
A few personal thoughts on why self-supervised learning will have a strong impact on AI. From recent NLP to computer vision papers.
This is not a prediction but rather a summary of personal findings and trends from research and industry.
First, let’s discuss the difference between self-supervised learning and unsupervised learning. Whether there actually is a difference between the two is still an open discussion.
Unsupervised learning is the idea of models learning without any supervision. Clustering algorithms are often an example of unsupervised learning. There is no supervision or training involved on how clusters are formed (at least not for simple methods such as K-Means).
In self-supervised learning, we use the data itself as a label. We essentially turn unsupervised learning into supervised learning by leveraging something called a proxy task. A proxy task is different from the downstream or model task because we are not interested in the proxy itself.
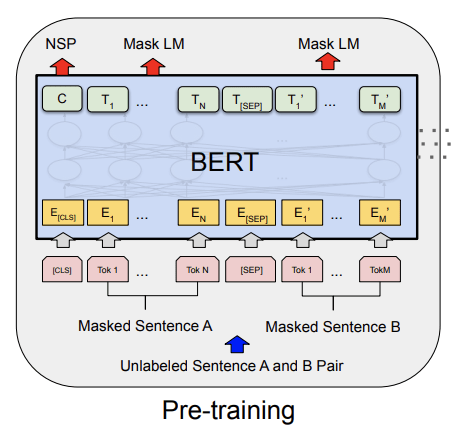
In NLP popular methods such as Googles BERT, 2019 use a pre-training procedure where the model would predict missing words within a sentence or the next sentence based on the current sentence. We can create a sentence with a missing word by simply removing a single word from it. Now the ground truth information (our label) is the missing word. We can train the model in a self-supervised way.
In computer vision, we can apply the very same technique to train a model. We take an image and remove part of it (we essentially color it with a single color). The task of the model is to predict the missing pixels (we call this image inpainting). Since we have access to the original image and the missing pixels (ground truth) we can train the model in a supervised way. The paper Context Encoders: Feature Learning by Inpainting, CVPR, 2016 is an example of such a self-supervised training procedure using inpainting. Unfortunately, this approach in computer vision doesn’t work that well.

Newer methods use image augmentations. A single image would go twice through an augmentation pipeline. We end up with two new versions of the original image (we call them views). If we do the same for multiple images we can train a model to find the pairs which belong to the same original image (before augmentation). We essentially learn the model to be invariant to whatever augmentation we choose.
Now, let’s have a look at the advantages self-supervised learning can bring to the world of AI.
Lifelong Learning
When we talk about AI we all think about some smart system learning over time and improving itself. Unfortunately, this is quite difficult. Supervised learning systems require new labels for new data to be trained on. Improving the systems require continuous re-labeling and re-training.
However, using self-supervision we don’t require human labels anymore. There has been some great work into that direction from Alexey Efros Lab like the following paper using self-supervised learning for adapting to new environments in reinforcement learning: Curiosity-driven Exploration by Self-supervised Prediction, ICML, 2017
Data Labeling
Supervised learning requires ground-truth data. We call them labels or annotations and in domains such as computer vision, they are mostly generated by humans. A single label can cost between a few cents and up to multiple dollars. It all depends on how much time the annotation task takes and how much expertise is required. Whereas lots of people can draw a bounding box around a car and a pedestrian fewer can do the same for medical images.
Self-supervised learning can help to reduce the required amount of labeling. On one hand, we can pre-train a model on unlabeled data and fine-tune it on a smaller labeled set. A popular example is A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020. Btw. the last author of this paper is no one else than Turing Award winner Geoffrey Hinton. Another way to help with labeling efficiency is that we can use the obtained features from a self-supervised model to guide the selection process of which data to label. One approach is to simply pick the data samples which are diverse and not similar. We do this at Lightly.
I hope you got an idea of how self-supervised learning works and why there is a good reason to be excited about it. If you’re interested in self-supervised learning in computer vision don’t forget to check out our open-source Python framework for self-supervised learning on GitHub.
Igor, co-founder
Lightly.ai
This post has originally been published here: https://www.lightly.ai/post/the-advantage-of-self-supervised-learning





Top comments (0)