
Artificial Intelligence is hot research area since past few years and there are many major breakthroughs happening in this area. The traditional problems (or goals) of AI research include reasoning, knowledge representation, planning, learning, natural language processing, perception and the ability to move and manipulate objects. Extreme Learning Machines (ELMs)—has become one of the hot area of research over the past years, many researchers around the world are contributing to the research in this topic.
In this series of articles, we will explore Extreme Learning Machines [ELMs]. In this part, we will see introductions to various concepts which will help us understand ELMs in details.
According to Professor Huang Guangbin, Extreme Learning Machines (ELM) are filling the Gap between Frank Rosenblatt's Dream and John von Neumann's Puzzle.
Let's go 60 years back and see what he meant by that:
Rosenblatt made statements about the perceptron that caused a heated controversy among the fledgling AI community. Based on Rosenblatt's statements, The New York Times reported the perceptron to be "the embryo of an electronic computer that [the Navy] expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence. Which was to be fair is the definition of cognition. [http://en.wikipedia.org/wiki/Perceptron]
In their book Perceptron [1969], the famous pioneers in AI Marvin Minsky and Seymour Papert claimed that the simple XOR cannot be resolved by two-layer of feedforward neural networks, which "drove research away from neural networks in the 1970s, and contributed to the so-called AI winter".[Wikipedia 2013]
During same time, John Von Neumann felt puzzled on why "an imperfect (biological) neural network, containing many random connections, can be made to perform reliably those functions which might be represented by idealized wiring diagrams.”
If you want to read more about what are Artificial Neural Networks, you can read my series over here.
For now, Let's see what are FeedForward Neural Network:
Feedforward neural network :
Feedforward neural network is the first invention is also the most simple artificial neural network. It contains multiple neurons (nodes) arranged in multiple layers. Adjacent layer nodes have connections or edges. All connections are weighted.
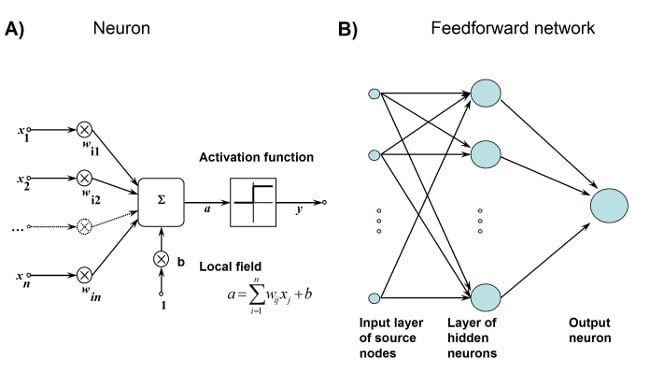
A feedforward neural network can contain three kinds of nodes:
Monolayer:This is the simplest feedforward neural network that does not contain any hidden layers.Multilayer Perception:Multilayer Perception has at least one hidden layer. We will only discuss multilayer perceptrons below, as they are more useful than single-layer perceptrons in today’s real world.Multilayer perceptrons:Multilayer Perceptron (MLP) includes at least one hidden layer (except for one input layer and one output layer). Single-layer sensors can only learn linear functions, while multi-layer sensors can also learn nonlinear functions.
Broadly describing there are 3 types of layers:
Input Layer:The input layer has three nodes. The offset node value is 1. The other two nodes take external inputs from X1 and X2 (both are digital values from the input data set). As discussed above, no calculations are performed at the input layer, so the output of the input layer node is 1, and three values X1 and X2 are passed to the hidden layer.Hidden layer:Hidden layer also has three nodes, offset node output is 1. The output of the other two nodes of the hidden layer depends on the output (1, X1, X2) of the input layer and the weight attached to the connection (boundary). Figure 4 shows the calculation of an output in hidden layer (highlighted). The output of other hidden nodes is calculated in the same way. Note that f refers to the activation function. These outputs are passed to nodes in the output layer.Output Layer:The output layer has two nodes that receive input from the hidden layer and perform calculations similar to the highlighted hidden layer. These calculated values (Y1 and Y2) as the result of the calculation are the output of the multilayer sensor.
For our convenience let's classify feedforward neural networks into two categories: Single-Hidden-Layer Feedforward Networks (SLFNs) and Multi-Hidden-Layer Feedforward Networks.
Mathematical Model for SLFNs–
Approximation capability [Leshno 1993, Park and Sandberg 1991]:Any continuous target function f(x) can be approximated by SLFNs with adjustable hidden nodes. In other words, given any small positive value , for SLFNs with enough number of hidden nodes (L) we have .Classification capability [Huang, et al 2000]:As long as SLFNs can approximate any continuous target function f(x), such SLFNs can differentiate any disjoint regions.

A. Learning Issues:
Conventional theories: only resolves the existence issue, however, does not tackle learning issue at all.
In real applications, target function f is usually unknown. One wishes that unknown f could be approximated by SLFNs appropriately .
B. Learning Methods:
-
Many learning methods mainly based on gradient-descent / iterative approaches have been developed over the past three decades.
- Back-Propagation (BP) [Rumelhart 1986]and its variants are most popular.
Least-square (LS) solution for RBF network, with singleimpact factor for all hidden nodes
[Broomhead and Lowe 1988].QuickNet
(White, 1988)and Random vector functional network (RVFL)[Igelnikand Pao 1995].Support vector machines and its variants.
[Cortes and Vapnik 1995]Deep learning: dated back to 1960s and resurgence in mid of 2000s
[wiki 2015]
Let's understand the Aim of ELM:
According to Professor Huang:
Unlike conventional learning theories and tenets, our doubts are "Do we really need so many different types of learning algorithms (SVM, BP, etc) for so many different types of networks (different types of SLFNs (RBF networks, polynomial networks, complex networks, Fourier series, wavelet networks, etc) and multi-layer of architectures, different types of neurons, etc)? "
Is there a general learning scheme for wide type of different networks (SLFNs and multi-layer networks)?
Neural networks (NN) and support vector machines (SVM) play key roles in machine learning and data analysis. Feedforward neural networks and support vector machines are usually considered different learning techniques in computational intelligence community. Both popular learning techniques face some challenging issues such as: intensive human intervene, slow learning speed, poor learning scalability.
It is clear that the learning speed of feedforward neural networks including deep learning is in general far slower than required and it has been a major bottleneck in their applications for past decades. Two key reasons behind may be: 1) the slow gradient-based learning algorithms are extensively used to train neural networks, and 2) all the parameters of the networks are tuned iteratively by using such learning algorithms.
Why ELM?
How ELM theories manage to address the open problem which has puzzled the neural networks, machine learning and neuroscience communities for 60 years:
whether hidden nodes/neurons need to be tuned in learning, and proved that in contrast to the common knowledge and conventional neural network learning tenets, hidden nodes/neurons do not need to be iteratively tuned in wide types of neural networks and learning models (Fourier series, biological learning, etc.). Unlike ELM theories, none of those earlier works provides theoretical foundations on feedforward neural networks with random hidden nodes;ELM is proposed for both generalized single-hidden-layer feedforward network and multi-hidden-layer feedforward networks(including biological neural networks);
homogeneous architecture-based ELMis proposed for feature learning,clustering, regression and (binary/multi-class) classification.Compared to ELM, SVM and LS-SVM tend to provide suboptimal solutions, and SVM and LS-SVM do not consider feature representations in hidden layers of multi-hidden-layer feedforward networks either.
What's next
Now we know all the basics which are required to understand ELM better and we are good to go deep to understand mathematical aspect of ELM along with details of how that works.
In next part, we will define ELM and see how ELMs learn. If you want to learn more about Neural Networks, XoR Problem you can visit articles I linked here.
References:
- Extreme learning machines: theory and applications
- Convolutional neural network based on an extreme learning machine for image classification
- Extreme Learning Machines
- What are Extreme Learning Machines? Filling the Gap BetweenFrank Rosenblatt’s Dream and John von Neumann’s Puzzle
- Perceptron and backpropagation





Top comments (0)