You can also read this post on my blog: blog.kamilbugno.com
Would you like to revise your knowledge before the exam? During preparation to AI-102 I made lots of notes, and I decided to share them with you. This article doesn't cover all topics required for AI-102, but I believe it can be a great resource to structure your knowledge. Let's start go deeper into the AI-102 world!
What are Cognitive Services?
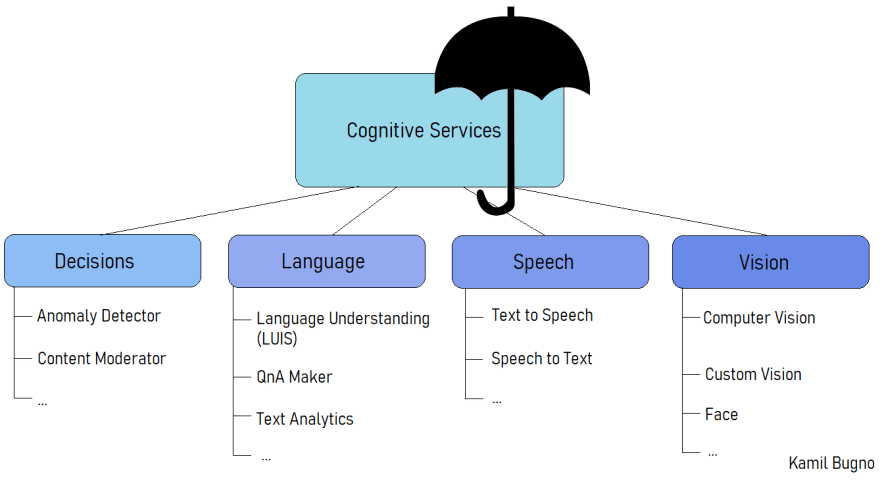
It is sometimes called an 'umbrella' service because it contains other AI services such as Face, LUIS, Speech to Text, etc. All the contained services can be used independently - you can search them in Azure Marketplace and add them to your solution. So why do we need Cognitive Services? It is more comfortable to use it when we know that we need several different services related to AI and thanks to Cognitive Services, we don't have to add each of the services separately. There is also a difference in a free tier: Cognitive Services don't have free tier options. On the contrary, other AI services such as Computer Vision and Face provide you with free tier options.
Can I use Cognitive Services as a container?
Yes, you can. Thanks to it, you can use AI functionalities on-premises. There are two vital facts related to it: not all AI services support containerization (for example, Face), and you must send metering data to Azure because of the billing process (Azure needs to know how you use its services to be able to prepare a bill for you).
What are the benefits of having Cognitive Services as a container?
You have the possibility of controlling your data. By using containers, you don't have to send your data to the cloud to use AI services - all the work is done on-premises. What is more, you can use the advantages of containers: portable application architecture and scalability achieved by using orchestration tools such as Kubernetes.
What is Computer Vision API?
It enables you to analyse content in both images and video. You can use either REST API or client library (for C#, Python, Java, etc.) There are several crucial functions, that this API provides - below there are methods that you can use in Python:
-
computervision_client.describe_image- generate a human-readable sentence that describes the image, -
computervision_client.tag_image- returns tags based on recognizable objects, living beings, scenery, and actions, -
computervision_client.analyze_image- returns object that contains several properties:-
brands.name- detects corporate brands and logos in the image, -
adult.is_adult_content- returns true if the image show nudity and sexual acts, -
adult.is_racy_content- returns true of the image is sexually suggestive.
-
-
computervision_client.analyze_image_by_domain("celebrities", image_url)- recognizes celebrities, -
computervision_client.analyze_image_by_domain("landmarks", image_url)- detects landmarks in the image. -
computervision_client.generate_thumbnail(width, height, image_url)- creates reduced-size representation of an image. It can change the aspect ratio and remove distracting elements from the image. -
computervision_client.read(image_text_url, raw=True)uses Read API to return (in an async way) object that containsresult.analyze_result.read_results- it provides you with the extracted printed or handwritten text from an image. Read API supports files in JPEG, PNG, BMP, PDF, and TIFF formats.
What is Form Recognizer?
Form Recognizer is a part of Computer Vision, and you can use it to extract key-value pairs and table data from form documents. It contains several methods:
-
form_recognizer_client.begin_recognize_content_from_url(form_url)- it returns a collection of objects: one for each page in the submitted document. You can access cells and texts from the returned objects, -
form_recognizer_client.begin_recognize_receipts_from_url(receipt_url)- it extracts common fields from US receipts by using a pre-trained receipt model, -
form_recognizer_client.begin_recognize_business_cards_from_url(business_cards_url)- it extracts common fields from English business cards by using a pre-trained model.
How can I detect faces on images?
You have two possibilities: you can run Computer Vision method: computervision_client.analyze_image(image_url, ["faces"]) or you can use Face API. It is important to know the difference between them. Computer Vision's analyze_image method only provides a subset of the Face service functionality, so you are not able to use more advanced solutions with it.
What is Face API?
It provides you with AI algorithms related to human faces. This service contains five main functionality:
- face detection - it simply detects faces and returns the rectangle coordinates of their locations. You can use
face_client.face.detect_with_urlmethod in Python to fulfil the detection. - face verification - it helps to answer the following question: "Are these two images the same person?". You can use
face_client.face.verify_face_to_facefor it. - face identification - it helps to answer the following question: "Can this detected face be matched to any enrolled face in a database?". You can use
face_client.face.identifymethod for identification, - find similar faces - let's imagine that we have a target face and a set of candidate faces. The goal of this feature is to find a smaller set of faces (from candidate faces) that look like the target face. You can use
face_client.face.find_similarmethod for this, - face grouping - it divides faces into several groups based on similarity. From the code perspective it is a bit more complicated than the methods above. Firstly, you have to create group (
face_client.person_group.create), secondly, you need to define one or more person in that group (face_client.person_group_person.create), later you should add images of the newly created person (face_client.person_group_person.add_face_from_stream), penultimate step is to train the model (face_client.person_group.train) and finally you can identify the person from the group (face_client.face.identify).
What is Custom Vision?
The main goal of Custom Vision is to create custom image identifiers. You can train the model to serve your individual needs. Let's imagine that you want to have a service that distinguish cat from dog. You upload several images of cats with 'cat' labels and do the same for dog. After training, you are able to upload a new image, that the model hasn't seen yet, and you will receive information if the image shows cat or dog with the great accuracy.
It is also good to know that Custom Vision has two main features:

- image classification - it applies labels to an image,
- object detection - it not only add labels, but it also returns the coordinates of the labelled object location. It is important to remember that you have to add labels and coordinates for training data on your own.
How can I use Custom Vision?
You have three options:
- online site (
https://www.customvision.ai/), - SDK that support C#, Python, etc.,
- REST API.
Each option provides you with the same type of AI functionality.
What is Video Indexer?
It is an AI service that provides you with the possibility of extracting information from video. It is focus on both visual and audio aspect of the video.

The functionality is really impressive and includes:
- face detection - it detects faces that are visible on the video,
- celebrity identification,
- visual text recognition - it extracts text from the video frame,
- visual content moderation - it informs you if the adult content is displayed on the video,
- scene segmentation - it determines when a scene is changed on the video,
- rolling credits - it identifies when rolling credits are displayed,
- audio transcription,
- noise reduction,
- speaker enumeration - it can understand which speaker spoke which words and when. It is good to know that only sixteen different speakers can be detected in a single audio-file.
- emotion detection - identifies emotions based on speech (joy, sadness, anger, ect.),
- keywords extraction - it extracts keywords from speech and visual text.
How can I use Video Indexer?
You have two options: online site (https://www.videoindexer.ai) and API.
Can I customise Video Indexer?
Yes, to some extend you can. For example, if some faces are detected on your video and they are not celebrities they will be left unnamed. You can describe unrecognized faces, and as a result, your newly labelled faces will be saved in the model. So, from that point Video Indexer will be able to recognize these faces. Similar case is for brands. You can customize brands model to exclude certain brands from being detected or include brands that should be part of your model but weren't detected. What is more, you can also customize language model for example to be able to know that you don't want to translate 'Kubernetes' word, because it is from a technical domain.
What is Text Analytics API?
Text Analytics API a part of Language APIs and it is focused on Natural Language Processing. The functionalities that Text Analytics provides are:
- sentiment analysis - it can determine if the document/sentence is positive, negative, or neutral,
- key phrase extraction - it returns a list of key phrases,
- language detection - you can send a text in some language and the response will contain the name of used language and the confidence score,
- named entity recognition - it can recognize some entities in the text (for example people, places, organizations, etc.).
How can I use Text Analytics API?
You can use either SDKs (for C#, Python, etc.) or REST API. For example, in C# there is a method textAnalyticsClient.AnalyzeSentiment(document) for sentiment analysis or you can use REST API - /text/analytics/v3.0/sentiment endpoint will return the same data as the SDK's method.
How many languages are supported for Text Analytics?
Each functionality has a separate supported languages list. For example, key phrase extraction supports both English and Polish (and many more), but as for sentiment analytics Polish is not supported.
What is the Speech service?
As a name suggests, it is focused on the speech. These are the provided functionalities:
- Speech-to-Text,
- Text-to-Speech,
- Speech-to-Speech translation,
- Speech-to-Text translation.
It is important that both Speech-to-Speech and Speech-to-Text translation are supported only for SDK - there is no REST API for them.
Can I customize Speech service?
Yes, you can create a custom model for Speech-to-Text functionality by using Custom Speech service, and for Text-to-Speech by using Custom Voice service.
What is Language Understanding (LUIS)?
It is a conversational AI service. You can use it to understand users needs. Let's image a chatbot or voice assistant that should increase the productivity of the employees. When the user writes/says 'I want to send email to Tom', LUIS will use trained model to predict the meaning of user input - as a result, SendEmail method will be executed with EmailTo property set to Tom.
How can I use LUIS?
You have three options:
- dedicated website (
https://www.luis.ai/); - REST API;
- SDKs (C#, Python, etc. are supported).
What are utterances?
Utterances are the user input. In the above example, we use the following text 'I want to send email to Tom' - it is the utterance.
What is intent?
Intent is an action that the user wants to perform. In the above example 'SendEmail' is the intent. LUIS determines intent based on user input (utterances).
What is entity in LUIS?
Some actions can require attributes. LUIS is able to recognize the entities from utterances. For example, {"EmailTo": "Tom"} is an entity retrieved from the sentence 'I want to send email to Tom'.
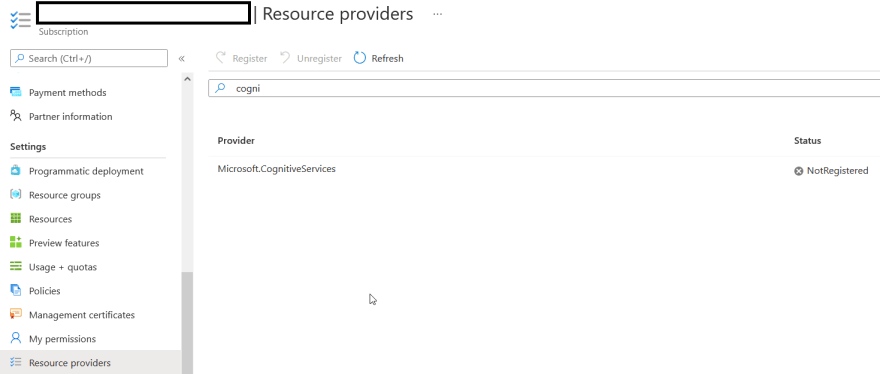
What should I do to start using LUIS?
- Add Microsoft.CognitiveServices to your Resource providers:
- Create Cognitive Services account:

- Create app:
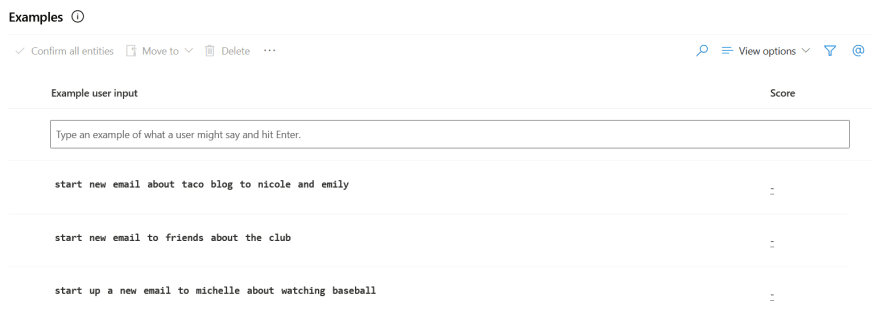
- Build your language models by specifying intents and entities - you can use prebuild data. For example, when you select Email.SendEmail intend then a lot of utterances is automatically added:
 Entities can also be predefined:
Entities can also be predefined:
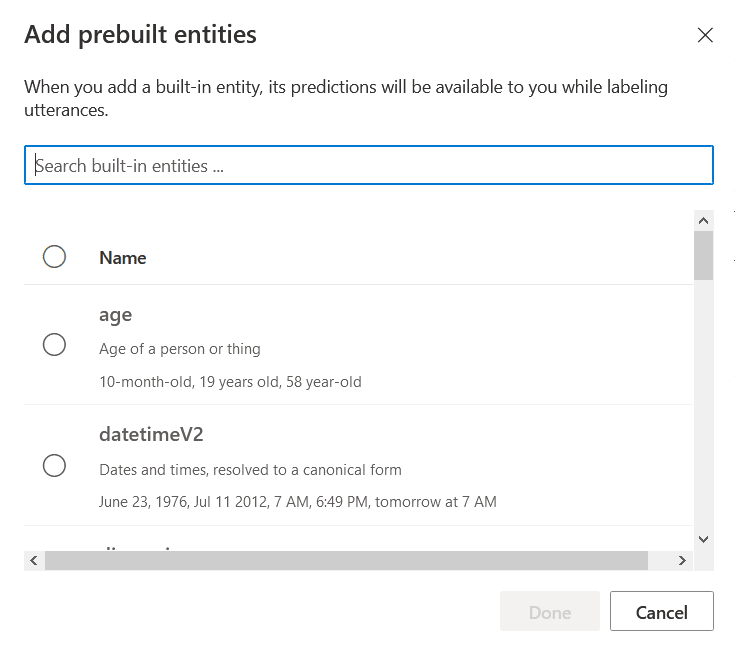
- Train the model:

- Publish to endpoint;
- Test from endpoint.
What is Azure Cognitive Search Service?
As a name suggests, this service enable you to use search functionality on your data. For example, you can search all data that are stored Azure SQL Database or Azure Cosmos DB.
What is the difference between index and indexer?
Indexer can crawl your data source and create an index. The index is a collection of documents that can be searched. Index can contains additional data that specify how the search functionality is used on it, such as: sortable (true | false), filterable (true | false), searchable (true | false), etc.
How can I create an indexer?
All indexers are required to contain:
- name - the name of the indexer;
- dataSourceName - you can choose from:
- SQL Managed Instance
- SQL Server on Azure Virtual Machines
- Azure SQL Database
- Azure Table Storage
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- targetIndexName - the name of your index.
From the technical point of view, you can create indexer using Azure portal, REST API, SDKs (.NET, Java, Python and JavaScript are supported).
How can I run indexers?
You can run indexers after the creation, so it will retrieve desired data from the source and put it to index. As a result, they will be available for the search functionality. But what about the situation when data is changing all the time, and you want to search up-to-date data? In that case, you can use a scheduler for it and specify when the indexer should be run. For example, you can define that the indexer will be run every hour.
How can I support autocomplete and autosuggest in my Search Service?
You need to specify the suggesters property in the index definition. This field requires three pieces of data:
- name - name of your suggester,
- sourceFields - it can contain one or more fields that will be used as a data source for the autocomplete or autosuggest options,
- searchMode - only one is available now -
analyzingInfixMatching. It checks the beginning of a given term.
It is important that only one suggester can be defined per index.
Why should I support synonyms in my Search Service?
It makes your search functionality richer. For example, when user tries to search for USA, it will be great if the retrieved results contains also data for United States, United States of America and even USofA. An index definition contains synonymMaps property and in that place you can specify the synonyms.
What is QnA Maker?
QnA Maker enables you to create conversational app with Question and Answer functionality. The user provides the question (in text or speach) and the QnA Maker responds with the best suited answer. You can import data (that is called knowledge base) from documents (PDFs, DOCXs) and websites (URLs) where FAQ section is available.
What is a multi-turn conversation?

Multi-turn is a follow-up prompt that help to specify what the user wants to achieve. For example, when you visit Adobe page, you can see that the chatbot uses multi-turn to determine whether the user is satisfied with the answer. Vodafone uses it to check if the user is their existing customer or a new client. Scandinavian Airlines provides multi-turn conversation to specify the main topic of the discussion. As you can see, additional follow-up prompts can help to create a satisfying bot conversation.
What it chit-chat functionality of QnA Maker?
When you create your knowledge base, you have an option for adding chit-chat. Chit-chat makes your bot more human-friendly and engaging. 'How are you?', 'What is your name?', 'How old are you?' - these are the examples of chit-chat questions. When you want to add these functionality to your QnA Maker, you have several personalities to choose from:
- professional,
- friendly,
- witty,
- caring,
- enthusiastic.
What is the difference? For example, when you ask 'When is your birthday?' professional personality will respond 'Age doesn't really apply to me' and friendly with 'I don't really have an age'.
What is active learning for QnA Maker?
As a name suggests, you can enable QnA Maker to learn based on user inputs. Thanks to it, you can add new questions (that are suggested by the QnA Maker) to your knowledge base. You have to review and accept or reject QnA Maker suggestions in the portal - there is no other way of managing suggestions.
How can I build my bot?
You have three main options:
- Bot Framework SDK that supports C#, JS, Python and Java,
- BF (Bot Framework) Command Line Interface,
- Bot Framework Composer - it is an IDE for developing bots.
How can I debug my bot using Bot Framework SDK?
There is Bot Framework Emulator that provide you with the functionality of testing and debugging bots. It is a desktop application for Windows, OS X and Linux.
What are Adaptive Cards?

Adaptive Cards can enrich communication by using text, graphics, and buttons to your bot conversation. You can create Adaptive Cards in the Designer (https://adaptivecards.io/designer/) or by Bot Framework SDK.
What is a skill?

In Bot Framework a skill is a bot that performs tasks for another bot. Thanks to it, you can extend your existing bot by consuming another skill (bot). It is good to know that a main skill consumer that interact with the user is called a root bot.
Which Cognitive Services can I integrate into my bot?
It is common to integrate QnA Maker service, LUIS service, and Speech service into the bot.


Top comments (0)