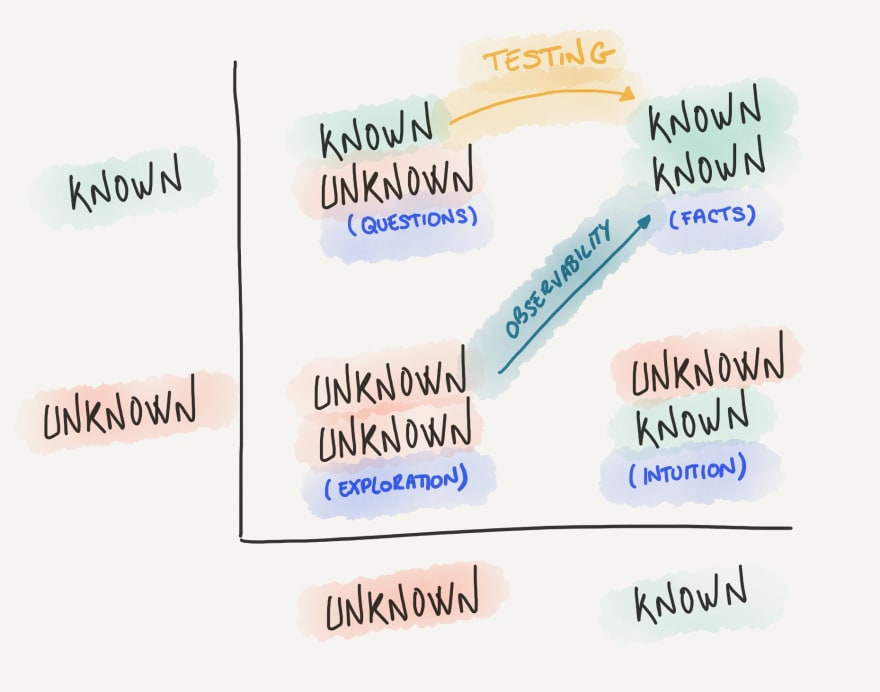
Our objective should be to bring as much information as possible to the known knowns quadrant, which are the facts about our service. When we change something on our application, previous known knowns are invalidated. Testing helps us move from known unknowns to known knowns, i.e. we know the questions to ask, and by executing the test, we’ll get the answer. We can do this in an automatic, quick, and very efficient way. For example, “does this function return what I expect when I provide these specific arguments?”, “does my service return a 400 when the user sends an invalid payload?” or “does the UI show an error message when a user tries to log in with an invalid password?”.
Unknown unknowns are issues that appear that we didn’t anticipate because we didn’t even know they could happen. We can’t test for them, as by definition, we don’t know what can actually fail until it does. For this case, good instrumentation and tooling in production will allow us to debug (and sometimes detect) new issues we couldn’t anticipate, but it comes at a high cost. If the root cause finally ends up being one that could come up in the future (and not just a transitory operational issue), it’s always a good idea to write the cheapest test possible for it, to avoid regressions, and bring it to the known unknowns quadrant for future versions of the software, which will save us precious engineering time.
How much testing is enough?

We know testing will never be able to tell us that our application is 100% reliable, as testing is about managing risk. That’s why traditional testing coverage is not a good measure of quality or a target an engineering team should focus on. As we have seen, unit testing is just one of the many techniques we should be using to test our services — and code coverage is based on that. It can only tell us how extensive our unit tests are, but not if we are building a high-quality service.
What can we use instead? We instinctively know that if we don’t test our application, its quality won’t meet our user’s standards. We also know that we could just keep investing in testing forever and we will never reach perfection. There is a compromise somewhere in the middle, but how to measure it?
The performance (latency) and robustness (availability) aspects of your application should be already being measured and monitored, with a corresponding SLO. SLOs provide a target you should strive for in these dimensions. Testing should support hitting those goals, which will depend on the application requirements. Critical services will have very aggressive SLOs, thus requiring a high level of investment in testing, and non-critical services will have more relaxed requirements. Only by directly linking the testing budget to objective targets like SLOs will provide the right incentives for teams to decide how much risk they want to remove.
The correctness aspect is harder to measure directly, but equally important. You application might be extremely reliable and performant, yet your users might be unhappy because your application is just not doing what it’s supposed to do. A pragmatic approach to continuously measure correctness could be to have a target on the rate of new high priority defects in production. Just like an availability SLO, that number can be a good proxy on whether defects are slipping through to end users too often, and guide the team to adjust their testing efforts accordingly.
Conclusion
Testing has always helped us build applications that are more maintainable, debuggable, reliable and performant, and allowed us to ship faster and with more confidence. But as applications have become more and more complex and dynamic, new types of failure modes have been introduced which are increasingly more difficult to anticipate and troubleshoot. In order to be able to proactively and efficiently detect, debug and fix them, we should review and adapt how we use traditional testing techniques and embrace new ones that apply to all stages of the development lifecycle.
Only then can testing return to be the invaluable ally it once was in delivering high quality software.

Testing is a core competency to build great software. But testing has failed to keep up with the fundamental shift in how we build applications. Scope gives engineering teams production-level visibility on every test for every app — spanning mobile, monoliths, and microservices.
Your journey to better engineering through better testing starts with Scope.




Top comments (0)