
⚠ Note: this series is still a work in progress.
This series is up-to-date with the latest ML-Agents Release 18
Purpose
There are plenty of great reinforcement learning (RL) courses out there. Just to name a few:
- Introduction to Reinforcement Learning by David Silver
- Spinning Up by OpenAI
- Reinforcement Learning Specialization by University of Alberta
But if you're anything like me, you might prefer a 'learning by doing' approach. With hands-on experience upfront, it may be easier for you to grasp the theory and math behind the algorithms later.
In this series, I'll walk you through how to use Unity ML-Agents to build a volleyball environment and train agents to play in it using deep RL.

Why ML-Agents?
ML-Agents is an add-on for Unity (a game development platform).
It lets us design a complex physics-rich environment without needing to build any of the physics simulation logic ourselves. It also lets us experiment with state-of-the-art RL algorithms without having to set up any boilerplate code or install additional libraries. The nice graphics and interface are a plus.
A (very brief) overview of reinforcement learning
In a nutshell, think about how you might teach a dog a new trick, like telling it to sit:
- If it performs the trick correctly (it sits), you’ll reward it with a treat (positive feedback) ✔️
- If it doesn’t sit correctly, it doesn’t get a treat (negative feedback) ❌
By continuing to do things that lead to positive outcomes, the dog will learn to sit when it hears the command in order to get its treat. Reinforcement learning is a subdomain of machine learning which involves training an ‘agent’ (the dog) to learn the correct sequences of actions to take (sitting) on its environment (in response to the command ‘sit’) in order to maximize its reward (getting a treat).
This can be illustrated more formally as:
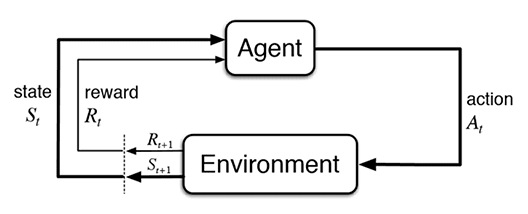
Source: Sutton & Barto
For more on the theory, check out:





Top comments (0)