Universal sentence encoder is a language model that encodes text into fixed-length embeddings. It aims to convert sentences into semantically-meaningful fixed-length vectors.

With the vectors produced by the universal sentence encoder, we can use it for various natural language processing tasks, such as classification and textual similarity analysis.
In the past
Before universal sentence encoder, when we need sentence embeddings, a common approach is by averaging individual word embeddings in a sentence. Whether if it is a ten words sentence or it is a thousand words document; averaging each embedding will produce a fixed-length vector.
Unfortunately, by averaging the vectors, we lose the context of the sentence and sequence of words in the sentence in the process.
And now
Yinfei Yang et al. introduce a way to learn sentence representations for semantic textual similarity using conversational data.
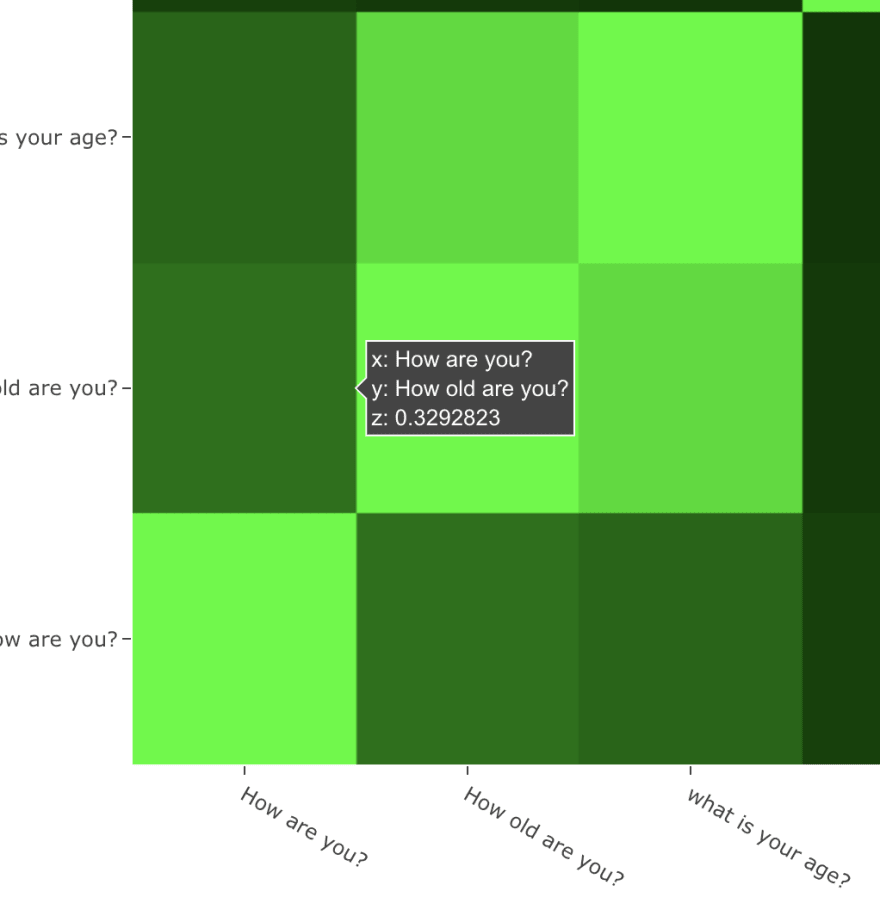
For example, "How old are you?" and "What is your age?", both questions are semantically similar; a chatbot can reply the same answer "I am 20 years old".
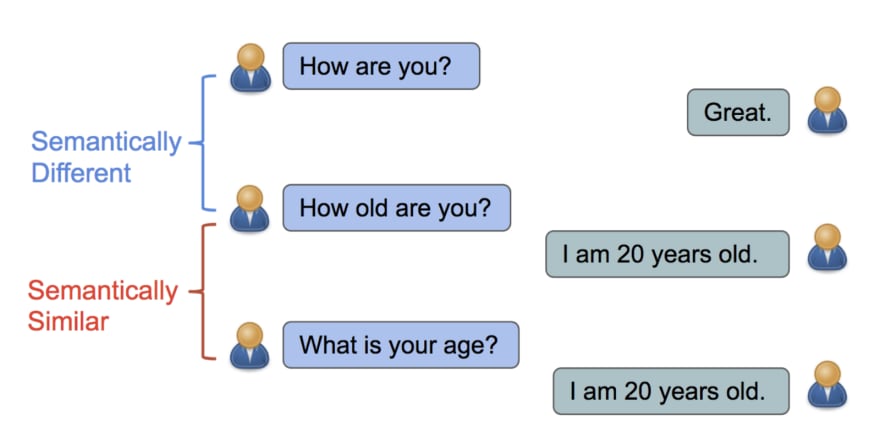
In contrast, while "How are you?" and "How old are you?" contain identical words, both sentences have different meanings.
Logeswaran et al. introduced a framework to learn sentence representations from unlabelled data.
In this paper, the decoder used in prior methods is replaced with a classifier that chooses the target sentence from a set of candidate sentences; it improves the performance of question and answer system.

Codes
I will be using is the universal sentence encoder package from TensorFlow.js. We can install universal sentence encoder using npm.
$ npm install @tensorflow-models/universal-sentence-encoder
This is an example to show how we can extract embeddings from each sentence using universal sentence encoder.
import * as use from '@tensorflow-models/universal-sentence-encoder';
use.load().then(model => {
const sentences = [
'Hello.',
'How are you?'
];
model.embed(sentences).then(embeddings => {
embeddings.print(true /* verbose */);
});
});
Demo
Feel free to try the textual similarity analysis web-app with your sentences, and comment below on which cases it does well, and when it doesn't.

Top comments (0)