
When integrating Apache Kafka into your company’s infrastructure and starting your first Apache Kafka project, you will stumble upon certain challenges that will slow you down but can be easily avoided.
This article covers the main reasons, why Apache Kafka application and data integration projects fail and how you can prevent this from happening by using a data-centric monitoring solution and Kafka UI from the very beginning.
Before getting into what a data-centric Kafka monitoring solution looks like, let me first describe the tasks and issues, I have come accross in projects with Apache Kafka. If you have already implemented a solution with Apache Kafka, many of them might be very familiar to you.
A typical Apache Kafka project
These are the common tasks that you will find in any Apache Kafka project:
Data modelling (understanding data models and business requirements)
Expose new data objects for other services (ingest data & data validation)
Consume data objects from existing or parallel developed applications
Enrich data (consume existing data objects and create new ones)
Sink: integrate data from Apache Kafka into standard software (e.g. SAP, …)
The pitfalls
The common challenges can essentially be broken down to:
- transparency
- communication and collaboration
- control
Transparency
When consuming data from other services, developers have a hard time understanding how the actual data objects and especially the different characteristics of the data objects look like as documentation is often outdated or not available. This leads to a tedious trial and error process, which slows down the developers and results in less time being spent on the actual work. This problem is even more relevant when several applications are developed at the same time as changes to data models occure more often during the process, which leads us to the next problem: communication and collaboration.
Communication and collaboration
Why do data models change that often during development? The main reason for this is very simple: lack of communication and collaboration. When designing business objects, feedback loops with business departments are necessary but also require a lot of time and effort from both sides. Because of the missing transparency, business departments and business analysts alike are not able to quickly analyse and validate the data objects that are being produced by a new application on their own. As a former software architect I can tell that bringing together the business view and the technical view is something, you spend most of your time on. Enabling your stakeholders to access and give them control over relevant data quickly leads to a better understanding and communication.
Control
Thus, developers, your testing team, business departments and operations need to be in control of the relevant data. If it takes your contact person more than half an hour to give you a copy of relevant data, you will not be asking for this very often. This leads to more guessing instead of informed decision making during application development and day 2 operations.
As Apache Kafka is all about data, these problems multiply.
Take care of these problems before they evolve and possibly risk your project’s success.
The following section is about the approach we took at Xeotek and introduces you to our data-centric Kafka monitoring solution “KaDeck”.
Available monitoring solutions
At Xeotek we always recommend having a monitoring solution on the infrastructure level for your infrastructure operations. This is crucial for discovering service outages at a technical level and to get a better understanding and overview of your docker containers. Gartner has published a comprehensive list of these tools with reviews.
Having said this, a monitoring solution on the technical level is not sufficient. The challenges we have identified above require a much more data-centric approach.
Currently there are only a few tools available for monitoring Apache Kafka data. But the few tools available for directly viewing Apache Kafka data, so called Kafka UIs or topic browsers, are not satisfactorily addressing the challenges we have identified as they deliver an experience which makes it even for a developer not so trivial to get a better visibility of the data objects.
Our Approach
At Xeotek we wanted to comprehensively solve these challenges: our goal was to develop a solution that enables all stakeholders to quickly and easily get access to relevant data, resulting in a better understanding of the application and data landscape. By making it easy to analyse data, we wanted to create transparency which leads to informed decision making processes and collaboration spanning the full application life-cycle.
We wanted something that looks like this:
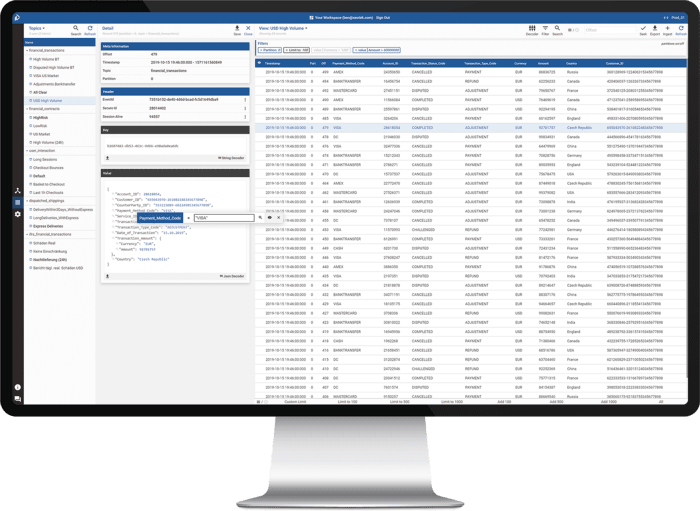
It is important to be able to quickly view relevant data objects, filter for various characteristics and types and share these reports with others. It is also important to still be flexible enough to dive into the underlying technical details as well. We think we were able to combine these two worlds and can provide you with one central data monitoring solution for your Apache Kafka system.
We are very enthusiastic about our product and invite you to learn more at www.kadeck.com
Watch our KaDeck 3.0 release video to get an overview of the functionalities: https://youtu.be/1TCojOdFhyQ
If you require more information about the challenges of application development and data integration with Apache Kafka, let me know in the comment section blow.
- Ben

Top comments (0)