大家好,我是 Jambo。我們已經學習瞭如何使用 LangChain 的一些基本功能,解下我們就應該要結合這些功能來做一些複雜的東西了。但在這之前,為了讓同學們更好的理解 LangChain 在這其中做了什麼,我想先介紹一下關於 GPT 使用方面的一些知識。
在 ChatGPT 開放之初,除了各大公司在 AI 算法方面競爭,還有許多人在研究如何僅通過修改 prompt 就能讓 GPT-3 做出更好的回答,這種方法被稱為“提示工程(Prompt Engineering)”。如果把 LLM 比喻成一個擁有一般常識的大腦,那麼提示工程就是在教它如何思考,從而更有效的結合知識得出答案。像 AutoGPT 就是這樣,他通過精心設計的 prompt,就能讓 GPT-4 自行完成各種任務。為了讓同學們了解這其中的思想,我們先從“思維鏈”開始介紹。
思維鏈(Chain of Thought)
思維鏈(Chain of Thought)在 ChatGPT 推出後不久就被提出,具體來說就是通過手動編寫示例的方式讓 GPT-3 將問題的思考過程也生成出來,通過這種方式 GPT-3 回答的效果會有大幅提升。就像我們在寫比較複雜的計算題,將過程一步一步寫出來的正確率會比直接寫出答案要高。

後來有人發現,只需要加上 “Let's think step by step.” 這一魔法提示,就能達到一樣的效果,還不需要寫示例。並且他還在這基礎上,額外讓 GPT 根據它前面附帶思考過程的回答,再總結出一個更簡潔的答案,相當於把思考過程隱藏起來。
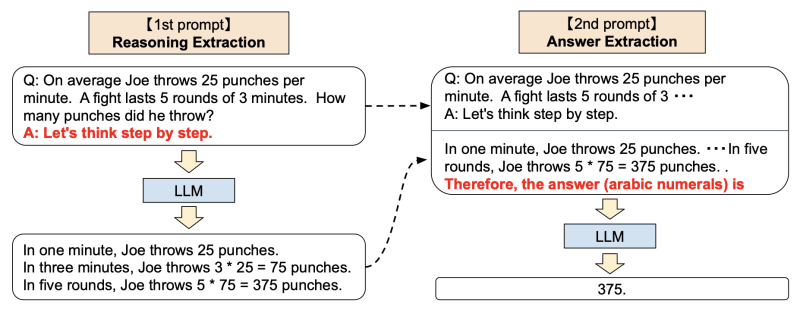
我這裡想強調的是,我們用 LLM 構建應用時,完全可以在輸出最終答案前多次用 LLM 分析、拆解、解決問題。就像深度學習網絡中的介於輸入和輸出之間的隱藏層,我們可以在這裡加入更多的邏輯,讓 LLM 能夠更好的理解問題,從而得出更好的答案。
ReAct
無論我們如何調整 prompt,但 LLM 仍然存在一個重大缺陷:它始終基於訓練時的數據集和 prompt 中提供的信息生成回答。如果提問有關天氣、新聞或內部文件等問題,LLM 將無法回答或會產生虛假回答("幻覺")。
當然,我們可以在用戶提出問題後,先使用搜索引擎或內部資料庫來搜索問題,然後將搜索結果作為 prompt 的一部分。但在實際應用中,這種方法的效果並不總是好的,甚至在某些情況下會產生誤導。例如,如果我們想讓 LLM 幫助我們修改一篇文章,在這種流程下,程序會首先使用搜索引擎搜索文章,但很可能搜索不到相關結果。這樣一來,LLM 就會直接罷工,因為我們通常要求 LLM 僅根據 prompt 提供的信息生成內容,以確保准確性。
為了解決這個問題,我們可以讓 LLM 自己決定是否要進行搜索,要搜索什麼內容,就和上一篇教程中提到的用 LLM 優化搜索語句一樣。於是 ReAct 系統就被提出來了,通過 prompt 中的示例告訴 LLM 可以使用哪些工具,然後讓 LLM 自己決定是否要使用這些工具,以及如何使用這些工具。 ReAct 總共有三個部分:
- 思考:根據當前的信息思考需要做什麼動作。
- 行動:根據思考結果做出相應的行動,如調用工具。程序可以分析這一步生成的字符串,來調用相應的工具,類似 Python 的
eval函數。 - 觀察:存放行動的結果,如搜索的內容,以便下一次思考時使用。
這三個步驟會不斷循環,直到思考步驟判斷已經找到答案,並在下面的行動中給出最終答案。

其實你仔細回想一下,這個過程和我們人類思考的過程是類似的。我們在思考時,會根據當前的信息判斷是否需要做出某些行動,然後根據行動的結果來判斷是否已經找到答案,如果沒有就繼續思考,直到找到答案為止。
AutoGPT 的行為模式實際上和 ReAct 一樣,只是相比提出 ReAct 的論文中的步驟,AutoGPT 的 prompt 更加詳細,並且提供了更多的工具給 LLM 使用。但不管哪種方式,都需要編寫大量的示例來告訴 LLM 如何思考、行動,並且根據提供工具的不同,效果也會有所不同,並且 ReAct 的思考流程會有很多步驟。而 LangChain 幫我們把這些步驟都隱藏起來了,將這一系列動作都封裝成 “代理”,而這就是我們下一章要介紹的內容了。





Top comments (0)