
Each development project is unique, and there are times when the characteristics of a particular technology show up as a perfect constellation. I would love to present my case.
Two years ago, I started developing an educational project called eningles.club of which I am immensely proud and is already working and helping students from different countries.
The objective was initially quite simple: a web tool that would help early English learners to improve their English reading and listening skills.
To do this, I set out to develop a tool that would offer students different activities that would reinforce their vocabulary and grammar before reading well-known stories in English from prestigious publishers that are easy to find in a bookstore.
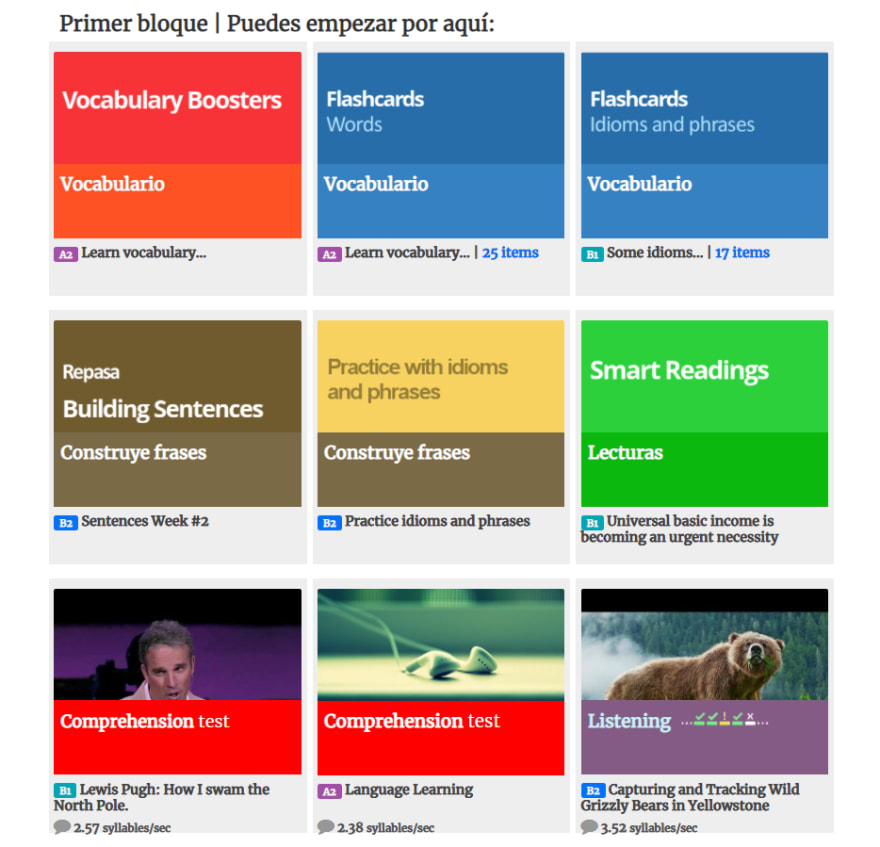
Image #1: Example activities
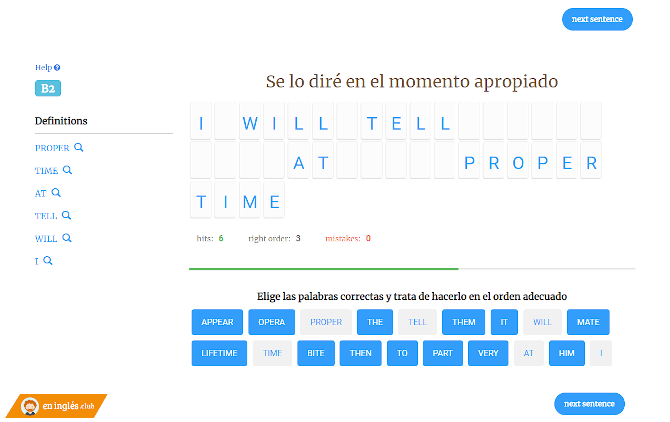
Image #2: Grammar activity
The tool is currently available for native Spanish language students, but I would like to extend it to students from anywhere in the world in the future.
Determined to undertake the adventure, I looked for and studied different alternatives in terms of technology.

I raised four fundamental options:
- Django / Python + Javascript for the frontend
- React / Node
- React / Headless CMS (Strapi, Directus ...)
- Monolithic CMS (WordPress, Drupal ...)
The second and third options attracted me enormously, but there were good reasons which, like stars of a perfect constellation, led me to choose Django, a framework that I have already covered in a previous article:
Star #1: Django Admin
A large part of the development effort required for an educational application like this would go to the development of a backend to manage the creation and maintenance of very varied content: lessons, readings, grammar exercises, flashcards, multiple-choice exercises, vocabulary pills, and also chain them in "routes" and learning sessions.
Not developing this background would mean having to edit all these contents directly on the database or keeping it in some plain text format following a particular grammar (using the well-known LEX and YACC tools for example). Also, the idea is that in the future other collaborators can contribute content.
Using a Headless CMS seemed viable, but there was a much more powerful option: Django Admin.
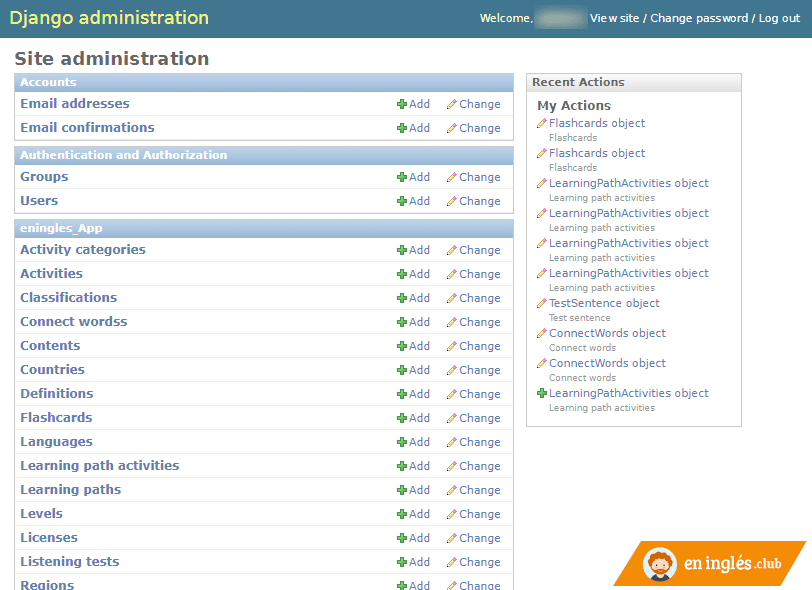
Image #3: Django Admin main view
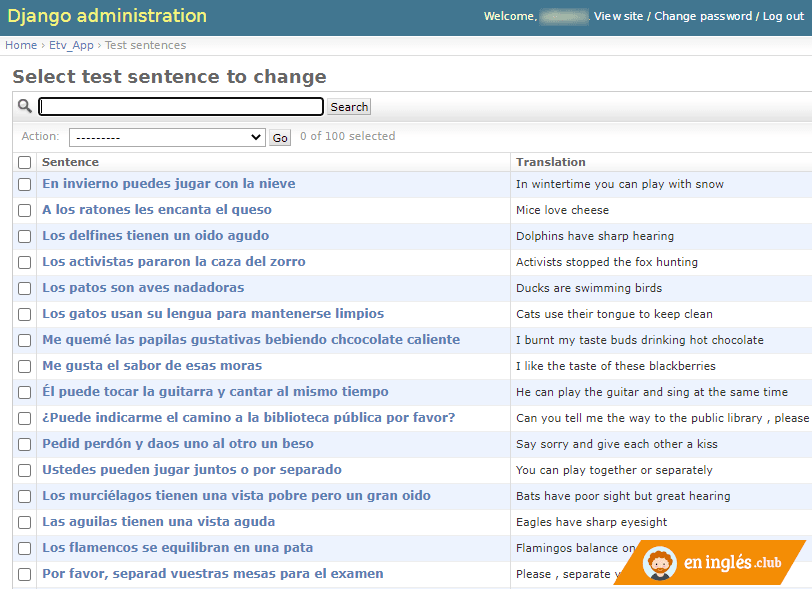
Image #4: Django Admin
Django Admin offers a highly customizable CRUD interface. This interface is automatically generated from the definition of the database data model already written in Python as part of the Django project. To this is added other metadata information that we can contribute. That allows us to make the Django Admin interface more user-friendly (labels, validations, relationships ...) and create more complex tools intended even for other staff users with non-technical profiles.
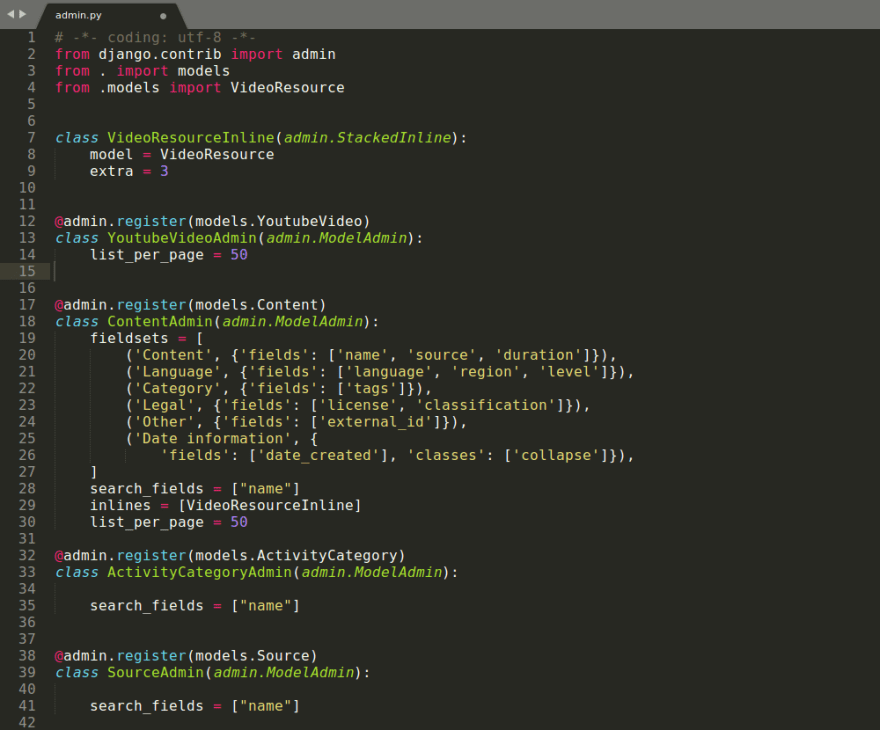
Image #5: Administration metadata for database model
With this possibility that Django offers me, I cut development time by months because I did not have the time to save in the future in backend maintenance and error correction.
Star #2: Natural language processing with NLTK
My project required developing natural language analysis algorithms to process lots of contents written in English, mainly text and video transcripts.
I needed to extract specially difficult vocabulary according to the different English levels(A1, B1, B2 ...), classify language by level, detect verb conjugations, proper names, and classify the complexity of sentences...
One of the key characteristics is determining how difficult a word is for a English learner depending on the word itself and the context in which it is found.
Based on the facilities that NLTK provides, the algorithms used to analize the vocabulary present in a text are based on different studies:
Research papers from Paul Nation about his work in English language learning and vocabulary coverage in English texts -link-
Resources from the University Centre for Computer Corpus Research on Language at the University of Lancaster -link-
Resources from University of Oxford about researching in English corpora -link-
English Profile from Cambridge University -link-
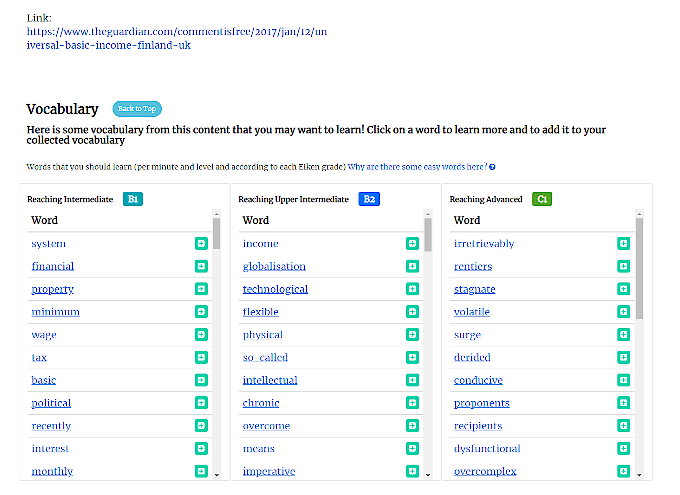
Image #6: Vocabulary analysis for a given text
Python has excellent natural language processing packages. NLTK is undoubtedly the most important, extremely powerful, but other libraries like TextBlob are especially interesting for specific tasks without conflicting with the use of NLTK.
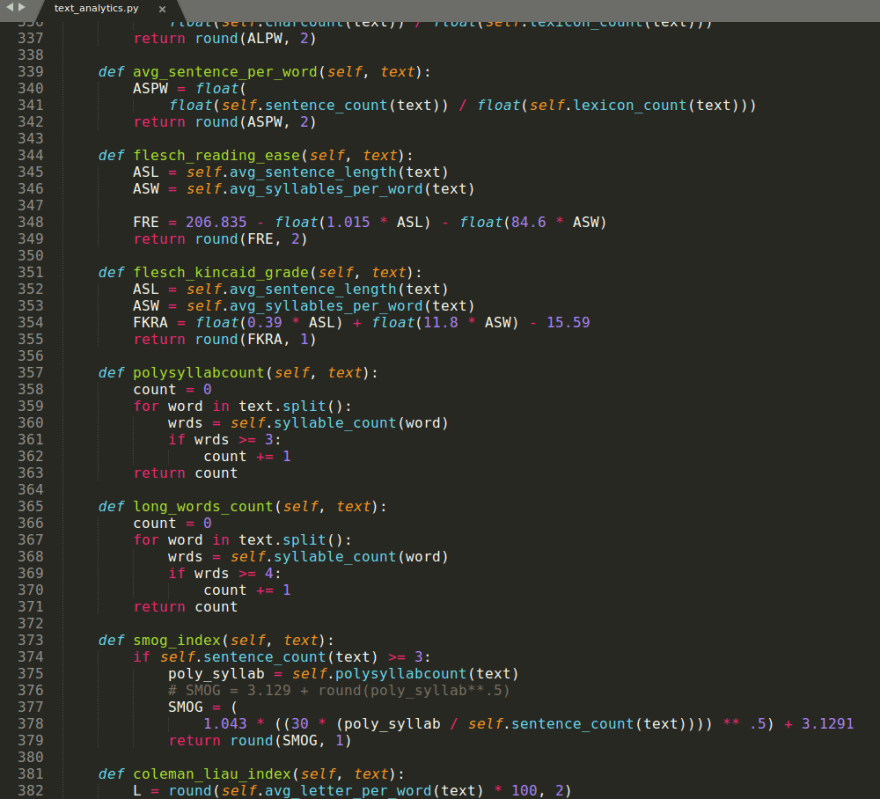
Image #7: Readability tests code
NLTK also offered me a perfect gift: a compelling interface with WordNet, a huge lexical database in English, something like a complete thesaurus for scientific purposes, organized in semantic sets called synsets.
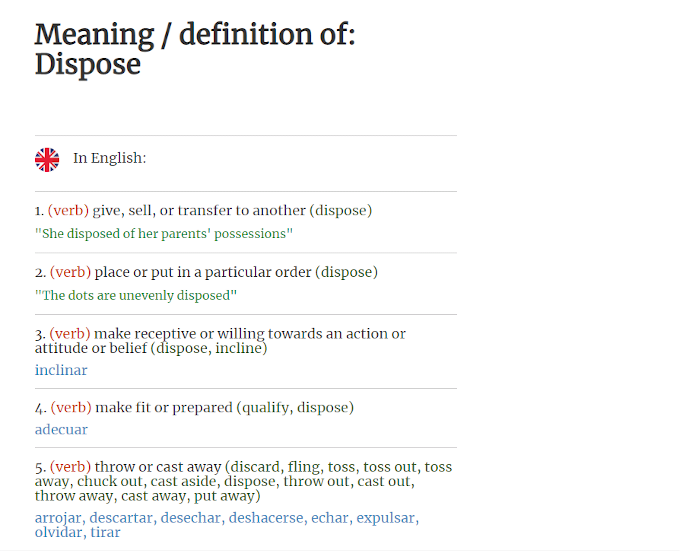
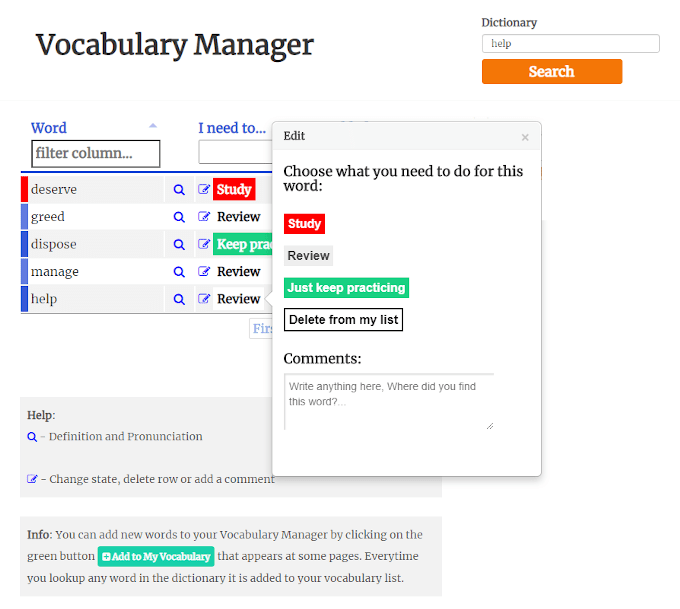
Image #8: Dictionary and vocabulary manager
Also, its license for use is relatively permissive to use Wordnet to offer an exciting dictionary within my project.
Again a possibility was open to me to cut the development time dramatically.
This project uses a readability test based on different readability studies to classify the complexity of any text and determine how suitable it is for a student. Scores from readability formulas generally correlate highly with the actual readability of a text.
Were readability test comes from?
The US Military took the first step in grading adults in 1917. In 1921 Edward Thorndike tabulated the frequency of difficult words used in general literature, a great step in analyzing texts complexity.
First modern readability tests were developed in the 1930s. The Great Depression sparked investment in adult education. General adult readers in the United States had limited reading ability and many students complained that many books were too difficult to read. These first readability tests were based on sentence length and difficult words.
In 1949 George Kingsley Zipf came up with his study "Human Behavior and The Principle of Least Effort", in which he declared a mathematical relationship between the hard and easy words and its frequency in texts, called Zipf’s Curve.
Later In the 1940s and the 50s, with the birth of modern marketing, several linguists like Rudolf Flesch and Robert Gunning strove to create the easiest and most reliable readability formula. Readability studies became a very competitive field.
Both public (education, military...) and private sectors (publishing, journalism...) needed readability tests to ensure that texts meet a minimum readability requirement. As an example the Texas Department of Insurance has a requirement that all insurance policy documents have a Flesch Reading Ease score of 40 or higher, the reading level of a first-year undergraduate student.
In the 1970s, Flesh published another readability formula with his colleague J Peter Kincaid in partnership with the US Navy: the Flesch Kincaid . After rigorous validation, the formula became US military standard. It also was applied to other sectors, like the insurance industry.
Nowadays there are over 200 readability formulas and readability is a research field in continuous evolution.
Star #3: Choosing PostgreSQL as my database engine
PostgreSQL was shown to me as the perfect option over other options (MySQL, MongoDB ...) for some reasons:

I wanted to manage my Database instance and not a cloud database, and I had previous experience with PostgreSQL.
For some of the features that I planned to offer, I needed the richness SQL offers to execute queries. In many cases, the questions have a certain complexity, involving variable relationships between different data types.
I did not anticipate frequent changes in the data model that would justify a NoSQL model.
PostgreSQL offers adequate mechanisms to scale, if necessary, something that does not concern me for now.
Star #4: The Python ecosystem.
The Django and Python ecosystem is merely unique. You can find a solution to any problem and focus on developing "your idea".
For example, one of the features that it wanted to offer was that the student had access to the pronunciation of any word they were looking for in the dictionary at the click of a button, something similar to what Youglish does.
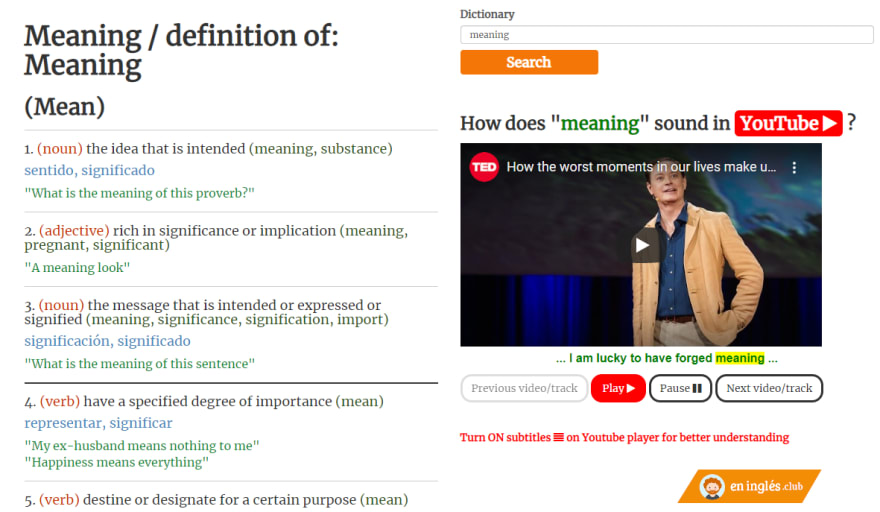
Image #9: Pronunciation assistant
I needed to be able to access the transcripts of thousands of YouTube videos and to be able to analyze their content to index the appearance of thousands of words from the Wordnet dictionary. I found two beneficial Python tools: youtube2str and Youtube-transcript-API.
But these are not the only libraries/features of Django and Python that helped me in the task and that I would like to comment, something that I think may help others who are considering the development of a similar educational tool:
- crispy-forms: rapid form development and Ajax validation
Image #10: Form definition
- Django-allauth: sign up, authentication, and user account management
Image #11: Signup section specification (Allauth)
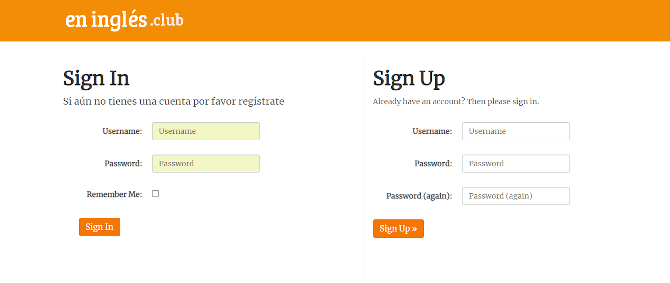
Image #12: Signup and signin page design
Django Mobile: library for the detection of browsers on mobile devices for their differentiated treatment in the templating system
GeoIP2: wrapper for the MaxMind geoip2 Python library
Django-humanize: a series of filters for Django's templating system to make the interface more human
Django templating language and Jinja to define templates in HTML
Django Managements Commands: This is not a library but a Django feature. The management commands are small Python applications that can be invoked from the command line perfectly integrated with the Django project. In the project, I use dozens of them for a multitude of small automation tasks, scrapping-etc ...
Thanks for reading this article. If you have any questions, feel free to comment below.
Connect with me on Twitter or LinkedIn
Creative Common Images from Flickr:
https://www.flickr.com/photos/luisfelipepadilla





Top comments (0)