Previous post - Using AI to Simplify Clinical Documents Storage, Retrieval and Search
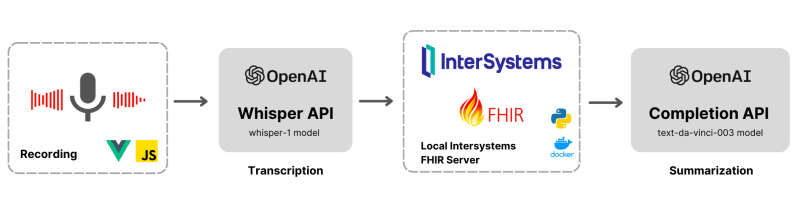
This post explores the potential of OpenAI's advanced language models to revolutionize healthcare through AI-powered transcription and summarization. We will delve into the process of leveraging OpenAI's cutting-edge APIs to convert audio recordings into written transcripts and employ natural language processing algorithms to extract crucial insights for generating concise summaries.
While existing solutions like Amazon Medical Transcribe and MedVoice offer similar capabilities, the focus of this post will be on implementing these powerful features using OpenAI technology within Intersystems FHIR.
Recording audio on Vue.js
The voice recorder on the Vue.js app if fully native and written using the Mediarecorder interface in javascript. This was done to keep the application light-weight and also get full control over the recording options. Below are snippets to start and stop recording audio input.
// Start recording method that stores audio stream as chunks
async startRecording() {
try {
const stream = await navigator.mediaDevices.getUserMedia({
audio: true,
});
this.mediaRecorder = new MediaRecorder(stream);
this.mediaRecorder.start();
this.mediaRecorder.ondataavailable = (event) => {
this.chunks.push(event.data);
};
this.isRecording = true;
} catch (error) {
console.error("Error starting recording:", error);
}
}
// Stop recording method that creates a blob after stop (and calls the transcription method)
stopRecording() {
if (this.mediaRecorder) {
this.isLoading = true;
this.mediaRecorder.stop();
this.mediaRecorder.onstop = async () => {
const blob = new Blob(this.chunks, {
type: "audio/webm;codecs=opus",
});
await this.sendAudioToWhisper(
new File([blob], `file${Date.now()}.m4a`)
);
this.getSummary(this.transcription);
};
}
}Transcription Component
Transcription of audio data using OpenAI's Whisper model involves several essential components. The following code snippet demonstrates the steps involved in the transcription process.
const apiKey = process.env.OPENAI_API_KEY;
const formData = new FormData();
formData.append("file", blob);
formData.append("model", "whisper-1");
formData.append("response_format", "json");
formData.append("temperature", "0");
formData.append("language", "en");
try {
const response = await fetch(
"https://api.openai.com/v1/audio/transcriptions",
{
method: "POST",
headers: {
Accept: "application/json",
Authorization: `Bearer ${apiKey}`,
},
body: formData,
redirect: "follow",
}
);
const data = await response.json();
if (data.text) {
this.transcription = data.text;
}
} catch (error) {
console.error("Error sending audio to Whisper API:", error);
}
return this.transcription;-
API Key - The
OPENAI_API_KEYis a required authentication token for accessing OpenAI APIs. -
Form Data - The audio file to be transcribed is appended to a
FormDataobject. Additional parameters like the chosen modelwhisper-1, the response format (json), temperature (`), and language (en`) are also included. -
API Request - The
fetchmethod is used to send a POST request to the OpenAI API endpointhttps://api.openai.com/v1/audio/transcriptionswith the specified headers and body containing the form data. -
Response Handling - The response from the API is captured, and the transcribed text is extracted from the
dataobject. The transcription can be assigned to a variablethis.transcriptionfor further processing or usage.
Summarization Component
The following code snippet demonstrates the core components involved in the text summarization process using OpenAI's text-davinci-003 model.
response = openai.Completion.create(
model="text-davinci-003",
prompt="Summarize the following text and give title and summary in json format. \
Sample output - {\"title\": \"some-title\", \"summary\": \"some-summary\"}.\
Input - "
+ text,
temperature=1,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=1
)
return response["choices"][0]["text"].replace('\n', '')-
Model Selection - The
modelparameter is set totext-davinci-003, indicating the use of OpenAI's text completion model for summarization. - Prompt - The prompt provided to the model specifies the desired outcome, which is to summarize the input text and return the title and summary in JSON format. The input text is concatenated to the prompt for processing. It’s interesting how we can handle response transformation through OpenAI. Only validation at the receiving end is enough and we might almost never need converters in the future.
-
Generation Parameters - Parameters such as
temperature,max_tokens,top_p,frequency_penalty, andpresence_penaltyare set to control the behaviour and quality of the generated summary. -
API Request and Response Handling - The
openai.Completion.create()method is called to make the API request. The response is captured, and the generated summary text is extracted from the response object. Any newline characters (\n) in the summary text are removed before returning the final result.
Document Reference in FHIR
In the context of implementing doctor-patient conversation transcription and summarization using OpenAI technologies, an important consideration is the storage of clinical notes within the FHIR standard. FHIR provides a structured and standardized approach for exchanging healthcare information, including clinical notes, among different healthcare systems and applications. The Document Reference resource in FHIR serves as a dedicated section for storing clinical notes and related documents.
When integrating transcription and summarization capabilities into the doctor-patient conversation workflow, the resulting transcriptions and summaries can be stored as clinical notes within the FHIR Documents resource. This allows for easy access, retrieval, and sharing of the generated insights among healthcare providers and other authorized entities.
{
"resourceType": "Bundle",
"id": "1a3a6eac-182e-11ee-9901-0242ac170002",
"type": "searchset",
"timestamp": "2023-07-01T16:34:36Z",
"total": 1,
"link": [
{
"relation": "self"&,
"url": "http://localhost:52773/fhir/r4/Patient/1/DocumentReference"
}
],
"entry": [
{
"fullUrl": "http://localhost:52773/fhir/r4/DocumentReference/1921",
"resource": {
"resourceType": "DocumentReference",
"author": [
{
"reference": "Practitioner/3"
}
],
"subject": {
"reference": "Patient/1"
},
"status": "current",
"content": [
{
"attachment": {
"contentType": "application/json",
"data": ""
}
}
],
"id": "1921",
"meta": {
"lastUpdated": "2023-07-01T16:34:33Z",
"versionId": "1"
}
},
"search": {
"mode": "match"
}
}
]
}Try it out
- Clone the Project - Clone the project repository from the following GitHub link: https://github.com/ikram-shah/iris-fhir-transcribe-summarize-export.
- Setup Locally - Follow the provided instructions to set up the project locally on your machine. Let us know if you face any issues during set up.
- Select a Patient - Choose a patient from the provided sample list within the project. This patient will be associated with the doctor-patient conversation for transcription and summarization.
- Interactions Page -Once the patient is selected, navigate to the interactions page within the project. On this page, locate and click on the "Take Notes" option to initiate the transcription process for the doctor-patient conversation.
- View and Edit Transcription - After the transcription process is completed, an option will be presented to view the generated transcription. You can also edit the title and summary associated with the transcription for better organization and clarity.
- Saving to FHIR Document Reference - Upon finalizing the title and summary, saving the changes will automatically store them within the FHIR document reference. This ensures that the relevant clinical notes are captured and associated with the respective patient's record. Currently, the project does not save the entire transcription text. However, it can be modified to include the storage of the complete transcription as well.
Demo
Watch a demo of the overall application here - https://youtu.be/3Th6bR4rw0w
Future Directions
Expanding the application of AI-powered transcription and summarization to telehealth communication holds immense potential. Integrating these capabilities with popular meeting platforms like Zoom, Teams, and Google Meet can streamline remote doctor-patient interactions. Automatic transcription and summarization of telehealth sessions offer benefits such as accurate documentation and enhanced analysis. However, data privacy remains a crucial challenge. To address this, implementing measures to filter or anonymize personally identifiable information (PII) before transmitting data to external servers is essential.
Future directions include exploring on-device AI models for local processing, improved support for multilingual communication, and advancements in privacy-preserving techniques.
If you find this implementation useful, consider voting for this app at Grand Prix 2023.

Top comments (0)