RESTful APIs offer a straightforward way for businesses to work with external data and offer access to their own data. With more than 24,000 public APIs providing access to limitless data and the typical enterprise leveraging more than 200 applications, teams and developers need more efficient ways to query API data. With the CData API Driver, it is easier than ever to integrate with APIs at scale for data analytics and application development.
Why use the API Driver?
Use simple SQL to access and work with data anywhere there’s an API. Like all CData Drivers, the CData API Driver makes it easier to work with your data. With the API Driver and the available API Profiles, you can instantly and codelessly query dozens of APIs (including any APIs built using the CData API Server) from BI, data integration, and custom applications.
Thanks to its extensible design, organizations and developers can modify API Profiles from API Server to customize integrations and even create their own API Profiles. Easily expand the connectivity offered by API Driver to any RESTful API.
This article shows how to create a new API Profile to enable SQL access to a new API.
Creating an API Profile
API Profiles grant SQL access to APIs. While there are dozens of APIs supported out of the box, you are also able to create a new Profile to enable SQL access to any API.
Create a Schema File (.rsd)
API Profiles contain a collection of schema files that represent the endpoints available for the API. For this article, we will start a Profile for the TripPin OData v4 API by creating a schema file for the People endpoint. Each schema file has several parts that define how SQL access is enabled for an API endpoint.
api:info: This keyword maps API fields to table columns through scripted column definitions.
attr: This element represents a column definition (details are below).
api:set attr="...": This keyword (attribute) sets various parameters for the API integration, including paging functionality and information on how to parse the API response (via the RepeatElement attribute).
api:script method="...": This keyword defines how read and write functionality is implemented for the API endpoint, including which internal operation is called and how specific functionality like filtering is managed.
Start by creating a new text file called People.rsd. From here, we walk through creating each section of the schema file, based on the API specification.
Create Column Definitions
API Driver schema files enable SQL access to API endpoints, and this starts with creating column definitions for corresponding API fields for the given endpoint, using API Script keywords and other functionality. An api:script keyword contains the entire schema definition. An api:info keyword provides the table name & description and contains the column definitions, where each API field is mapped to a table with an attr (attribute) element.
The People endpoint of our API returns a series of people, where each entry is represent by a JSON object similar to the following:
{
"UserName" : "russellwhyte",
"FirstName" : "Russell",
"LastName" : "Whyte",
"MiddleName" : null,
"Gender" : "Male",
"Age" : null,
"Emails" : ["Russell@example.com","Russell@contoso.com"],
"FavoriteFeature" : "Feature1",
"Features" : ["Feature1","Feature2"],
"AddressInfo" : [
{ "Address" : "187 Suffolk Ln.",
"City":{
"Name" : "Boise",
"CountryRegion" : "United States",
"Region" : "ID"
}
}],
"HomeAddress" : null}
We can using path definitions based on the JSON structure to drill down into each of the values in the response, effectively flattening the response into a SQL table model. Create the column definitions based on the API specification and inferred information based on the response. An explanation of the column definition follows.
...
Column Definition Attributes
name: The name of the column in the SQL interface for the API endpoint
xs:type: The data type associated with the column (e.g.: string, datetime, int, etc.)
readonly: Whether the column allows writes (by default, this is always true)
key: Whether a column is intended to be a unique identifier for the elements in a table/view
other:xPath: The path (exact or relative to theRepeatElement) in the API response to the column value
Specific Columns
Here, we examine specific column definitions and explain how the different attributes create the SQL mapping for the API fields.
| Column | Featured Attribute |
|---|---|
| UserName | key |
| ALL | readonly |
| ALL | xs:type |
| Feature1 | other:xPath |
| City | other:xPath |
Meaning of key: Signifies UserName as a unique identifier for the table
Meaning of readonly: Determines whether a column can be modified or not
Meaning of xs:type: Sets the SQL datatype (based on API specification or data model)
Meaning of other:xPath: The array index [0] indicates to pull the first entry in the Features JSON array
Meaning of other:xPath: Drills into the AddressInfo JSON object to expose the city name
Add Global Parameters
After creating the column definitions, we need to set the global parameters for integrating with the API, including the API endpoint to request data from, any required values for connecting, specific fields or headers for the API request, and the repeated element in the API response that represents individual entries for the API endpoint.
...
...
Add Read/Write Functionality
With the columns and global parameters defined, we can complete the schema file by scripting the read and write functionality. SELECT functionality is implemented in the keyword, setting the HTTP method to GET and calling the apisadoExecuteJSONGet operation to retrieve and process the data.
To implement INSERT / UPDATE / DELETE functionality, we need to add additional api:script elements with the POST, MERGE, and DELETE methods and implement the specific functionality with further scripting. For this article, we will only implement SELECT functionality and throw an error message if we try to write to the API endpoint.
Setting the method Attribute
...
...
With the API functionality implemented, we can use the profile with the API Driver in any tool or application that supports JDBC or ADO.NET connectivity, granting SQL access to the API.
Using the Profile in DbVisualizer
The API Driver has two connection properties used to connect to an API:
Profile: The folder containing the schema files for your API.
ProfileSettings: A semi-colon separated list of name-value pairs for connection properties required by your chosen Profile — since we are connecting to an open API, we can leave this property blank.
Because we are connecting in DbVisualizer, we will configure a JDBC connection string to connect to the API through the Profile:
jdbc:apis:Profile=/PATH/TO/TripPin/;
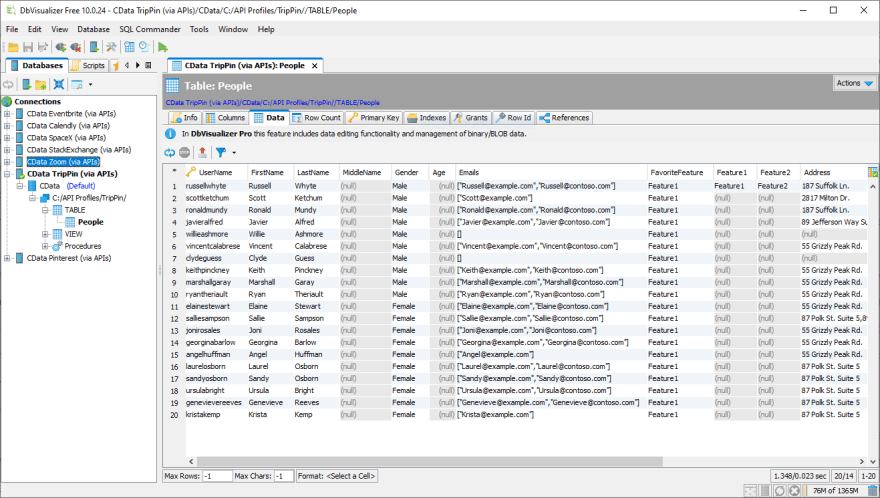
In DbVisualizer, we create a new Connection using the API Driver and set the Database URL to the connection string. From there, we can connect to the Profile, expand the data model, and explore the data in the People "table" (which represents the People API endpoint).
More Information
The CData API Drivers simplify data connectivity for a wide range of popular data tools. Connect BI, Reporting, & ETL tools to live data from any application, database, or Web API. Built on the same robust SQL engine that powers CData Drivers, the CData API Driver enables simple codeless query access to APIs through a single client interface.

Top comments (0)