The purpose of writing this article is to share and summarise some recommendation systems algorithms. These algorithms are 'traditional' machine learning methods rather than deep learning. The purpose of a recommendation system is to predict and rank a list of items (or documents), generally based on user's preferences from user-generated data. Here are some recommendation systems algorithms:
- Collaborative Filtering
- Bayesian
- K Nearest Neighbour
- Logistic Regression
- Decision Tree & Random Forest
Collaborative Filtering
Collaborative filtering algorithm focuses on common interest, it could be user centric or item (it could also be documents, or products or movies) centric. The assumption of collaborative filtering is that if user u has similar interest of that of user v, and if user v has interest on item j, we can also recommend item j to user u. Thus, we can make prediction on which items a user may like or dislike by referencing a group of similar users likes and dislikes.
Build item to item similarity matrix
This is a item centric approach, where we calculate the correlation coefficient between items. sim(i,j) calculates the similarity between item i and item j, where Vi is a vector with scores of different users to the item i. Vector V contains either 1 or 0 whether the user in the vector's index has purchased (or clicked, or add to cart) the item. Formula below is using cosine similarity to calculate correlation coefficient, but correlation score can also be calculated with Pearson and many other methods as well. Read more and example at Wikipedia:Slope One.

Search for item j for user u
score(u,i) is the preference score of the item i to user u, and rec(u,j) is to find the collaborative score of item j to user u. What we want to do is to score the entire set of items j that user u has not purchased, and rank a list of top highest collaborative scored items j to user.

Bayesian
Bayes theorem is about finding the conditional probabilities of event A occurs when event B occurs denoted as P(A|B). For example, when a user enters (or clicked) on a particular category or shop, we reference from a list of items that the user has purchased from that category or shop. Our problem here is P(j|u), which is to calculate the probability of user u purchasing item j:
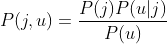
Since user has purchased n items I, we represent the list of items as { i1, i2, ..., in } from shop or category, and we calculate the probability of all items i with item j by all users:

P(j) is the probability of item j is being purchased to the number of times it was exposed by all users:
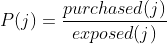
Likewise, we need to find the relationship of purchased items by finding the item-to-item's probability:

Due the rare occurrence of items purchased together, we can add a minimum number of purchases to 10. If it is less than 10, will use the percentage of users who have purchase the item i instead.

With bayesian, we are able to calculate the probability of user buying a particular item. We pre-calculate for every users to every items, and recommends list of items in descending probability order.
K Nearest Neighbour
K nearest neighbour (KNN) is about looking for a k number of objects that are closest to the object of interest. Again, this could be user centric or item centric.
If we want to group similar items together, we want to look for k number of items that are most similar to that item i. Items can be group by its similarity based on their attributes.
Alternatively, it could be user centric where we use user behaviors to find similar items. Items can be group by based on frequently clicked within a session, or items frequently bought together, and we can create item's embeddings by using DeepWalk to train items embeddings. So if a user clicked on item i, we could also recommend k items that are related. Use Jaccard to calculate correlation coefficient between users' clicks, add to cart, or purchases. A vector of all items for the user, when user u clicked on item i, i item index is value 1, otherwise it is 0. Then we can find out the similarity between 2 list of items I between user u and v.

Given a user u, find k number of users that have similar purchase (or clicks) history as user u. Remove items that user u has purchased and then select top k most popular (highest frequency) purchased items to user u.
There are several methods to calculate distance between vectors:
- Euclidean distance
- Manhattan distance
- Chebyshev distance
- Jaccard coefficient
- Cosine similarity
- Pearson coefficient
Logistic Regression
This method is popular for building recommender system with a click through rate model. The objective of the model is to optimise w and b for each feature and predict value Y (between 0 to 1), which is the probability of a user clicking on a particular item.
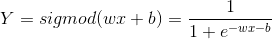
Where x is the input vector features of the model, w is the weight vector of features. wi represents the weight of the feature xi.
Construct user and item features
Features could be categorical or discrete. User features could be age (or age group), gender, purchase power level (based on past purchases), and item features could be category, price (or price group), sales past 30 days. Embeddings such as user's categories preference or item embeddings can be useful too, and these embeddings can be built with DeepWalk.
Collect historical user exposure and click data
This is the training data for the model, where each sample represents a user exposed to an item. The dimensions should include user ID, item ID, label whether item is clicked (0 or 1), a set of user features, and a set of item features.
trainingSampleID | label (click or not) | userId | itemId | ageGroup | userPurchaseLevel | itemPrice | itemSoldCount | ...
One hot encoding and normalisation.
All categorical features such as age group or category are one hot encoded. Continuous values such as price, order count or sales are normalised as LR is sensitive to outlier features.
Train
Train the model. Optimise w and b for each feature with gradient descent, with the following cross entropy loss function:

Score
To recommend from a set of candidate items I to user u, use the trained model to score every items in I with user u. Rank the scores from the model in descending order and recommend top 20 items to user u.
Decision Tree & Random Forest
A tree structure where each node of the tree represent a decision, and the outcome of the tree is on the leaf node. For recommendation systems, we can use decision tree to recommend categorical values such as categories. A successful decision tree algorithm has a set of rules that are able to predict leaf nodes with high accuracy.
Create features for modelling
- Get users data: prepare user features data such as age group, gender, city, purchase power level (based on past transactions)
- Get categories data: prepare categories features such as main category group, type, popularity (click through rate)
- Get purchase (or clicks) data: merge users to categories features if user purchased item in that category
- Construct cross features: define cross rule generation model features between user features with category features, example gender with category's main category and purchase power with category id
Random Forest
Random Forest is essentially a collection of decision trees, it can be used to replace decision tree. Each tree predicts an outcome on its leaf node, then the outcome with the most occurrences will be the predicted value. Every tree in a random forest are usually different, with different set of features, and with different set of outcome. Each tree are trained with random sample of training data, and each step in the training process it selects the features with the most optimal split. The number of decision trees need to be tuned to balance classification accuracy, overfitting, and model complexity.

Top comments (0)