
Introduction
As we've seen in the first part of this series, we managed to adapt our infrastructure and go from 1 user up to 100k.
However, once we cross that number, it's expected to see some shortage and rising issues, and for that, we will need to adjust accordingly. Let's have a look at these failures and how we are going to address that.
Stage III: >100k Users
Issues of "Stage II"
So looking back at the current design that we have, the common three-tier application where everything is scalable and highly resilient. Therefore, going to 100K has created a new issue in our architecture, specifically in the data layer.
Since we're managing manually our installed PostgreSQL database on VMs in the Compute Engine, this becomes an unfriendly scalable solution. As the number of users grows, the number of concurrent users grows at the same time, and so the number of concurrent reads and writes to our VMs will do as well.
There are a couple of ways to improve this. One, maybe we can increase the disk on our current VM which will increase IOPS.
Two, we can add another re-replica that we mentioned in Part 1, but this is a lot of overhead. We need to install VMs, manage the VMs, and manage the PostgreSQL databases correspondingly. So we want to take it as a Cloud approach as possible, and thus, we can offload our database loading using Redis cache for example.
Now, let's get back to our database and storage issue. As you may know, there are actually a variety of database and storage services in GCP and AWS that you can adapt based on your use cases and scenarios. Let's have a look at the following capture.
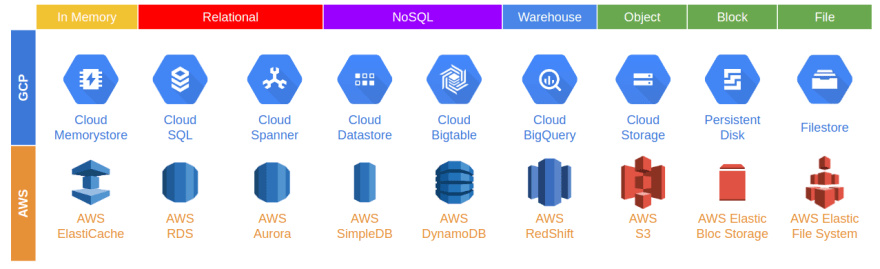
For database options, for instance, we have a choice of Relational DB, NoSQL DB, and the Warehouse as well. If we have a typical transaction to process, the Relational database will be a good choice for us. Here, in our case, we will focus on the in-memory database and the Relational database as we need to at this stage.
Let's have a look again at our data layer in our current architecture under AWS as an example.
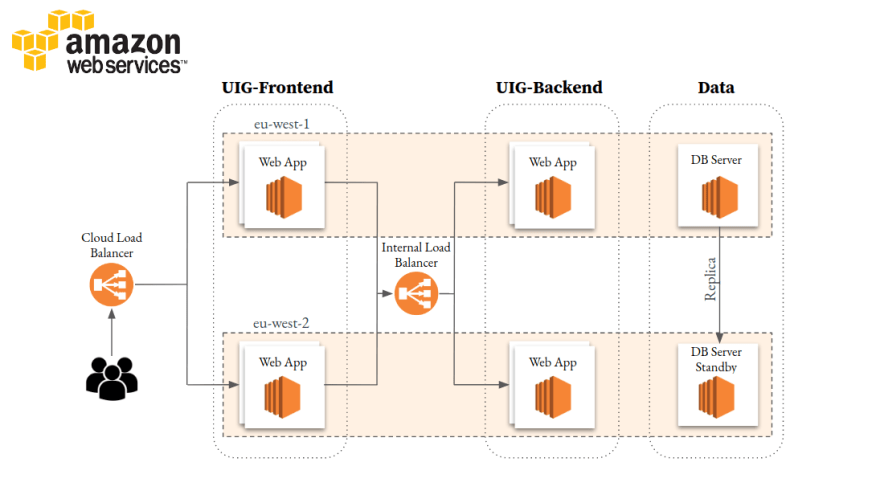
Looking at the current design, as we are running PostgreSQL on EC2, we know that database engines are a fast-evolving technology, and thus, new updates being released frequently so that we need to update the software appropriately. In the meantime, as our users grow, the disk of the database grows as well. So there is no easy way for us to extend the disk space for our database, and there is no managed re-replica to separate the read and write operations which can help us reduce the overhead of the master database.
GCP Cloud SQL & AWS RDS
With a managed service like Cloud SQL and RDS, we can smoothly upgrade our database in the maintenance window that we specified. When we need to extend our database disk, a managed service can increase the disk when it's running out. We can even define the threshold that we want to trigger an automatic increase mechanism. And this disk increase operation doesn't affect our data at all, and even we don't need to stop the service as it can be done on the fly.
In addition to that, a managed service can also periodically create a snapshot of the database so that we can restore it from this managed backup, and also, provide the failover replica and the re-replica to help easily scale the database. So failover replica gives both the re-ability and also high availability.
To sum this up, we can list it as follows:
Current Solution
- Not managed database
- Not easy to extend disk space
- Not scalable
Using Cloud SQL or RDS
- Auto software upgrade
- Easy to extend disk space (vertically scalable)
- Automatic storage increase
- Managed backups
Memorystore for Redis
Memorystore is also an important solution to route the read and write traffic from the database to the cache. Memorystore for Redis is used to handle fast read and write operations. We can keep our frequently accessed data in the cache, like user's session information, game leaderboard metadata, or shopping card items for instance. With this latter, we'll gain both low latency access to data and a significant database offload loading.
Furthermore, we have the ability to increase memory on the fly without stopping the cache services, and we can also provide a standby mode to provide high availability when the primary instance is down or in case of a zone failure.
Now let's see how we can improve the architecture and achieve that on GCP and AWS.


Here as you can see, we have added two types of databases into the solution. We adapt the fully managed Relational database service, to easily create the failover replica and re-replica. Memorystore for Redis is also added between the backend and the data layer. At this stage, the design focuses more on services rather than servers. In doing so, we address the database issues, the scalability, and the high availability with a managed Relational database service and Memorystore.
That's it for Part 2, in the last one, we're going to see the cons of our current design and how we can improve it to scale up to 1M happy users!
Thanks for reading up until here, please feel free to leave a comment or reach me out, and even suggest modifications if possible. I highly appreciate that!





Top comments (1)
Is there a part 3? Would be interested to read further