This post is a trascription of FTA Live session, AI at Scale at 2023 June 29th. Full slide deck is available at here.
This session is about AI at Scale, specifically Foundation models and related Azure services. This session is designated as an introductory content for data scientists, machine leanring engineers and prompt engineers.

First, I will introduce the concepts of Foundation models, including LLMs, and provide an overview of Azure Machine Learning and Azure OpenAI Service.
Next, I will explain how to utilize Foundation models for model training and inference on Azure, as well as discuss the architecture design for an Enterprise Search scenario.
1. Introduction to Foundation models

What are Foundation models? Over the past decade, Artificial Intelligence (AI) has been revolutionizing various industries, from manufacturing and retail to finance and healthcare. In recent years, AI has made significant progress, primarily due to the development of large-scale Foundation models. These models are trained on massive amounts of data and can be adapted to perform a wide variety of tasks, including natural language processing, computer vision, and generative AI tasks for creating new content.
However, it is crucial to pay attention to the potential issues with Foundation models, as they can fail unexpectedly, harbor biases, and may not be fully understood.

What makes Foundation models? I have identified three key components: Transformers, Scale, and In-context learning. Let's examine each of these components one by one.

The Transformer architecture and its scalability have unlocked the potential of Foundation models. Invented just over five years ago, the Transformer architecture has been dominating the field of NLP and has since expanded its reach beyond NLP as well. This architecture is expressive, universal, and highly scalable, making it easy to parallelize for improved performance.

Many people associate scale with the size of the model. However, scale is actually about the amount of compute resources used to train the model and the increasing volume of data utilized for training.
One of the most intriguing properties that has emerged from scaling over the past year is the concept of emerging capabilities. Certain capabilities are not demonstrated at all when the model is small, but they suddenly and unpredictably appear once the model reaches a critical size. This phenomenon highlights the importance of scale in the development of Foundation models.
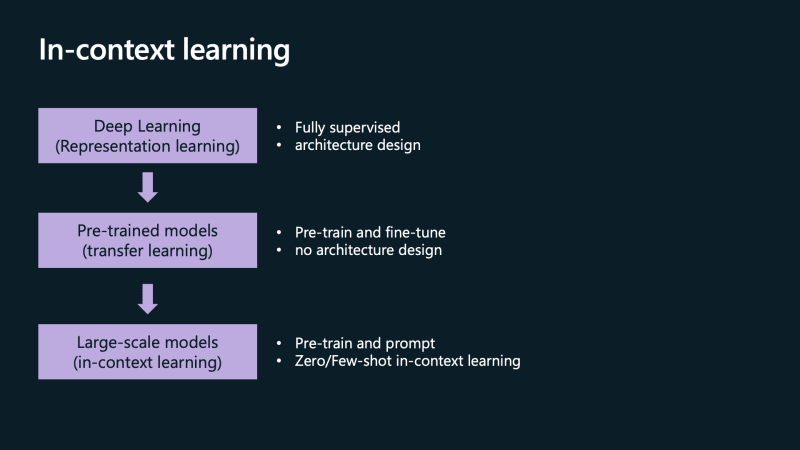
One of the most exciting emerging capabilities of language models recently is their ability to perform in-context learning, introducing a new paradigm for utilizing these models.
If we look back at how we have been practicing machine learning with deep learning in general, we would typically start by choosing an architecture, such as a Transformer, or before that, an RNN or CNN. Then, we would fully supervise the training of the model using a large amount of labeled data. With the advent of pre-trained models, instead of training models from scratch, we now start with a pre-trained model and fine-tune it using labeled data for the task at hand.
However, in-context learning enables us to use the models "out of the box." We can use the pre-trained model along with a prompt to learn and perform a new task without any additional training. This can be done in a zero-shot learning scenario, where we provide no examples but only instructions or descriptions of the task, or in a few-shot setting, where we provide just a small number of examples to the model.

In-context learning and prompts play a significant role, as they are changing the way we apply models to new tasks. The ability to apply models to new tasks "out of the box" without collecting additional data or conducting further training is an incredible capability that broadens the range of tasks that can be addressed by these models.
It also reduces the amount of effort required to build models for specific tasks. Moreover, the performance achieved by providing just a few examples is remarkable, with the tasks being adapted to the models rather than the other way around. This approach also allows humans to interact with models using their natural form of communication—natural language. It blurs the line between machine learning users and developers, as now anyone can simply prompt and describe different tasks for Foundation models like large language models (LLMs) to perform without requiring any training or development expertise. This accessibility empowers a wider audience to benefit from these powerful AI tools.
Part2 will be published soon.

Top comments (0)