
MNIST dataset is a set of 70,000 small images of digits handwritten by high school students and employees of the US Census Bureau. Each image is labeled with the digit it represents.
This set has been studied so much that it is often called the "hello world" of Machine Learning.
The idea is to feed through the pixel values to the neural network and then have the neural network output, which number it actually thinks that image is.
1. Load the data
Now we're going to import dataset. MNIST dataset consists of 28 * 28 sized unique images of handwritten digits 0-9. Now, we are going to unpack the data to training and testing set.
2. Normalization
The data seems to vary from 0 to 255 for pixel data. So, we want to scale the data between 0 and 1 and that just make it easier for the network to learn.
3. Building model
It is going to be Sequential type of model. It's a feed forward like the image we drew. The first layer will be the input layer. We want the image to be flat and not in multidimensional array. Now, we are going to have two hidden layers with 128 neurons and relu activation and the output layer will consist of 10 classifications and softmax activation.
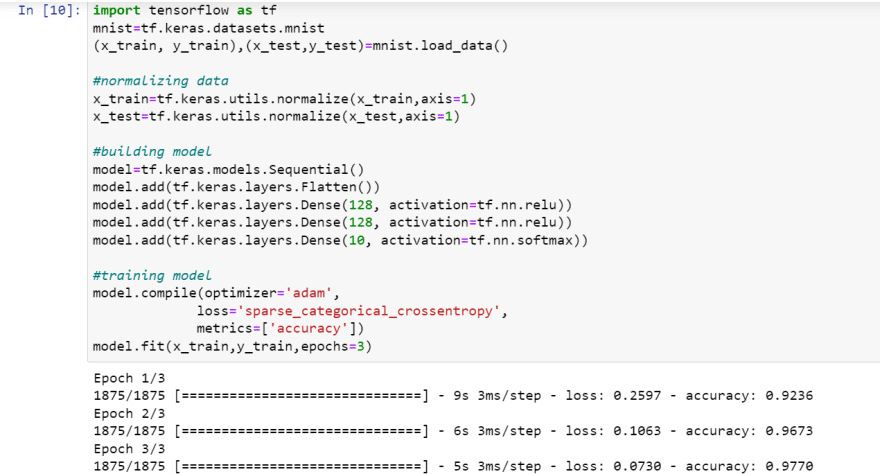
4. Training model
Now we need to "compile" the model. This is where we pass the settings for actually optimizing/training the model we've defined.
Next, we have our loss metric. Loss is a calculation of error. A neural network doesn't actually attempt to maximize accuracy. It attempts to minimize loss. Again, there are many choices, but some form of categorical crossentropy is a good start for a classification task like this.
5. Making predictions
Finally, with your model, you can save it super easily and make predictions.
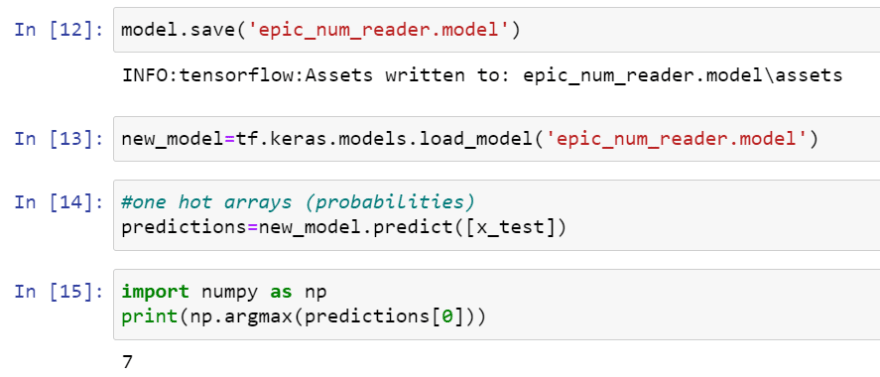
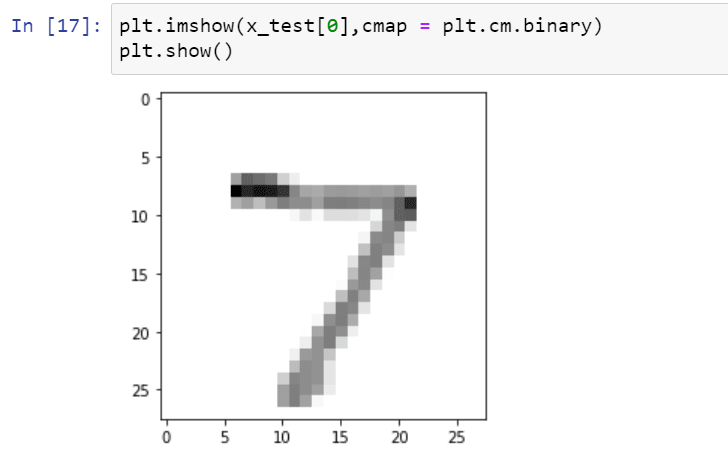





Top comments (0)